CompTIA SecAI+ v1 Exam Questions and Answers
Which of the following is used to train an AI model with unstructured data?
Options:
Statistical learning
Fine-tuning
Supervised learning
Reinforcement training
Answer:
BExplanation:
Basic Concept: Unstructured data such as free-form text, images, and audio does not have predefined labels or rigid schema. Training an AI model effectively on unstructured data requires techniques that can leverage patterns within the data itself or adapt a pre-trained model to new data types. CompTIA SecAI+ covers AI training methodologies under basic AI concepts.
Why B is Correct: Fine-tuning takes a pre-trained foundation model that has already learned rich representations from massive unstructured datasets and further trains it on a specific, potentially smaller unstructured dataset. This adapts the model to a new domain, task, or data type without requiring labeled data for every training example. Fine-tuning is the most practical and effective approach for working with unstructured data in modern AI development.
Why A is Wrong: Statistical learning typically refers to classical machine learning approaches that often assume structured, numerical data with defined features. These methods generally struggle with high-dimensional unstructured data without significant preprocessing.
Why C is Wrong: Supervised learning requires labeled training data where each example has an associated correct output label. Applying supervised learning to unstructured data requires extensive manual labeling, which is the opposite of working with raw unstructured data.
Why D is Wrong: Reinforcement learning trains models through reward signals based on actions taken in an environment. It is designed for sequential decision-making tasks and is not the standard approach for learning representations from unstructured data at scale.
An IT company implements an adaptable chatbot that learns from user prompts. Based on the conversation shown — where User 2 injected false information about a company acquisition that caused the chatbot to give incorrect responses to User 3 — which of the following compensating controls should an administrator implement to mitigate the issue?
Options:
Data encryption
Rate-limiting application programming interfaces (APIs)
Transfer learning
Guardrails
Answer:
DExplanation:
Basic Concept: A chatbot that learns from user prompts is vulnerable to data poisoning through conversational injection. Malicious users can deliberately introduce false information that the chatbot incorporates into its knowledge, corrupting responses for subsequent users. CompTIA SecAI+ Study Guide identifies this as a real-time data poisoning vector requiring guardrail controls.
Why D is Correct: Guardrails prevent the chatbot from accepting and incorporating unverified, irrelevant, or potentially malicious information injected by users. They enforce boundaries on what the chatbot can learn from user interactions, validate that information aligns with the system ' s purpose and known facts, and block outputs based on poisoned knowledge. Guardrails are specifically designed to prevent the type of conversational data poisoning demonstrated where a user ' s false claim corrupted the model ' s subsequent responses.
Why A is Wrong: Data encryption protects the confidentiality of data in transit and at rest. It does not prevent a chatbot from accepting and acting on false information that users deliberately inject into the conversation.
Why B is Wrong: API rate limiting restricts the frequency of requests. While it can limit the number of poisoning attempts a single user can make, it does not prevent the chatbot from learning from and propagating false information when requests are made at an acceptable rate.
Why C is Wrong: Transfer learning is a training technique that adapts knowledge from one domain to another. It is a model development approach, not a runtime control that prevents users from injecting false information into a deployed chatbot.
An architect is using the firm ' s recommended large language model (LLM) to find an internal solution for content management.
Given the following:

Which of the following controls is the best for mitigating this issue?
Options:
Model training
Response validation
Access controls
Integrity monitoring
Answer:
BExplanation:
Basic Concept: LLM hallucinations occur when the model generates plausible-sounding but factually incorrect or fabricated information. For internal content management solutions where accuracy is critical, detecting and handling hallucinated responses before they are acted upon is essential. CompTIA SecAI+ Study Guide covers response validation as a mitigation for hallucination risks.
Why B is Correct: Response validation implements checks that verify the accuracy and relevance of LLM-generated responses before they are presented to users or acted upon. This can involve cross-referencing responses against authoritative internal data sources, using a secondary model to evaluate response accuracy, or implementing confidence scoring that flags low-confidence responses for human review. Response validation directly addresses the hallucination problem by catching inaccurate responses before they cause harm.
Why A is Wrong: Model training addresses hallucinations at the model level by providing more accurate training data or fine-tuning. While effective long-term, it requires significant time and resources and does not provide immediate protection against hallucinations in the currently deployed model.
Why C is Wrong: Access controls manage who can query the LLM and what resources they can access. They do not inspect or validate the accuracy of the model ' s responses, so they cannot mitigate hallucination risks.
Why D is Wrong: Integrity monitoring tracks whether data or systems have been tampered with or changed unexpectedly. It is relevant for detecting unauthorized modifications but does not validate whether LLM-generated content accurately reflects reality or internal authoritative data.
Which of the following requires developers to harden infrastructure to protect AI systems?
Options:
Intake processes
Acceptable use policies
Development guidelines
Configuration standards
Answer:
DExplanation:
Basic Concept: Infrastructure hardening for AI systems involves applying security baseline settings and eliminating unnecessary attack surfaces. CompTIA SecAI+ Exam Objectives identify configuration standards as the specific governance instrument that mandates infrastructure hardening requirements for AI deployments.
Why D is Correct: Configuration standards are formal, technical documents specifying exact security settings, baseline configurations, and hardening requirements that developers and administrators must implement to protect systems including AI infrastructure. They establish enforceable rules such as disabling unnecessary services, applying least-privilege access, and enforcing secure communication protocols specifically for AI systems.
Why A is Wrong: Intake processes govern how new projects, systems, or requests are evaluated and onboarded into an organization. They are procedural checkpoints for initial assessment, not technical hardening directives for developers.
Why B is Wrong: Acceptable use policies define appropriate ways employees and users may use organizational systems and AI tools. They are behavioral guidelines aimed at end users, not technical requirements instructing developers to secure infrastructure.
Why C is Wrong: Development guidelines provide best practices and recommendations for software development and may include security considerations. However, they are advisory in nature and broader in scope than the specific mandatory infrastructure-hardening requirements found in configuration standards.
Which of the following ensures the integrity of data usage in an AI system?
Options:
Data masking
Data cleansing
Data verification
Data lineage
Answer:
DExplanation:
Basic Concept: Data integrity in AI systems requires not only that data is accurate at a point in time, but that its entire history of transformation and usage can be traced and verified. Tracking how data has been used and transformed throughout the AI system lifecycle provides ongoing integrity assurance. CompTIA SecAI+ Study Guide covers data governance controls including lineage for AI integrity.
Why D is Correct: Data lineage tracks and documents the complete journey of data from its origin through every transformation, processing step, and use within an AI system. By recording what happened to the data, when, by whom, and through which processes, data lineage provides the audit trail needed to ensure data integrity throughout the AI system ' s data usage lifecycle. It enables verification that data has been used as intended and has not been improperly modified at any stage.
Why A is Wrong: Data masking replaces sensitive data values with anonymized equivalents to protect privacy. It is a confidentiality control that modifies data values rather than a mechanism for ensuring or tracking data integrity across the system.
Why B is Wrong: Data cleansing removes or corrects errors, inconsistencies, and noise in datasets to improve data quality. It is a data preparation activity that improves data accuracy at a point in time but does not track data usage or provide ongoing integrity assurance throughout the AI system lifecycle.
