AWS Certified Data Engineer - Associate (DEA-C01) Questions and Answers
An ecommerce company collects daily customer transaction logs in CSV format and stores the logs in Amazon S3. The company uses Amazon Athena to scan a subset of attributes from the logs on the same day the company receives each log.
Query times are increasing because of increasing transaction volume. The company wants to improve query performance.
Which solution will meet these requirements with the SHORTEST query times?
An ecommerce company stores sales data in an AWS Glue table named sales_data. The company stores the sales_data table in an Amazon S3 Standard bucket. The table contains columns named order_id, customer_id, product_id, order_date, shipping_date, and order_amount.
The company wants to improve query performance by partitioning the sales_data table by order_date. The company needs to add the partition to the existing sales_data table in AWS Glue.
Which solution will meet these requirements?
A data engineer notices slow query performance on a highly partitioned table that is in Amazon Athena. The table contains daily data for the previous 5 years, partitioned by date. The data engineer wants to improve query performance and to automate partition management. Which solution will meet these requirements?
A data engineer uses AWS Lake Formation to manage access to data that is stored in an Amazon S3 bucket. The data engineer configures an AWS Glue crawler to discover data at a specific file location in the bucket, s3://examplepath. The crawler execution fails with the following error:
" The S3 location: s3://examplepath is not registered. "
The data engineer needs to resolve the error.
A company has an Amazon S3–based data lake. The data lake contains datasets that belong to multiple departments. The data lake ingests millions of customer records each day.
A data engineer needs to design an access and storage solution that allows departments to access only the subset of the company’s dataset that each department requires. The solution must follow the principle of least privilege.
Which solution will meet these requirements with the LEAST operational effort?
A global ecommerce company processes customer transactions, inventory updates, and user activity logs across multiple AWS services. The company needs a scalable, fully managed, and event-driven orchestration solution to coordinate complex extract, transform, and load (ETL) workflows. The solution must use AWS Glue and Amazon EMR to process data. The data will be stored in Amazon Redshift and Amazon S3. The solution must support dependency management, automated retries, and data pipeline monitoring.
Which solution will meet these requirements?
A data engineer needs Amazon Athena queries to finish faster. The data engineer notices that all the files the Athena queries use are currently stored in uncompressed .csv format. The data engineer also notices that users perform most queries by selecting a specific column.
Which solution will MOST speed up the Athena query performance?
A company runs an extract, transform, and load (ETL) job in AWS Glue. The job processes personally identifiable information (PII) data and writes logs to an Amazon CloudWatch Logs log group. A data engineer needs to mask PII data in the CloudWatch Logs log group.
Which solution will meet these requirements?
A company uses Amazon Redshift as its data warehouse. Data encoding is applied to the existing tables of the data warehouse. A data engineer discovers that the compression encoding applied to some of the tables is not the best fit for the data. The data engineer needs to improve the data encoding for the tables that have sub-optimal encoding.
Which solution will meet this requirement?
A data engineer needs to run a data transformation job whenever a user adds a file to an Amazon S3 bucket. The job will run for less than 1 minute. The job must send the output through an email message to the data engineer. The data engineer expects users to add one file every hour of the day.
Which solution will meet these requirements in the MOST operationally efficient way?
A company has a data processing pipeline that runs multiple SQL queries in sequence against an Amazon Redshift cluster. After a merger, a query joining two large sales tables becomes slow. Table S1 has 10 billion records, Table S2 has 900 million records.
The query performance must improve.
A company has three subsidiaries. Each subsidiary uses a different data warehousing solution. The first subsidiary hosts its data warehouse in Amazon Redshift. The second subsidiary uses Teradata Vantage on AWS. The third subsidiary uses Google BigQuery.
The company wants to aggregate all the data into a central Amazon S3 data lake. The company wants to use Apache Iceberg as the table format.
A data engineer needs to build a new pipeline to connect to all the data sources, run transformations by using each source engine, join the data, and write the data to Iceberg.
Which solution will meet these requirements with the LEAST operational effort?
A company uses AWS Glue ETL pipelines to process data. The company uses Amazon Athena to analyze data in an Amazon S3 bucket.
To better understand shipping timelines, the company decides to collect and store shipping dates and delivery dates in addition to order data. The company adds a data quality check to ensure that the shipping date is later than the order date and that the delivery date is later than the shipping date. Orders that fail the quality check must be stored in a second Amazon S3 bucket.