Why C is Wrong: Data verification confirms that data meets expected quality standards and validates its accuracy at a specific check point. While important for quality assurance, it provides a point-in-time check rather than continuous tracking of data usage and transformations as data lineage does.
Which of the following controls is the best way to mitigate a denial-of-service (DoS) attack?
Options:
Model guardrails
Rate limiting
End-to-end encryption
Access controls
Answer:
BExplanation:
Basic Concept: DoS attacks overwhelm AI systems by sending excessive requests that exhaust computational resources, memory, or bandwidth, preventing legitimate users from being served. The primary defense against volume-based attacks is throttling the rate at which requests can be processed. CompTIA SecAI+ Exam Objectives identify rate limiting as the key DoS mitigation control for AI systems.
Why B is Correct: Rate limiting directly addresses the root mechanism of DoS attacks by restricting the number of requests any single client or IP address can submit within a defined time window. By enforcing request quotas, rate limiting prevents attackers from generating the request volume necessary to overwhelm the system while preserving capacity for legitimate users. It is the most direct and effective preventive control against DoS attacks on AI APIs and services.
Why A is Wrong: Model guardrails inspect and filter the content of prompts and responses for policy compliance and safety. They operate at the semantic content level, not at the request volume level, and cannot prevent resource exhaustion from high-volume request flooding.
Why C is Wrong: End-to-end encryption protects the confidentiality and integrity of data in transit. Encrypted DoS traffic is just as damaging as unencrypted traffic; encryption does not limit request rates or prevent resource exhaustion.
Why D is Wrong: Access controls restrict who can interact with the system, which can reduce the potential attacker pool. However, authenticated users and compromised accounts can still launch DoS attacks, and access controls alone cannot prevent high-volume attacks from authorized sources.
A security analyst is aware of an active penetration test in the environment. The analyst examines SIEM log data and notices the following AI system output:
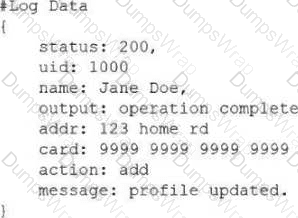
Which of the following is the vulnerability that has occurred and the control the analyst should implement?
Options:
The vulnerability is prompt injection, and the analyst should use endpoint detection response (EDR).
The vulnerability is model hallucinations, and the analyst should develop output validations.
The vulnerability is jailbreaking, and the analyst should utilize role-based access control.
The vulnerability is sensitive information disclosure, and the analyst should employ masking.
The vulnerability is role impersonation, and the analyst should use validation.
Answer:
DExplanation:
Basic Concept: AI systems can inadvertently reveal sensitive information such as PII, credentials, or internal data in their outputs when not properly controlled. Sensitive information disclosure is a critical OWASP LLM Top 10 risk. CompTIA SecAI+ Study Guide covers both vulnerability identification and appropriate data protection controls for AI outputs.
Why D is Correct: The scenario describes the AI system outputting sensitive information in its responses, which is a sensitive information disclosure vulnerability. The appropriate control is masking, which replaces sensitive data values such as credit card numbers, SSNs, or API keys with redacted or tokenized equivalents in the model ' s outputs before they are returned to users. This prevents the AI from disclosing sensitive data while still providing useful responses.
Why A is Wrong: Prompt injection involves crafting inputs to override model instructions. If the penetration test revealed sensitive information, the primary vulnerability is the disclosure of that sensitive data, not the injection mechanism itself. EDR monitors endpoint behavior, not AI output content.
Why B is Wrong: Model hallucinations produce fabricated information rather than disclosing real sensitive data. The described scenario involves actual sensitive information being revealed, not fictitious content generation.
Why C is Wrong: Jailbreaking circumvents safety restrictions but the primary harm demonstrated is sensitive data exposure. RBAC manages access permissions but does not prevent the model from including sensitive data in responses once access is granted.
Why E is Wrong: Role impersonation involves the AI pretending to be a different entity. This may be a secondary technique used by the penetration tester but the primary vulnerability described is the disclosure of actual sensitive information in the output.
A management team is concerned about an unexpected cost increase for a public-facing AI chatbot.
Which of the following should a security administrator examine first to determine the root cause?
Options:
Firewall logs
Web application firewall (WAF) rules
Vector database input/output operations per second performance
Model token usage
Answer:
DExplanation:
Basic Concept: AI chatbot operational costs are primarily driven by token consumption — the number of tokens processed in requests and generated in responses. Unexpected cost increases in LLM-based chatbots almost always trace back to abnormal token usage patterns. CompTIA SecAI+ Study Guide covers AI cost monitoring and token-based billing under securing AI systems.
Why D is Correct: Model token usage logs directly show how many tokens are being consumed per request, by which users or endpoints, and whether usage has increased abnormally. Examining token usage data is the most direct path to identifying the root cause of unexpected cost increases — whether from a denial-of-wallet attack, user abuse, a new feature generating verbose responses, or legitimate organic growth in usage. This is the first and most relevant examination point for LLM cost analysis.
Why A is Wrong: Firewall logs capture network-level traffic information. While they can reveal unusual access patterns or volumes, they do not contain token consumption data that directly explains LLM billing increases.
Why B is Wrong: WAF rules define filtering policies for web traffic. Reviewing rule configurations does not reveal whether token usage has increased or why costs have risen; it shows security policy settings rather than consumption metrics.
Why C is Wrong: Vector database IOPS performance measures how quickly the database processes read and write operations. While relevant to RAG system performance, IOPS metrics do not directly explain LLM API cost increases driven by token consumption.
User experience is declining since the launch of a large language model (LLM) in internal networks.
Which of the following should be the highest priority for the prompt engineers?
Options:
Customer success management
Sales life cycle
Quality control
Business objectives
Answer:
CExplanation:
Basic Concept: Prompt engineers are responsible for designing and refining the prompts and instructions that guide an LLM ' s behavior. When user experience is declining after an LLM launch, this signals that the model ' s outputs are not meeting quality standards. CompTIA SecAI+ addresses prompt engineering quality management under securing and optimizing AI systems.
Why C is Correct: Quality control should be the highest priority when user experience is declining. Prompt engineers must systematically evaluate model responses against quality benchmarks, identify failure patterns causing poor user experience, and iteratively refine prompts to produce accurate, relevant, and appropriately formatted responses. Quality control encompasses testing, evaluation, and continuous improvement of prompt performance.
Why A is Wrong: Customer success management is a business function focused on customer relationship management and retention. While related to user experience outcomes, it is not a technical priority that prompt engineers can directly address through their core competency of prompt design and refinement.
Why B is Wrong: Sales life cycle management is a business process for managing customer acquisition and revenue. It is entirely outside the scope of prompt engineering activities and does not address declining LLM user experience.
Why D is Wrong: Business objectives define what the organization aims to achieve with the LLM deployment. These are set at the strategic level and inform the direction for prompt engineering. They are inputs to the quality control process rather than the priority action prompt engineers should take when experience is declining.
During a model validation procedure, an engineer notices that a model performs well during training but poorly during testing.
Which of the following best describes the reason?
Options:
Fine-tuning
Overfitting
Regularization
Inference
Answer:
BExplanation:
Basic Concept: The gap between training performance and test performance is a classic indicator of a specific model quality problem. Understanding this phenomenon and its causes is fundamental to AI model development. CompTIA SecAI+ Study Guide covers overfitting under basic AI concepts and model quality.
Why B is Correct: Overfitting occurs when a model learns the training data too specifically — memorizing noise, outliers, and specific patterns in the training set rather than learning generalizable underlying patterns. The model achieves high accuracy on training data but fails to generalize to new, unseen test data. This produces exactly the scenario described: excellent training performance combined with poor test performance. Overfitting is the quintessential cause of this training-testing performance gap.
Why A is Wrong: Fine-tuning is a training technique that adapts a pre-trained model to a new task or domain using additional training data. It is a deliberate training process, not a description of why a model ' s performance degrades from training to testing.
Why C is Wrong: Regularization is a training technique specifically used to prevent overfitting by adding penalties to large model weights, encouraging the model to learn simpler, more generalizable patterns. It is the solution to overfitting, not its cause.
Why D is Wrong: Inference is the process of using a trained model to make predictions on new data. It describes the operational use of a model, not a quality characteristic that explains why performance differs between training and testing phases.
Which of the following is the primary security risk when deploying AI models in production?
Options:
Graphics processing unit (GPU) acceleration
Model overfitting
Model encryption
Data exposure
Answer:
DExplanation:
Basic Concept: When AI models are deployed in production, they interact with real data including sensitive business information, personal data, and confidential records. The intersection of AI capabilities and sensitive data creates significant security risks. CompTIA SecAI+ Exam Objectives identify data exposure as the primary production security risk for AI deployments.
Why D is Correct: Data exposure is the primary security risk in production AI deployments. AI models in production process sensitive data through queries and responses, and vulnerabilities such as prompt injection, model inversion attacks, insecure output handling, and misconfigured access controls can expose confidential training data, user PII, proprietary information, or system credentials. The consequences include regulatory violations, legal liability, and reputational damage, making data exposure the most critical ongoing security concern.
Why A is Wrong: GPU acceleration is a performance optimization technique that uses graphics processors for faster AI computation. While hardware security is important, GPU acceleration itself is not a security risk — it is a performance feature that does not inherently expose data.
Why B is Wrong: Model overfitting is a model quality issue where a model performs poorly on new data after memorizing training data too specifically. While it can indirectly contribute to data memorization, it is primarily a performance and generalization concern during development rather than a primary production security risk.
Why C is Wrong: Model encryption is a security control used to protect AI model weights from unauthorized access, not a risk itself. Framing a protection mechanism as a primary risk conflates controls with threats.
A cybersecurity administrator generates patching reports using AI, but the process takes a long time. Which of the following is the best way to increase performance?
Options:
Deploy a Model Context Protocol (MCP) server to delegate several versions of this query to the back-end LLM simultaneously.
Have the AI download the full CVE database first to prevent multiple similar external queries.
Configure the AI system prompt to specify summarization algorithms.
Increase the amount of model tokens available to eliminate time-consuming session restarts.
Answer:
BExplanation:
Basic Concept: AI systems that repeatedly query external data sources for similar information during a single report generation process spend significant time on redundant network requests. Caching frequently accessed data locally eliminates this overhead. CompTIA SecAI+ Study Guide covers AI performance optimization strategies in security operations contexts.
Why B is Correct: Downloading the full CVE database locally before starting the cross-referencing process eliminates the need for multiple individual external API calls as the AI processes each OS version ' s patch list. Instead of making thousands of small external queries to look up CVE information for each patch-OS combination, the AI can query the locally cached database internally. This transforms multiple slow external network operations into fast local lookups, dramatically reducing report generation time.
Why A is Wrong: Using an MCP server to run multiple LLM queries simultaneously could improve throughput through parallelization. However, the fundamental bottleneck is external CVE database queries, not LLM processing capacity. Parallelizing LLM calls does not eliminate the external query latency.
Why C is Wrong: Specifying summarization algorithms in the system prompt affects how the AI structures its output. It does not address the time-consuming external data retrieval process that is the actual performance bottleneck in this cross-referencing workflow.
Why D is Wrong: Increasing token limits prevents session restarts for long contexts but does not address the external query latency that makes the report slow to generate. The bottleneck is data retrieval speed, not token limit constraints causing session breaks.
A cybersecurity analyst must use pattern recognition on a data set containing unstructured data.
Which of the following models is the best for this task?
Options:
Long short-term memory
Convolutional neural network
Decision tree
Logistic regression
Answer:
BExplanation:
Basic Concept: Different ML model architectures are optimized for different data types and tasks. Unstructured data such as images, raw network packet captures, and visual content requires models capable of automatically extracting hierarchical spatial features. CompTIA SecAI+ covers ML model selection for security tasks under basic AI concepts.
Why B is Correct: Convolutional Neural Networks (CNNs) are specifically designed for pattern recognition in unstructured data, particularly image and grid-structured data. CNNs use convolutional layers to automatically extract local and hierarchical features without requiring manual feature engineering. They excel at recognizing patterns in raw, unstructured inputs, making them the optimal choice for pattern recognition on unstructured datasets in cybersecurity contexts such as image-based malware analysis or visual traffic pattern recognition.
Why A is Wrong: Long Short-Term Memory (LSTM) networks are recurrent neural networks optimized for sequential and time-series data such as network traffic flows over time or log sequences. While they handle unstructured sequential data, they are not specifically designed for spatial pattern recognition in general unstructured data.
Why C is Wrong: Decision trees work on structured, tabular data with defined features. They require feature extraction and engineering before processing unstructured data and are not designed for raw pattern recognition in unstructured inputs.
Why D is Wrong: Logistic regression is a linear classification algorithm that requires structured, numerical input features. It cannot directly process unstructured data and requires extensive preprocessing and feature extraction, making it unsuitable for pattern recognition on raw unstructured datasets.
A global security operations center (SOC) wants to adapt and leverage the strength of AI in order to enhance its security operations.
Which of the following is the best way to enhance the global SOC functions?
Options:
Generate code and execute in production to help save time.
Enable a personal assistant that can act in the global SOC with no human intervention.
Use open-source models in production to help the efficiency of threat detection and threat analysis.
Summarize alerts to easily gain insights on the environment.
Answer:
DExplanation:
Basic Concept: AI can augment SOC operations in various ways, but the most appropriate uses maintain human oversight and leverage AI ' s natural language understanding to reduce cognitive load on analysts. CompTIA SecAI+ Study Guide identifies alert summarization as a high-value, low-risk AI application for SOC enhancement.
Why D is Correct: AI-powered alert summarization consolidates complex, high-volume security alerts into concise, actionable insights, helping analysts rapidly understand threats without reading extensive raw log data. This is a safe, bounded AI application that enhances analyst efficiency while preserving human decision-making authority, directly addressing the volume and complexity challenges SOCs face.
Why A is Wrong: Generating and executing code directly in production without human review introduces serious risk. AI-generated code may contain errors, security vulnerabilities, or unintended side effects that could disrupt or compromise production systems.
Why B is Wrong: Enabling an AI assistant to act autonomously with no human intervention violates the human-in-the-loop principle. Autonomous AI in a SOC without oversight could incorrectly contain legitimate systems, miss actual threats, or make consequential decisions without accountability.