Which solution will meet these requirements in the MOST cost-effective way?
A company has a data lake in Amazon 53. The company uses AWS Glue to catalog data and AWS Glue Studio to implement data extract, transform, and load (ETL) pipelines.
The company needs to ensure that data quality issues are checked every time the pipelines run. A data engineer must enhance the existing pipelines to evaluate data quality rules based on predefined thresholds.
Which solution will meet these requirements with the LEAST implementation effort?
A banking company uses an application to collect large volumes of transactional data. The company uses Amazon Kinesis Data Streams for real-time analytics. The company ' s application uses the PutRecord action to send data to Kinesis Data Streams.
A data engineer has observed network outages during certain times of day. The data engineer wants to configure exactly-once delivery for the entire processing pipeline.
Which solution will meet this requirement?
A company uses an on-premises Microsoft SQL Server database to store financial transaction data. The company migrates the transaction data from the on-premises database to AWS at the end of each month. The company has noticed that the cost to migrate data from the on-premises database to an Amazon RDS for SQL Server database has increased recently.
The company requires a cost-effective solution to migrate the data to AWS. The solution must cause minimal downtown for the applications that access the database.
Which AWS service should the company use to meet these requirements?
A media company wants to improve a system that recommends media content to customer based on user behavior and preferences. To improve the recommendation system, the company needs to incorporate insights from third-party datasets into the company ' s existing analytics platform.
The company wants to minimize the effort and time required to incorporate third-party datasets.
Which solution will meet these requirements with the LEAST operational overhead?
A global finance company needs to implement near real-time cross-Region synchronization of trading data between trading centers in the us-east-1 Region, the eu-west-2 Region, and the ap-northeast-1 Region. The company must ensure that data is encrypted in transit. The solution must ensure data ordering and consistency and must support cross-Region disaster recovery. The solution must provide data latency of less than 500 milliseconds.
Which solution will meet these requirements with the LEAST operational effort?
A company hosts its applications on Amazon EC2 instances. The company must use SSL/TLS connections that encrypt data in transit to communicate securely with AWS infrastructure that is managed by a customer.
A data engineer needs to implement a solution to simplify the generation, distribution, and rotation of digital certificates. The solution must automatically renew and deploy SSL/TLS certificates.
Which solution will meet these requirements with the LEAST operational overhead?
A company receives a data file from a partner each day in an Amazon S3 bucket. The company uses a daily AW5 Glue extract, transform, and load (ETL) pipeline to clean and transform each data file. The output of the ETL pipeline is written to a CSV file named Dairy.csv in a second 53 bucket.
Occasionally, the daily data file is empty or is missing values for required fields. When the file is missing data, the company can use the previous day ' s CSV file.
A data engineer needs to ensure that the previous day ' s data file is overwritten only if the new daily file is complete and valid.
Which solution will meet these requirements with the LEAST effort?
A company uses Amazon Redshift for its data warehouse. A data engineer must query a table named orders.complete_orders_history, which contains 100 columns. The query must return all columns except columns named company_id and unique_system_id.
Which Amazon Redshift SQL statement will meet this requirement?
A company is uploading log files from on-premises servers to an Amazon S3 bucket. The company needs to validate that the logs from the on-premises servers are the same as the logs that are stored in the S3 bucket.
Which solution will meet this requirement?
A company needs to store semi-structured transactional data for an application in a database. The database must be serverless. The application writes the data infrequently, but it reads the data frequently. The application must retrieve the data within milliseconds.
Which solution will meet these requirements with the LEAST operational overhead?
A company currently stores all of its data in Amazon S3 by using the S3 Standard storage class.
A data engineer examined data access patterns to identify trends. During the first 6 months, most data files are accessed several times each day. Between 6 months and 2 years, most data files are accessed once or twice each month. After 2 years, data files are accessed only once or twice each year.
The data engineer needs to use an S3 Lifecycle policy to develop new data storage rules. The new storage solution must continue to provide high availability.
Which solution will meet these requirements in the MOST cost-effective way?
A company stores customer data in an Amazon S3 bucket. The company must permanently delete all customer data that is older than 7 years.
A company’s data processing pipeline uses AWS Glue jobs and AWS Glue Data Catalog. All AWS Glue jobs must run in a custom VPC inside a private subnet. The company uses a NAT gateway to support outbound connections.