Why C is Wrong: Deploying open-source models directly in production without proper vetting, security hardening, and compliance review introduces supply chain risk, model reliability concerns, and potential intellectual property issues into sensitive security operations.
Which of the following provides guidance on AI-specific compliance?
Options:
Organisation for Economic Co-operation and Development (OECD)
International Organization for Standardization (ISO) 27001
Payment Card Industry Data Security Standard (PCI DSS)
General Data Protection Regulation (GDPR)
Answer:
AExplanation:
Basic Concept: Different regulatory and standards bodies address different aspects of technology governance. For AI-specific compliance guidance that addresses the unique characteristics of AI systems including transparency, fairness, accountability, and societal impact, a framework specifically designed for AI is required. CompTIA SecAI+ Study Guide identifies OECD as a key source of AI-specific compliance guidance.
Why A is Correct: The OECD AI Principles and Recommendation on AI provide internationally recognized, AI-specific guidance on compliance with responsible AI values including transparency, accountability, robustness, security, safety, and human-centric values. The OECD has developed a dedicated framework specifically addressing the compliance considerations unique to AI systems across sectors and national boundaries, making it the most AI-specific compliance guidance option listed.
Why B is Wrong: ISO 27001 is a general information security management standard addressing broad organizational security controls. It is not AI-specific and does not address the unique compliance considerations of AI transparency, fairness, or algorithmic accountability.
Why C is Wrong: PCI DSS is a payment card industry security standard focused on protecting payment card data. It has no AI-specific compliance provisions and is limited to financial transaction security requirements.
Why D is Wrong: GDPR is a European data protection regulation focused on personal data privacy rights and obligations. While relevant to AI systems that process personal data, GDPR is a privacy regulation rather than AI-specific compliance guidance addressing the full spectrum of AI governance considerations.
Which of the following responsible AI standards refers to a principle that clearly states the reasons behind the decisions for a particular conclusion?
Options:
Accountability
Auditability
Transparency
Explainability
Answer:
DExplanation:
Basic Concept: Responsible AI encompasses several key principles governing how AI systems should behave to be trustworthy and ethical. These principles are distinct but related. Understanding their precise definitions is essential for CompTIA SecAI+ Domain 4 governance questions.
Why D is Correct: Explainability in responsible AI means the AI system can clearly articulate the specific reasons, factors, and logic that led to a particular decision or output. It answers the question " why did the AI make this specific decision? " For example, an explainable credit scoring AI would not only give a score but also explain which factors such as payment history or credit utilization contributed most to that specific score. This directly matches the question ' s description of " clearly stating reasons behind decisions. "
Why A is Wrong: Accountability refers to the ability to identify who is responsible for AI system decisions and their consequences. It addresses ownership and responsibility assignment rather than explaining the reasoning behind specific decisions.
Why B is Wrong: Auditability refers to the ability to examine and verify an AI system ' s decisions, processes, and outputs through systematic review. It enables after-the-fact verification but does not mean the system itself explains its reasoning.
Why C is Wrong: Transparency refers to openness about how an AI system works at a general level, including its purpose, capabilities, limitations, and the data it was trained on. It is broader than explainability and does not specifically address articulating reasons for individual decisions.
A security team is using an AI-based tool to try to bypass organizational boundaries. The team uses AI to look at the current state and suggest different attack vectors based on the outcome of the previous ones.
Which of the following techniques is the team most likely using?
Options:
Manual signature matching
Code quality testing
Fraud detection
Automated penetration testing
Answer:
DExplanation:
Basic Concept: Modern penetration testing increasingly leverages AI to automate the reconnaissance, exploitation, and pivoting process. AI-assisted automated penetration testing can adapt its strategy based on previous results, simulating intelligent adversary behavior more realistically than static scripts. CompTIA SecAI+ covers AI-assisted offensive security techniques.
Why D is Correct: Automated penetration testing uses AI to systematically discover and attempt to exploit vulnerabilities while adapting tactics based on the results of previous attempts. The described behavior — looking at the current state, suggesting attack vectors, and adjusting based on outcomes — precisely describes an adaptive AI-driven penetration testing tool that iteratively explores the attack surface, mimicking how an advanced persistent threat would operate.
Why A is Wrong: Manual signature matching compares network traffic or files against a database of known threat signatures. It is a passive detection technique used by defensive tools like IDS/IPS, not an adaptive offensive technique for bypassing organizational boundaries.
Why B is Wrong: Code quality testing analyzes source code for bugs, vulnerabilities, and adherence to coding standards. It is a development quality assurance activity, not an offensive security technique for testing organizational security boundaries.
Why C is Wrong: Fraud detection uses ML to identify suspicious patterns in transactions or user behavior for defensive purposes. It is a preventive security measure, not an offensive technique for penetration testing.
Which of the following is the best example of an AI model that is trained to identify multiple points from input using a neural network to provide output for authentication?
Options:
Facial recognition
Encryption key
Open Authorization (OAuth)
Bounding box
Answer:
AExplanation:
Basic Concept: Neural networks can be trained to identify and match complex multi-point patterns in data. For biometric authentication, facial recognition uses deep neural networks to extract and compare dozens to hundreds of facial feature points from an input image. CompTIA SecAI+ covers neural network-based authentication under basic AI concepts.
Why A is Correct: Facial recognition systems use neural networks specifically trained to identify multiple facial landmarks and feature points such as eye distance, nose shape, and jawline contour from input images. These extracted feature vectors are compared against stored templates to authenticate individuals, making this the ideal example of multi-point neural network-based authentication output.
Why B is Wrong: An encryption key is a cryptographic artifact, not an AI model output. Encryption keys are generated mathematically, not through neural network training or multi-point feature identification from biometric inputs.
Why C is Wrong: OAuth is an open authorization protocol framework that handles delegated access and permission grants between services. It is an authentication delegation standard, not an AI model that processes input through neural networks.
Why D is Wrong: A bounding box is an output of object detection models that draws a rectangular box around detected objects in an image. While it uses neural networks, it identifies object location rather than multiple feature points for authentication purposes.
A detection engineering team wants to use AI to automatically prevent vulnerable code from reaching production.
Which of the following is the most effective way to accomplish this task?
Options:
Deploying an integrated development environment (IDE) plug-in that will warn developers of dangerous code before compiling
Using a security orchestration, automation, and response (SOAR) with a machine learning (ML) model to classify code
Implementing a large language model (LLM) in the continuous integration and continuous deployment (CI/CD) runner to examine code and pass or fail build jobs
Developing an agentic penetration testing tool to validate potential vulnerable code
Answer:
CExplanation:
Basic Concept: Preventing vulnerable code from reaching production requires an automated, mandatory gate in the software delivery pipeline. The CI/CD pipeline is the enforcement point where all code must pass before deployment. CompTIA SecAI+ Study Guide covers AI integration in secure development pipelines under AI-assisted security.
Why C is Correct: Implementing an LLM in the CI/CD runner creates a mandatory automated security gate that every code change must pass. The LLM can analyze code for vulnerabilities, insecure patterns, and policy violations, then automatically fail the build if issues are found. This prevents vulnerable code from progressing toward production without human bypass capability, making it the most effective enforcement mechanism.
Why A is Wrong: IDE plug-ins provide warnings to developers during coding, but developers can choose to ignore them and proceed with compilation and commits. Warnings are advisory, not preventive, and cannot guarantee vulnerable code is blocked from the pipeline.
Why B is Wrong: SOAR platforms with ML models are excellent for incident response and security operations automation. However, they are not positioned in the code delivery pipeline and do not gate code from progressing to production.
Why D is Wrong: An agentic penetration testing tool validates vulnerabilities reactively after code is written or deployed. This approach does not intercept code before production deployment and is typically used for post-deployment assessment rather than prevention.
A security analyst reviews a recently released chatbot ' s log and discovers that outputs sometimes include personally identifiable information (PII) from other chatbot users.
Which of the following corrective actions should the security analyst take first to resolve this issue?
Options:
Take the chatbot offline and restore it from a backup.
Disable memory from the chat history for all users.
Ask all users to refrain from using PII with the chatbot.
Require users to label the sensitivity of their requests.
Answer:
BExplanation:
Basic Concept: When a chatbot leaks PII from one user ' s conversation into another user ' s responses, the root cause is cross-user memory contamination — the chatbot is retaining and sharing conversation context across user sessions. Disabling the memory feature stops the active data leakage immediately. CompTIA SecAI+ Study Guide covers session memory management as a privacy control for AI chatbots.
Why B is Correct: Disabling memory from chat history for all users immediately stops the mechanism causing PII leakage between users. If the chatbot retains no cross-session memory, it cannot include information from one user ' s conversation in another user ' s response. This is the most direct, immediate corrective action that eliminates the root cause of the privacy violation without requiring additional user behavior changes or service disruption.
Why A is Wrong: Taking the chatbot offline and restoring from backup is a drastic action appropriate when the issue requires investigating a potential compromise or data breach. For a configuration issue such as cross-user memory sharing, disabling the memory feature is a more targeted and proportionate first response that addresses the root cause directly.
Why C is Wrong: Asking users to refrain from using PII relies on voluntary user behavior change and does not address the technical root cause. Users may not comply, and even if they do, previously stored PII in memory would continue to leak. This is an ineffective first corrective action.
Why D is Wrong: Requiring users to label sensitivity does not stop the chatbot from storing and sharing PII that has already been submitted. Labels inform the system about data sensitivity but do not prevent the memory mechanism from sharing labeled sensitive data across user sessions.
An AI security team must assess the probability of an attack on its new system and the impact associated with such an attack.
Which of the following threat-modeling resources best addresses the threat landscape for machine learning (ML)?
Options:
Common Vulnerabilities and Exposures (CVE) AI working group
MITRE Adversarial Threat Landscape for AI Systems (ATLAS)
Massachusetts Institute of Technology (MIT) risk repository
Open Worldwide Application Security Project (OWASP)
Answer:
BExplanation:
Basic Concept: Assessing attack probability and impact for ML systems requires a resource specifically built to catalog real-world adversarial attacks against AI and ML systems, including documented techniques with associated impact information. CompTIA SecAI+ Exam Objectives identify MITRE ATLAS as the authoritative ML threat landscape resource.
Why B is Correct: MITRE ATLAS is specifically designed as a comprehensive knowledge base of adversarial tactics, techniques, and case studies targeting AI and ML systems. It catalogs real-world attacks with associated probability factors derived from actual incidents and provides impact assessments for various attack types including data poisoning, model evasion, model extraction, and inference attacks. This directly enables the probability and impact assessment the team requires.
Why A is Wrong: The CVE AI working group focuses on identifying and cataloging specific vulnerability instances in AI software components. While useful for vulnerability management, it does not provide the comprehensive threat landscape coverage with probability and impact assessments for ML-specific attack tactics that ATLAS provides.
Why C is Wrong: The MIT risk repository is an academic resource cataloging general AI-related risks. It is research-oriented and does not provide the practitioner-focused, operational attack taxonomy and case study library that MITRE ATLAS offers for ML threat modeling.
Why D is Wrong: OWASP provides application security guidance including the OWASP LLM Top 10. While valuable for LLM-specific risks, OWASP does not provide the comprehensive ML threat landscape coverage or the probability and impact data that MITRE ATLAS offers for assessing the full spectrum of ML attack scenarios.
An automobile manufacturer implements a chatbot to assist with configuration options for customer automobiles. Given a customer ' s prompt, the chatbot gives offensive responses.
Which of the following describes this behavior?
Options:
Model skewing
Model theft
Jailbreaking
Insecure output handling
Answer:
CExplanation:
Basic Concept: AI chatbots are designed with safety guidelines and content policies that prevent them from generating harmful, offensive, or inappropriate content. When users find ways to bypass these restrictions through crafted prompts, they have " jailbroken " the model. CompTIA SecAI+ Study Guide covers jailbreaking as a key AI vulnerability category.
Why C is Correct: Jailbreaking is the process of using cleverly crafted prompts to bypass an AI model ' s built-in safety restrictions, content policies, and behavioral guardrails, causing it to produce outputs it was designed to refuse. The scenario describes a chatbot that was designed for automobile configuration assistance but is producing offensive responses following customer prompts, indicating that customers have successfully prompted the model to bypass its safety constraints and generate prohibited content.
Why A is Wrong: Model skewing refers to attacks or biases that cause a model to favor certain outputs or perspectives systematically over time, often through data manipulation. It describes a gradual distortion of model behavior, not a direct user-prompted bypass of safety restrictions in a single interaction.
Why B is Wrong: Model theft involves extracting or replicating a proprietary model ' s functionality or architecture through repeated queries. It is an intellectual property attack aimed at stealing the model ' s knowledge, not an attack that causes the model to produce offensive content.
Why D is Wrong: Insecure output handling occurs when an application fails to properly validate or sanitize AI-generated outputs before using them in ways that could cause harm such as passing AI output directly to a system command or database query. It describes a developer implementation vulnerability, not the act of a user prompting a model to bypass its safety constraints.
A company is adopting AI and wants to create policies and procedures that include a structure for evaluating, publishing, and approving patterns for AI usage.
Which of the following should the company establish to meet this goal?
Options:
AI center of excellence
AI legal affairs office
AI audit department
AI data science division
Answer:
AExplanation:
Basic Concept: Successful AI adoption at an organizational level requires a centralized governance body that standardizes AI practices, promotes best practices, and ensures consistent, safe, and effective AI deployment across the organization. CompTIA SecAI+ Study Guide covers AI organizational governance structures under Domain 4.
Why A is Correct: An AI Center of Excellence (CoE) is an organizational unit specifically designed to govern, standardize, and advance AI adoption. It develops and publishes policies, creates approved patterns for AI usage, evaluates new AI use cases, provides expert guidance, and maintains governance oversight. The CoE exactly matches the described need for a structure to evaluate, publish, and approve AI usage patterns across the organization.
Why B is Wrong: An AI legal affairs office focuses on legal compliance, intellectual property, and regulatory matters related to AI. While important for legal risk management, it does not fulfill the broader governance mandate of establishing and approving AI usage patterns and best practices across the organization.