A data engineer needs to use AWS Glue to migrate data from an on-premises PostgreSQL database to Amazon S3. There is no current network connection between AWS and the on-premises environment. However, the data engineer has updated the on-premises database to allow traffic from the custom VPC.
Which solution will meet these requirements?
A data engineer is troubleshooting an AWS Glue workflow that occasionally fails. The engineer determines that the failures are a result of data quality issues. A business reporting team needs to receive an email notification any time the workflow fails in the future.
Which solution will meet this requirement?
A company is building a new application that ingests CSV files into Amazon Redshift. The company has developed the frontend for the application.
The files are stored in an Amazon S3 bucket. Files are no larger than 5 MB.
A data engineer is developing the extract, transform, and load (ETL) pipeline for the CSV files. The data engineer configured a Redshift cluster and an AWS Lambda function that copies the data out of the files into the Redshift cluster.
Which additional steps should the data engineer perform to meet these requirements?
A company has a data pipeline that uses an Amazon RDS instance, AWS Glue jobs, and an Amazon S3 bucket. The RDS instance and AWS Glue jobs run in a private subnet of a VPC and in the same security group.
A use ' made a change to the security group that prevents the AWS Glue jobs from connecting to the RDS instance. After the change, the security group contains a single rule that allows inbound SSH traffic from a specific IP address.
The company must resolve the connectivity issue.
Which solution will meet this requirement?
A company uses Amazon S3 as a data lake. The company sets up a data warehouse by using a multi-node Amazon Redshift cluster. The company organizes the data files in the data lake based on the data source of each data file.
The company loads all the data files into one table in the Redshift cluster by using a separate COPY command for each data file location. This approach takes a long time to load all the data files into the table. The company must increase the speed of the data ingestion. The company does not want to increase the cost of the process.
Which solution will meet these requirements?
A company creates a new non-production application that runs on an Amazon EC2 instance. The application needs to communicate with an Amazon RDS database instance using Java Database Connectivity (JDBC). The EC2 instances and the RDS database instance are in the same subnet.
Which solution will meet this requirement?
A company uses Amazon Redshift for its data warehouse. The company must automate refresh schedules for Amazon Redshift materialized views.
Which solution will meet this requirement with the LEAST effort?
A data engineer is building an automated extract, transform, and load (ETL) ingestion pipeline by using AWS Glue. The pipeline ingests compressed files that are in an Amazon S3 bucket. The ingestion pipeline must support incremental data processing.
Which AWS Glue feature should the data engineer use to meet this requirement?
A data engineer is building a serverless, multi-step extract, transform, and load (ETL) pipeline. The pipeline extracts data from an Amazon S3 data lake and transforms the data by using AWS Glue ETL jobs. The pipeline then loads the results into an Amazon Redshift database. The data engineer needs to orchestrate the serverless ETL workflow.
Which solutions will meet these requirements? (Select TWO.)
A company uses Amazon S3 to store data and Amazon QuickSight to create visualizations.
The company has an S3 bucket in an AWS account named Hub-Account. The S3 bucket is encrypted with an AWS Key Management Service (AWS KMS) key. The company’s Amazon QuickSight instance is in a separate AWS account named BI-Account.
The company updates the S3 bucket policy to grant access to the QuickSight service role. The company wants to enable cross-account access to allow QuickSight to interact with the S3 bucket.
Which combination of steps will meet this requirement? (Select TWO)
A company stores its processed data in an S3 bucket. The company has a strict data access policy. The company uses IAM roles to grant teams within the company different levels of access to the S3 bucket.
The company wants to receive notifications when a user violates the data access policy. Each notification must include the username of the user who violated the policy.
Which solution will meet these requirements?
A company uses AWS Step Functions to orchestrate a data pipeline. The pipeline consists of Amazon EMR jobs that ingest data from data sources and store the data in an Amazon S3 bucket. The pipeline also includes EMR jobs that load the data to Amazon Redshift.
The company ' s cloud infrastructure team manually built a Step Functions state machine. The cloud infrastructure team launched an EMR cluster into a VPC to support the EMR jobs. However, the deployed Step Functions state machine is not able to run the EMR jobs.
Which combination of steps should the company take to identify the reason the Step Functions state machine is not able to run the EMR jobs? (Choose two.)