Why C is Wrong: An AI audit department conducts post-implementation reviews and compliance assessments of existing AI systems. It is a retrospective and oversight function rather than a proactive body for developing and approving AI usage patterns and policies.
Why D is Wrong: An AI data science division is a technical team focused on building AI models and solutions. It is a development function rather than a governance structure designed to create policies, evaluate AI patterns, and provide cross-organizational oversight of AI adoption.
A security alert triggers an agentic system. An analyst notices the following payload in the logs. The alert includes multiple shell commands that are not typically run as part of any hardening:

Which of the following is the most effective control to implement?
Options:
Adding logic that includes approved strings before running the shell commands
Deprecating model usage and retaining the model with safer parameters
Modifying the application to ignore the SECURITY_UPDATE tag
Using only approved libraries when interacting with agentic systems
Answer:
AExplanation:
Basic Concept: Agentic AI systems that execute shell commands based on model-generated output are vulnerable to prompt injection attacks where malicious actors craft inputs that cause the agent to run unauthorized commands. Input validation using allowlists is a critical defense mechanism. CompTIA SecAI+ Study Guide covers agentic AI security controls.
Why A is Correct: Adding logic that validates shell commands against an approved allowlist before execution is the most direct and effective defense. This ensures only pre-approved, safe commands can be executed regardless of what the agentic system ' s model generates, preventing malicious command injection from reaching the operating system. This principle of allowlist-based input validation is a foundational secure agentic AI control.
Why B is Wrong: Deprecating and retraining the model is a lengthy process that addresses root cause training issues but does not provide immediate protection against ongoing injection attacks in the current deployed system.
Why C is Wrong: Modifying the application to ignore a specific tag merely removes one attack surface while leaving the system vulnerable to other injection vectors. It is not a comprehensive defense.
Why D is Wrong: Using only approved libraries controls which code libraries the agentic system can call, but does not validate or restrict the shell commands generated by the model at runtime based on arbitrary user input.
A security architect performs threat modeling of an AI system. The architect needs to determine which attacks can be performed against the system.
Which of the following actions should the architect take next?
Options:
Leverage a large language model (LLM) to map likely attack paths based on the code base.
Quantify the risk of known vulnerabilities identified in the AI system.
Identify trust boundaries and perform threat modeling with Open Worldwide Application Security Project (OWASP) Top 10.
Analyze MITRE Adversarial Threat Landscape for AI Systems (ATLAS) for tactics, techniques, and procedures (TTPs).
Answer:
DExplanation:
Basic Concept: AI-specific threat modeling requires consulting resources that catalogue adversarial attacks specifically developed for AI and ML systems. General cybersecurity frameworks may miss AI-unique attack vectors such as model inversion, data poisoning, and adversarial examples. CompTIA SecAI+ Study Guide identifies MITRE ATLAS as the authoritative source for AI system TTPs.
Why D is Correct: MITRE ATLAS provides a comprehensive, curated knowledge base of adversarial tactics, techniques, and procedures specifically targeting AI and ML systems, derived from real-world attack case studies. Analyzing ATLAS enables the architect to enumerate realistic AI-specific attacks applicable to the system being threat-modeled, which directly answers the question of which attacks can be performed.
Why A is Wrong: Using an LLM to map attack paths introduces uncertainty and potential hallucination risk. LLMs may generate plausible-sounding but inaccurate attack paths and cannot guarantee comprehensive coverage of AI-specific attack techniques.
Why B is Wrong: Quantifying risk of known vulnerabilities is a risk assessment step that occurs after identifying which attacks are possible. The architect must first identify attack possibilities before quantifying their risk impact.
Why C is Wrong: OWASP Top 10 covers web application vulnerabilities and, in its LLM edition, certain LLM-specific risks. However, MITRE ATLAS provides a more comprehensive and structured catalog of AI and ML-specific adversarial TTPs for systematic threat modeling.
An organization is developing and implementing AI features into a customer service application.
Which of the following practices should the organization put in place before releasing the application for customer trials?
Options:
Data masking and sanitization
External compliance audits
Approved AI vendor lists
Third-party risk management
Answer:
AExplanation:
Basic Concept: Before deploying AI applications that handle customer data in trials, protecting sensitive information through data masking and sanitization is essential. CompTIA SecAI+ Study Guide emphasizes pre-deployment data security controls as a critical step in the AI development lifecycle.
Why A is Correct: Data masking replaces sensitive real customer data with realistic but fictitious equivalents, while sanitization removes harmful or unwanted data elements. Before customer trials, these techniques prevent exposure of real PII or sensitive information, ensure the trial environment cannot leak production data, and protect the organization from privacy regulation violations. This is the most immediately actionable pre-trial security control.
Why B is Wrong: External compliance audits are formal processes typically conducted post-deployment or at planned intervals to verify regulatory compliance. They are not pre-trial security implementations and cannot prevent data exposure in a trial environment.
Why C is Wrong: Approved AI vendor lists are governance artifacts that manage vendor selection risk at the procurement stage. They do not directly protect customer data within an application being prepared for trials.
Why D is Wrong: Third-party risk management addresses risks from external vendors and partners at a strategic level. While important for overall governance, it does not constitute a direct data security control for a pre-trial release.
A cybersecurity administrator needs a security mechanism that can validate input.
Which of the following controls should the administrator use?
Options:
Prompt firewall
Rate limits
Token limits
Input quantity
Answer:
AExplanation:
Basic Concept: Input validation is a fundamental security principle that checks incoming data against expected criteria before processing it. For AI systems, this requires a mechanism capable of inspecting the semantic content and structure of inputs — not just their volume or format. CompTIA SecAI+ Study Guide identifies prompt firewalls as the primary input validation control for AI systems.
Why A is Correct: A prompt firewall validates incoming inputs by inspecting their content against security policies, detecting malicious patterns such as injection strings or jailbreaking attempts, enforcing structural rules, and blocking non-compliant inputs before they reach the AI model. Unlike network firewalls that operate on packet headers, a prompt firewall understands the semantic content of AI prompts, making it the appropriate input validation mechanism for AI systems.
Why B is Wrong: Rate limits control how frequently inputs are submitted, not what those inputs contain. A malicious prompt submitted within rate limits will not be detected or blocked — rate limiting does not validate the content or intent of individual inputs.
Why C is Wrong: Token limits cap the maximum length of inputs and outputs in terms of tokens. While this can prevent excessively long inputs from being processed, it does not inspect input content for malicious patterns or validate that inputs conform to policy requirements.
Why D is Wrong: Input quantity is a generic term that might refer to limiting the number or size of inputs. Like token limits and rate limits, quantity controls do not validate the content of inputs for security compliance or detect malicious prompt patterns.
Which of the following strengthens the performance of a large language model (LLM) for malicious reconnaissance?
Options:
Enhancing a foundational model with the inclusion of retrieval-augmented generation (RAG)
Creating a web scraper script using AI to capture the company website
Instructing an AI assistant to query as an administrator
Prompting a chatbot to describe server naming patterns and Internet Protocol (IP) ranges
Answer:
AExplanation:
Basic Concept: Reconnaissance is the information gathering phase of an attack. LLMs can be enhanced to perform more effective reconnaissance by giving them access to current, specific information beyond their training data cutoff. CompTIA SecAI+ covers AI augmentation techniques including RAG under AI-assisted security.
Why A is Correct: RAG enhances an LLM by connecting it to an external knowledge base or real-time data sources that it can query during inference. For reconnaissance purposes, a RAG-enabled LLM can access up-to-date organizational information, technical documentation, and intelligence feeds that go beyond its static training data. This makes the LLM significantly more capable for gathering current, targeted intelligence about specific organizations or infrastructure.
Why B is Wrong: Creating a web scraper is a basic data collection technique. While AI can help write scraper code, the scraper itself is a simple script that does not enhance the LLM ' s intelligence or reasoning capabilities for sophisticated reconnaissance.
Why C is Wrong: Instructing an AI assistant to query as an administrator is a prompt manipulation attempt. An LLM cannot actually gain elevated permissions through a prompt instruction; this describes social engineering or privilege escalation via prompting, not a performance enhancement technique.
Why D is Wrong: Prompting a chatbot to describe naming patterns is a basic use of an existing LLM ' s knowledge. It does not strengthen or enhance the model ' s capabilities; it merely queries what the model already knows from training data, which may be outdated or generic.
An organization is concerned with the exposure of sensitive data.
Which of the following is the most relevant security concern?
Options:
Overfitting
Model inversion
Data normalization
Hyperparameter tuning
Answer:
BExplanation:
Basic Concept: AI models can inadvertently memorize sensitive information from their training data. Certain attack techniques can exploit this memorization to extract private information from a deployed model, even without direct access to the training dataset. CompTIA SecAI+ Study Guide covers model inversion as an AI-specific data exposure attack vector.
Why B is Correct: Model inversion is an attack where an adversary queries a deployed AI model with carefully crafted inputs to reconstruct or infer sensitive training data. For example, an attacker could query a facial recognition model with optimized images to reconstruct faces of individuals from the training set, or query a medical diagnosis model to infer patient records used in training. This directly exposes sensitive data that was supposed to be protected.
Why A is Wrong: Overfitting is a model training quality issue where a model learns training data too specifically and performs poorly on new data. While it can indicate that sensitive data was memorized, overfitting itself is a performance concern rather than directly a data exposure attack vector.
Why C is Wrong: Data normalization is a preprocessing technique that scales numerical features to a common range to improve training performance. It is a data preparation step with no direct relevance to sensitive data exposure or privacy attacks.
Why D is Wrong: Hyperparameter tuning adjusts configuration parameters of a model to optimize its performance during training. It is an optimization technique with no relevance to protecting against sensitive data exposure attacks.
An attacker successfully completes a denial-of-service (DoS) attack through the context window of an AI system. Thousands of characters are obfuscated and hidden behind an emoji.
Which of the following techniques best mitigates this type of attack?
Options:
Fraud detection
Large language model (LLM)-as-a-judge
Pattern recognition
Prompt filter
Answer:
DExplanation:
Basic Concept: Context window DoS attacks flood an LLM ' s context with obfuscated content to exhaust processing resources or manipulate model behavior. Attackers may hide large amounts of text behind Unicode characters like emojis. CompTIA SecAI+ Study Guide identifies prompt filtering as the primary defense against input-based attacks on LLMs.
Why D is Correct: A prompt filter inspects incoming inputs before they reach the LLM, detecting and blocking malicious content including obfuscated text hidden behind Unicode characters or emojis. By analyzing input structure, character counts, hidden content, and encoding anomalies, prompt filters can identify and reject attacks that attempt to abuse the context window, preventing resource exhaustion.
Why A is Wrong: Fraud detection systems are designed to identify fraudulent transactions or activities in structured data contexts. They are not designed to inspect LLM prompt structures for obfuscated content attacks on context windows.
Why B is Wrong: LLM-as-a-judge uses a secondary LLM to evaluate the quality or safety of another model ' s outputs. It operates post-generation and cannot prevent a DoS attack that occurs during input processing before output is generated.
Why C is Wrong: Pattern recognition can identify known attack patterns but requires the attack to match pre-learned patterns. Novel obfuscation techniques using Unicode or emoji hiding may evade pattern-based detection without dedicated prompt filtering logic.
Which of the following is an example of how a security analyst uses generative AI in the triage process?
Options:
To predict the next attack target with higher accuracy
To use statistical analysis for malicious code assessment
To summarize security findings by category
To tag malware using machine learning (ML) algorithms
Answer:
CExplanation:
Basic Concept: Generative AI produces natural language content based on input data. In a security operations context, triage involves rapidly understanding and prioritizing security events. Generative AI ' s strength lies in synthesizing information and producing readable summaries from complex data. CompTIA SecAI+ Study Guide covers generative AI applications in security operations.
Why C is Correct: Summarizing security findings by category is a natural application of generative AI in triage. The AI can process large volumes of alerts and security events, group them by type or severity, and generate concise natural language summaries that enable analysts to quickly understand the current threat landscape without reading individual alerts. This directly reduces triage time and cognitive load.
Why A is Wrong: Predicting the next attack target requires predictive analytics and threat intelligence correlation. While AI can assist with this, it is a forecasting task better suited to analytical ML models rather than generative AI, and it is a strategic intelligence function rather than a triage task.
Why B is Wrong: Statistical analysis for malicious code assessment uses mathematical and ML techniques to analyze code characteristics. This is a traditional ML classification task, not a generative AI application, and is performed during malware analysis rather than alert triage.
Why D is Wrong: Tagging malware using ML algorithms is a classification task that uses supervised ML models trained on malware features. It is a detection and classification function, not a generative AI triage application.
During an update, an AI system flags some potential compatibility issues and provides recommendations. An administrator reviews the recommendations before addressing the issues.
Which of the following processes describes this scenario?
Options:
Data validation
Data preparation
Human-in-the-loop
Model evaluation
Answer:
CExplanation:
Basic Concept: Human-in-the-loop is a design pattern where AI systems generate recommendations or decisions but require human review and approval before those recommendations are acted upon. This approach maintains human oversight and accountability in AI-assisted workflows. CompTIA SecAI+ Study Guide covers human-in-the-loop as a key responsible AI principle and operational pattern.
Why C is Correct: The scenario precisely describes the human-in-the-loop pattern: the AI system identifies potential issues and provides recommendations, but an administrator must review those recommendations before any action is taken. This deliberate inclusion of human judgment in the AI ' s decision or recommendation workflow ensures human oversight is maintained, which is the defining characteristic of the human-in-the-loop process.
Why A is Wrong: Data validation verifies that data meets expected quality standards and formats before being used in AI processing. It is a data quality control activity, not a workflow pattern describing human review of AI recommendations.
Why B is Wrong: Data preparation involves transforming raw data into a format suitable for AI model training or inference. It encompasses cleaning, normalizing, and formatting data, not the process of human review of AI-generated recommendations during system updates.
Why D is Wrong: Model evaluation assesses a model ' s performance against metrics such as accuracy, precision, and recall on test datasets. It is a technical assessment of model quality, not a workflow process where humans review AI-generated recommendations before acting on them.
Which of the following should an auditor reference when reviewing a company ' s human resources AI systems for legal non-compliance?