A data engineer is using an Apache Iceberg framework to build a data lake that contains 100 TB of data. The data engineer wants to run AWS Glue Apache Spark Jobs that use the Iceberg framework.
What combination of steps will meet these requirements? (Select TWO.)
A company receives marketing campaign data from a vendor. The company ingests the data into an Amazon S3 bucket every 40 to 60 minutes. The data is in CSV format. File sizes are between 100 KB and 300 KB.
A data engineer needs to set-up an extract, transform, and load (ETL) pipeline to upload the content of each file to Amazon Redshift.
Which solution will meet these requirements with the LEAST operational overhead?
A company is developing an application that runs on Amazon EC2 instances. Currently, the data that the application generates is temporary. However, the company needs to persist the data, even if the EC2 instances are terminated.
A data engineer must launch new EC2 instances from an Amazon Machine Image (AMI) and configure the instances to preserve the data.
Which solution will meet this requirement?
A company needs to partition the Amazon S3 storage that the company uses for a data lake. The partitioning will use a path of the S3 object keys in the following format: s3://bucket/prefix/year=2023/month=01/day=01.
A data engineer must ensure that the AWS Glue Data Catalog synchronizes with the S3 storage when the company adds new partitions to the bucket.
Which solution will meet these requirements with the LEAST latency?
A company wants to analyze sales records that the company stores in a MySQL database. The company wants to correlate the records with sales opportunities identified by Salesforce.
The company receives 2 GB erf sales records every day. The company has 100 GB of identified sales opportunities. A data engineer needs to develop a process that will analyze and correlate sales records and sales opportunities. The process must run once each night.
Which solution will meet these requirements with the LEAST operational overhead?
A car sales company maintains data about cars that are listed for sale in an area. The company receives data about new car listings from vendors who upload the data daily as compressed files into Amazon S3. The compressed files are up to 5 KB in size. The company wants to see the most up-to-date listings as soon as the data is uploaded to Amazon S3.
A data engineer must automate and orchestrate the data processing workflow of the listings to feed a dashboard. The data engineer must also provide the ability to perform one-time queries and analytical reporting. The query solution must be scalable.
Which solution will meet these requirements MOST cost-effectively?
A data engineer needs to build an enterprise data catalog based on the company ' s Amazon S3 buckets and Amazon RDS databases. The data catalog must include storage format metadata for the data in the catalog.
Which solution will meet these requirements with the LEAST effort?
A data engineer must use AWS services to ingest a dataset into an Amazon S3 data lake. The data engineer profiles the dataset and discovers that the dataset contains personally identifiable information (PII). The data engineer must implement a solution to profile the dataset and obfuscate the PII.
Which solution will meet this requirement with the LEAST operational effort?
A company is setting up a data pipeline in AWS. The pipeline extracts client data from Amazon S3 buckets, performs quality checks, and transforms the data. The pipeline stores the processed data in a relational database. The company will use the processed data for future queries.
Which solution will meet these requirements MOST cost-effectively?
A company runs concurrent analytical queries on Amazon Redshift tables multiple times each day. The queries require consistent data views three times each day. The company runs extract, transform, and load (ETL) operations that update dimension tables while the queries run. The company has noticed that the queries cause table-level locks during the ETL operations. The company ' s current solution experiences query timeouts and deadlocks during peak processing hours, which affects analytical reporting and on-demand analysis.
Which solution will fix this issue?
A media company uploads large video files to Amazon S3 for processing. After processing, the company needs to keep the original files for 90 days in case the files require reprocessing. After 90 days, the company can delete the files to reduce storage costs. The company stores the processed videos in a different S3 bucket.
Which S3 Lifecycle configuration will meet these requirements for the original files MOST cost-effectively?
A data engineer is using an AWS Glue ETL job to remove outdated customer records from a table that contains customer account information. The data engineer is using the following SQL command:
MERGE INTO accounts t USING monthly_accounts_update s
ON t.customer = s.customer
WHEN MATCHED THEN DELETE
What will happen when the data engineer runs the SQL command?
A company stores Apache Parquet files in an Amazon S3 data lake. The data lake receives thousands of files from multiple sources every hour. The files range in size from 50 KB to 100 KB.
The company is evaluating the implementation of Apache Iceberg tables for the data lake. The company is using AWS Glue Data Catalog as part of the evaluation. The company needs a solution to optimize query performance in Iceberg. The solution must ensure that Iceberg table performance does not degrade when more files are added over time.
Which solution will meet these requirements?
A data engineer needs to use AWS Step Functions to design an orchestration workflow. The workflow must parallel process a large collection of data files and apply a specific transformation to each file.
Which Step Functions state should the data engineer use to meet these requirements?
A company needs to build an extract, transform, and load (ETL) pipeline that has separate stages for batch data ingestion, transformation, and storage. The pipeline must store the transformed data in an Amazon S3 bucket. Each stage must automatically retry failures. The pipeline must provide visibility into the success or failure of individual stages.
Which solution will meet these requirements with the LEAST operational overhead?
A company receives call logs as Amazon S3 objects that contain sensitive customer information. The company must protect the S3 objects by using encryption. The company must also use encryption keys that only specific employees can use.
Which solution will meet these requirements with the LEAST effort?
A company that operates globally must follow regulations that require data from an AWS Region to be accessible only within that Region.
A data engineer is creating a data pipeline that will create resources in the Region where the data engineer works. The data pipeline should have access to data only from the Region where the data engineer works. The pipeline uses Active Directory as an identity and authentication system. The pipeline uses a custom identity broker application to verify that employees are signed in to Active Directory and to obtain temporary credentials by using the AssumeRole API operation.
Which solution will meet the locality requirements with the LEAST administrative effort?
A data engineer configures a large number of AWS Glue jobs that all start up around the same time. All the jobs run for less than 1 hour in the same subnet of the same VPC. All the AWS Glue jobs run on a G.1X worker type.
Some of the jobs occasionally fail with the following error: “The specified subnet does not have enough free addresses to satisfy the request.”
What is the likely root cause of the error?
A company is using Amazon S3 to build a data lake. The company needs to replicate records from multiple source databases into Apache Parquet format.
Most of the source databases are hosted on Amazon RDS. However, one source database is an on-premises Microsoft SQL Server Enterprise instance. The company needs to implement a solution to replicate existing data from all source databases and all future changes to the target S3 data lake.
Which solution will meet these requirements MOST cost-effectively?
A data engineer runs Amazon Athena queries on data that is in an Amazon S3 bucket. The Athena queries use AWS Glue Data Catalog as a metadata table.
The data engineer notices that the Athena query plans are experiencing a performance bottleneck. The data engineer determines that the cause of the performance bottleneck is the large number of partitions that are in the S3 bucket. The data engineer must resolve the performance bottleneck and reduce Athena query planning time.
Which solutions will meet these requirements? (Choose two.)
A company uses an Amazon S3 bucket to integrate multiple data sources into a central data lake. The company needs to perform multiple transformations and data cleaning processes on the data to make the data accessible to business partners.
The company needs a solution that will give multiple business partners the ability to run SQL queries on the central data lake during normal business hours.
Which solution will meet these requirements MOST cost-effectively?
A company stores customer data that contains personally identifiable information (PII) in an Amazon Redshift cluster. The company ' s marketing, claims, and analytics teams need to be able to access the customer data.
The marketing team should have access to obfuscated claim information but should have full access to customer contact information.
The claims team should have access to customer information for each claim that the team processes.
The analytics team should have access only to obfuscated PII data.
Which solution will enforce these data access requirements with the LEAST administrative overhead?
A company stores time-series data that is collected from streaming services in an Amazon S3 bucket. The company must ensure that only workloads that are deployed within the company ' s VPC can access the data.
Which solution will meet this requirement?
A company runs an AWS Glue workflow every day to process time series data from an Amazon S3 bucket. The workflow loads the data into an Amazon Redshift Serverless table. The company observes that some of the jobs in the workflow occasionally fail.
A data engineer must receive a notification when the Redshift table does not contain the most recent data.
Which solution will meet this requirement in the MOST operationally efficient way?
A company uses Amazon Redshift to store order transactions from the current day. The company has an orders table that contains the previous order data. The company also has a staging table that contains new or updated order records. The company needs to remove stale records from the orders table and insert the most recent data in the orders table from the staging table. Several downstream applications need the orders table to display up-to-date information.
Which solution will meet these requirements?
A company processes 500 GB of audience and advertising data daily, storing CSV files in Amazon S3 with schemas registered in AWS Glue Data Catalog. They need to convert these files to Apache Parquet format and store them in an S3 bucket.