Options:
Organization for Economic Cooperation and Development (OECD) standard
National Institute of Standards and Technology (NIST) AI Risk Management Framework (RMF)
European Union (EU) AI Act
International Organization for Standardization (ISO)
Answer:
CExplanation:
Basic Concept: Various regulatory frameworks govern AI use in different contexts. For auditing legal compliance in high-risk AI applications such as employment and HR, binding regulatory legislation takes precedence over voluntary standards. CompTIA SecAI+ Exam Objectives cover AI governance and compliance frameworks under Domain 4.
Why C is Correct: The EU AI Act is the world ' s first comprehensive, legally binding AI regulation. It explicitly classifies AI systems used in employment, worker management, and recruitment as high-risk AI systems, subjecting them to strict compliance requirements including conformity assessments, transparency obligations, and human oversight mandates. An auditor reviewing HR AI for legal non-compliance must reference this binding legislation.
Why A is Wrong: The OECD AI Principles are non-binding international guidelines promoting responsible AI. They offer policy guidance but carry no legal enforcement power for compliance auditing.
Why B is Wrong: The NIST AI RMF is a voluntary, risk management-focused framework. It is not a legal compliance standard and cannot be used to assess legal non-compliance.
Why D is Wrong: ISO standards such as ISO 42001 are voluntary international best practice standards. They are not legal compliance instruments with enforceable penalties for HR AI systems.
During the selection of a machine learning (ML)-based threat classification model, a cybersecurity administrator verifies that label distribution is highly unbalanced.
Which of the following processing techniques should the engineer use to balance the model?
Options:
Data lineage
Data augmentation
Data provenance
Data verification
Answer:
BExplanation:
Basic Concept: Class imbalance in training data — where some categories have significantly more examples than others — causes ML models to be biased toward the majority class, producing poor detection of minority class threats. Addressing this imbalance before training is critical for threat classification accuracy. CompTIA SecAI+ covers data preparation techniques under basic AI concepts.
Why B is Correct: Data augmentation addresses class imbalance by artificially increasing the number of training samples in under-represented classes. Techniques include oversampling minority classes by creating synthetic examples using methods like SMOTE (Synthetic Minority Over-sampling Technique), or undersampling majority classes. This balances label distribution and enables the model to learn decision boundaries that accurately classify all threat categories, not just the dominant ones.
Why A is Wrong: Data lineage documents the origin, movement, and transformation of data throughout its lifecycle. It provides traceability and auditability but does not address class imbalance in training data distribution.
Why C is Wrong: Data provenance records the history and context of data origins. Like lineage, it is a governance and tracking concept that does not alter data distribution for model training balance.
Why D is Wrong: Data verification confirms that data is correct and consistent with expected formats and values. It checks data quality and integrity but does not address the statistical distribution imbalance between threat classes in training datasets.
A company introduces a large language model (LLM) in an application in order to monitor for a potential denial-of-service attack.
Which of the following should the company use to measure the utilization of the LLM?
Options:
Token
Transformer
Chain of thoughts
Prompt
Answer:
AExplanation:
Basic Concept: LLMs process and generate text as discrete units called tokens, which represent words or word pieces. The number of tokens consumed is the primary metric for LLM resource utilization and billing. Understanding token consumption is essential for both performance monitoring and cost management. CompTIA SecAI+ Study Guide covers token-based measurement under AI system management.
Why A is Correct: Tokens are the fundamental unit of measurement for LLM utilization. Both input tokens sent in prompts and output tokens generated in responses are counted. Token consumption directly correlates with computational resource usage, response time, and API cost. Monitoring token counts enables the company to establish usage baselines and detect the abnormal token consumption spikes associated with DoS attacks or denial-of-wallet attacks against the LLM.
Why B is Wrong: A transformer is the neural network architecture that underlies modern LLMs. It is an architectural description, not a measurable utilization metric. You cannot quantify LLM resource consumption in " transformers. "
Why C is Wrong: Chain of thought is a prompting technique that encourages models to reason step-by-step before providing answers. It is an inference strategy for improving response quality, not a unit of measurement for monitoring LLM utilization or resource consumption.
Why D is Wrong: A prompt is the input text submitted to the LLM. While monitoring prompt volumes provides request count information, tokens provide a more granular and meaningful utilization metric because they capture both the complexity of inputs and the length of generated outputs.
A security engineer needs to monitor an AI-based system for runtime operations. The engineer is mostly concerned about the visibility of internal activity.
Which of the following is the most appropriate monitoring solution?
Options:
Deploying a security information and event management (SIEM) tool
Implementing a web application firewall (WAF) with header logging
Relying on vendor model controls and monitoring prompt inputs
Enabling stack call and debugging level traces at the function level
Answer:
DExplanation:
Basic Concept: Monitoring an AI system ' s internal runtime behavior requires deep observability into what the system is doing at the code and function execution level, not just at the perimeter. CompTIA SecAI+ Study Guide addresses AI system observability and runtime monitoring under securing AI infrastructure.
Why D is Correct: Enabling stack call and debugging level traces at the function level provides the highest granularity of visibility into internal operations. This approach exposes what functions are called, in what order, with what inputs, and what is returned, offering genuine insight into the AI system ' s internal activity at runtime precisely as the engineer requires.
Why A is Wrong: A SIEM aggregates and correlates log and event data from multiple sources. While useful for security alerting, it does not inherently provide visibility into internal function-level operations of an AI model at runtime.
Why B is Wrong: A WAF with header logging monitors and filters HTTP traffic at the application boundary. It captures external request and response data, not the AI system ' s internal runtime mechanics.
Why C is Wrong: Relying on vendor controls and monitoring prompt inputs is a passive, externally-focused approach. It provides no visibility into intermediate computations or internal operations within the AI model itself.
A short AI-generated video shows a celebrity ' s likeness talking about a fake public security event.
Which of the following was used to create this video?
Options:
Statistical analysis
Convolutional neural network
Machine learning (ML) classifier
Random forest
Answer:
BExplanation:
Basic Concept: Creating realistic deepfake videos that convincingly replicate a real person ' s facial expressions, movements, and voice requires deep learning models capable of learning and synthesizing complex spatial and temporal features from existing video data. CompTIA SecAI+ covers deepfake technologies under basic AI concepts.
Why B is Correct: Convolutional Neural Networks are foundational to deepfake video generation. CNNs excel at learning spatial features from visual data and are used within deepfake architectures to analyze source and target faces, extract facial features, and synthesize realistic face swaps or face animations. Modern deepfake systems typically combine CNNs with autoencoders and GANs to generate convincing video content showing a person saying or doing things they never did.
Why A is Wrong: Statistical analysis involves mathematical methods for analyzing data distributions and relationships. It does not have the capability to generate synthetic video content or replicate a person ' s visual likeness in motion.
Why C is Wrong: An ML classifier assigns input data to predefined categories. Classification models detect and label content rather than generating new synthetic video content of a person ' s likeness. They are detection tools, not generation tools.
Why D is Wrong: Random forest is an ensemble ML method using multiple decision trees for classification and regression tasks. It works on structured, tabular data and cannot process or generate visual, spatial data needed for realistic deepfake video synthesis.