The solution requires a long-running workflow with 15 GiB memory capacity to process the data concurrently, followed by a correlation process that begins only after the first two processes complete.
A company generates reports from 30 tables in an Amazon Redshift data warehouse. The data source is an operational Amazon Aurora MySQL database that contains 100 tables. Currently, the company refreshes all data from Aurora to Redshift every hour, which causes delays in report generation.
Which combination of steps will meet these requirements with the LEAST operational overhead? (Select TWO.)
An ecommerce company wants to use AWS to migrate data pipelines from an on-premises environment into the AWS Cloud. The company currently uses a third-party too in the on-premises environment to orchestrate data ingestion processes.
The company wants a migration solution that does not require the company to manage servers. The solution must be able to orchestrate Python and Bash scripts. The solution must not require the company to refactor any code.
Which solution will meet these requirements with the LEAST operational overhead?
Two developers are working on separate application releases. The developers have created feature branches named Branch A and Branch B by using a GitHub repository ' s master branch as the source.
The developer for Branch A deployed code to the production system. The code for Branch B will merge into a master branch in the following week ' s scheduled application release.
Which command should the developer for Branch B run before the developer raises a pull request to the master branch?
A university is developing an educational application that analyzes student essays. The application provides personalized feedback with accurate citations to the university ' s textbooks. The application needs to process essays in multiple languages. Application responses must include direct references to specific sections in the course materials and must be in the student ' s selected language.
Which solution will meet these requirements with the LEAST operational overhead?
A company uses Amazon Redshift as a data warehouse solution. One of the datasets that the company stores in Amazon Redshift contains data for a vendor.
Recently, the vendor asked the company to transfer the vendor ' s data into the vendor ' s Amazon S3 bucket once each week.
Which solution will meet this requirement?
A company has five offices in different AWS Regions. Each office has its own human resources (HR) department that uses a unique IAM role. The company stores employee records in a data lake that is based on Amazon S3 storage.
A data engineering team needs to limit access to the records. Each HR department should be able to access records for only employees who are within the HR department ' s Region.
Which combination of steps should the data engineering team take to meet this requirement with the LEAST operational overhead? (Choose two.)
A company runs multiple applications on AWS. The company configured each application to output logs. The company wants to query and visualize the application logs in near real time.
Which solution will meet these requirements?
A data engineer is implementing model governance for machine learning (ML) workflows on AWS. The data engineer needs a solution that can track the complete lifecycle of the ML models, including data preparation, model training, and deployment stages. The solution must ensure reproducibility and audit compliance.
A company wants to migrate data from an Amazon RDS for PostgreSQL DB instance in the eu-east-1 Region of an AWS account named Account_A. The company will migrate the data to an Amazon Redshift cluster in the eu-west-1 Region of an AWS account named Account_B.
Which solution will give AWS Database Migration Service (AWS DMS) the ability to replicate data between two data stores?
A gaming company uses Amazon Kinesis Data Streams to collect clickstream data. The company uses Amazon Kinesis Data Firehose delivery streams to store the data in JSON format in Amazon S3. Data scientists at the company use Amazon Athena to query the most recent data to obtain business insights.
The company wants to reduce Athena costs but does not want to recreate the data pipeline.
Which solution will meet these requirements with the LEAST management effort?
A data engineer has two datasets that contain sales information for multiple cities and states. One dataset is named reference, and the other dataset is named primary.
The data engineer needs a solution to determine whether a specific set of values in the city and state columns of the primary dataset exactly match the same specific values in the reference dataset. The data engineer wants to use Data Quality Definition Language (DQDL) rules in an AWS Glue Data Quality job.
Which rule will meet these requirements?
A company wants to use Apache Spark jobs that run on an Amazon EMR cluster to process streaming data. The Spark jobs will transform and store the data in an Amazon S3 bucket. The company will use Amazon Athena to perform analysis.
The company needs to optimize the data format for analytical queries.
Which solutions will meet these requirements with the SHORTEST query times? (Select TWO.)
A company uses Amazon Redshift as its data warehouse service. A data engineer needs to design a physical data model.
The data engineer encounters a de-normalized table that is growing in size. The table does not have a suitable column to use as the distribution key.
Which distribution style should the data engineer use to meet these requirements with the LEAST maintenance overhead?
A company wants to migrate an application and an on-premises Apache Kafka server to AWS. The application processes incremental updates that an on-premises Oracle database sends to the Kafka server. The company wants to use the replatform migration strategy instead of the refactor strategy.
Which solution will meet these requirements with the LEAST management overhead?
A company is migrating its database servers from Amazon EC2 instances that run Microsoft SQL Server to Amazon RDS for Microsoft SQL Server DB instances. The company ' s analytics team must export large data elements every day until the migration is complete. The data elements are the result of SQL joins across multiple tables. The data must be in Apache Parquet format. The analytics team must store the data in Amazon S3.
Which solution will meet these requirements in the MOST operationally efficient way?
A company has a data warehouse in Amazon Redshift. To comply with security regulations, the company needs to log and store all user activities and connection activities for the data warehouse.
Which solution will meet these requirements?
A financial services company stores financial data in Amazon Redshift. A data engineer wants to run real-time queries on the financial data to support a web-based trading application. The data engineer wants to run the queries from within the trading application.
Which solution will meet these requirements with the LEAST operational overhead?
A company is planning to migrate on-premises Apache Hadoop clusters to Amazon EMR. The company also needs to migrate a data catalog into a persistent storage solution.
The company currently stores the data catalog in an on-premises Apache Hive metastore on the Hadoop clusters. The company requires a serverless solution to migrate the data catalog.
Which solution will meet these requirements MOST cost-effectively?
A company uses Amazon Athena to run SQL queries for extract, transform, and load (ETL) tasks by using Create Table As Select (CTAS). The company must use Apache Spark instead of SQL to generate analytics.
Which solution will give the company the ability to use Spark to access Athena?
A manufacturing company uses AWS Glue jobs to process IoT sensor data to generate predictive maintenance models. A data engineer needs to implement automated data quality checks to identify temperature readings that are outside the expected range of -50°C to 150°C. The data quality checks must also identify records that are missing timestamp values.
The data engineer needs a solution that requires minimal coding and can automatically flag the specified issues.
Which solution will meet these requirements?
A retail company stores order information in an Amazon Aurora table named Orders. The company needs to create operational reports from the Orders table with minimal latency. The Orders table contains billions of rows, and over 100,000 transactions can occur each second.
A marketing team needs to join the Orders data with an Amazon Redshift table named Campaigns in the marketing team ' s data warehouse. The operational Aurora database must not be affected.
Which solution will meet these requirements with the LEAST operational effort?
A company wants to build a dimension table in an Amazon S3 bucket. The bucket contains historical data that includes 10 million records. The historical data is 1 TB in size.
A data engineer needs a solution to update changes for up to 10,000 records in the base table every day.
Which solution will meet this requirement with the LOWEST runtime?
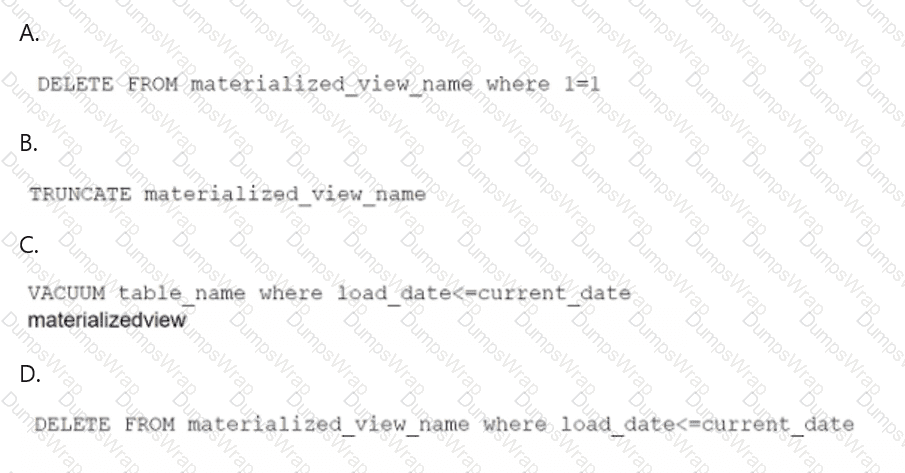
A data engineer maintains a materialized view that is based on an Amazon Redshift database. The view has a column named load_date that stores the date when each row was loaded.
The data engineer needs to reclaim database storage space by deleting all the rows from the materialized view.
Which command will reclaim the MOST database storage space?