Associate Certification - InsuranceSuite Developer - Mammoth Proctored Exam Questions and Answers
A developer is creating a new entity for auditors that contains a field for the license. Which configuration of the file name and the field name fulfills the requirement and follows best practices?
In the screenshot below

A developer has added a tab labeled Delinquencies to the tab bar of BillingCenter. This tab will contain several pages. The first page in the tab will display a summary of the currently-selected delinquency, the second page will show the associated policy, and the third page will show the associated account.
What PCF container will be used to configure this requirement?
Which log message output follows best practices in production?
A query is known to return 500,000 rows. Which two are recommended to process all 500,000 rows efficiently? (Select two)
An insurer needs to define a new Typecode on an existing base application Typelist. Which actions follow best practices for implementing this requirement in Guidewire InsuranceSuite? (Choose 2)
Succeed Insurance needs to extend the contact functionality to support tracking agency information. The new agency entity should have all of the fields of ABCompany, but include fields that are specific to the agency. Following best practices, which of the following options would implement this requirement?
What is a benefit of archiving?
The business wants to create a new popup in BillingCenter that displays a single customer invoicing inquiry. The popup will have the inquiry date, inquiry contact, and the description of the inquiry. Which configurations follow best practices to make this page editable? (Choose Two)
An insurer has identified a new requirement for company vendor contacts in ContactManager. If the Preferred Vendor9 field is set to Yes, display the new BBS Rating (Better Business Bureau) field.
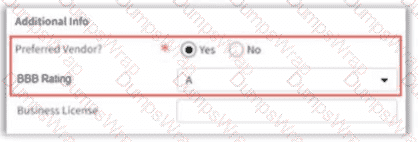
Which two configuration changes will satisfy this requirement? (Select two)
In TrainingApp. the Person Info card of the Details screen for a contact has a section where basic employment information is stored:

The insurer requires this information to be displayed, in this format, on every card of both the Summary and Details screens, for every individual person contact. This information will be stored in a container to be reused on all these cards.
Which object will most efficiently meet this requirement, according to best practices?
The following screenshot displays a segment of the menu items in the sidebar on a Guidewire application:
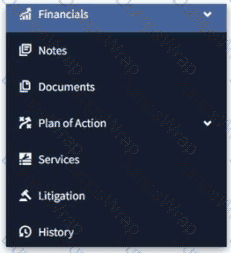
[Financials, Notes, Documents, Plan of Action, Services, Litigation, History]. The business analysts have uncovered a requirement that the Documents, History, Litigation, and Notes pages should be grouped under a single heading, to be called Legal Records. What is the best practice for accomplishing this?
An insurance carrier plans to launch a new product for various types of Recreational Vehicles (RVs)—such as motorhomes, boats, motorcycles, and jet skis. When collecting information to quote a policy, all RVs share some common details (like purchase date, price, year, make, and model), but each type also has its own unique properties. According to best practices, what should be done to configure the User Interface so that only the relevant RV details are shown when creating a policy quote? Select Two
What is a benefit of archiving?
Given the following code example:
var query = gw.api.database.Query.make(Claim)
query.compare(Claim#ClaimNumber, Equals, " 123-45-6798 " )
var claim = query.select().AtMostOneRow
According to best practices, which logic returns notes with the topic of denial and filters on the database?
Which rule is written in the correct form for a rule which sets the claim segment and leaves the ruleset?
An insurer has a number of employees whose names are similar, but each one has a unique employee number for identification. Displaying the employee ' s name as a drop-down list in the user interface must include the employee ' s number with the employee ' s name to ensure uniqueness. For example:
John Smith 3455
William Andy 3978
John Smith 4041
How can a developer satisfy this requirement following best practices?
An insurer has a number of employees who are working remotely from different locations. Displaying the employee ' s name in a drop-down list in the user interface must include the employee ' s location along with it. For example: John Smith London, UK; William Andy Dublin, Ireland; Eric Andy BC, Canada. How can a developer satisfy this requirement following best practices?
An insurer plans to offer coverage for pets on homeowners policies. Whenever the covered pet Is displayed in the user interface, it should consist of the pet ' s name and breed. For example:

How can a developer satisfy this requirement following best practices?
The sources describe different types of deployment strategies for InsuranceSuite applications. What are characteristics of a selective deployment?
Which GUnit base class is used for tests that involve Gosu queries in PolicyCenter?
The following Gosu statement is the Action part of a validation rule:
claim.rejectField( " State " , TC_PAYMENT, DisplayKey.get( " Rules.Validation.Claim.NotInDraft " , null, null))
It produces the following compilation error:
Gosu compiler: Wrong number of arguments to function rejectField(java.lang.String, typekey.ValidationLevel, java.lang.String, typekey.ValidationLevel, java.lang.String). Expected 5, got 3
What needs to be added to or deleted from the statement to clear the error?
A developer has modified the DesktopActivities list view in ClaimCenter to add a date cell to display the claim date of loss for each row. The list view is backed by the view entity ActivityDesktopView. The screenshot provided shows the current configuration of the new date cell with the value
ActivityDesktopView.Claim.LossDate.
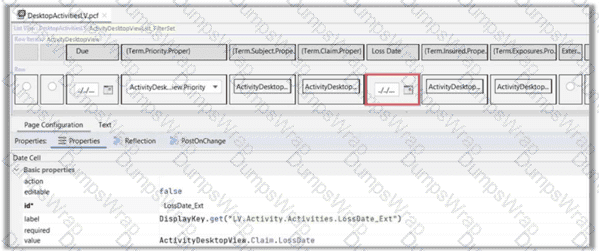
Which action should be taken to configure the date cell to follow best practices?
Given the following query:
uses gw.api.database.Query
var query = Query.make(Claim)
query.compare(Claim#ClaimNumber, Equals, " 123-45-6789 " )
var claim = query.select().AtMostOneRow
Which follows the best practice to find the urgent open activities of the claim, considering the memory usage and bundle size?
ACME Insurance requires that addresses are validated through a postal service in all insurance products. Which package structure and Gosu class name follow best practice?
Given the following code sample:
var newBundle = gw.transaction.Transaction.newBundle()
var targetCo = gw.api.database.Query.make(ABCompany)
targetCo.compare(ABCompany#Name, Equals, " Acme Brick Co. " )
var company = targetCo.select().AtMostOneRow
company.Notes = " TBD "
Following best practices, what two items should be changed to create a bundle and commit this data change to the database? (Select two)
When a user marks the InspectionComplete field and clicks Update, the user making the update and the date/time of the update need to be recorded in separate fields. Which approach will accomplish this?
Given the following screen showing a DetailView in Guidewire Studio highlighted in red:

Which single item added directly to the detail view will correct the error shown, with no further errors?
A developer performed Guidewire Profiler analysis on a web service. The results showed a large Own Time (unaccounted-for time) value, but it is difficult to correlate the data with the exact section of code executed. Which approach can help to identify what is causing the large processing time?
Which log message follows logging best practices in production?
Succeed Insurance is developing multiple policy lines of business (LOB). The LOBs they are implementing are Homeowners (HO), Commercial Auto (CA), and Personal Auto (PA). They want to show key data elements of these LOBs on the exposure screen in ClaimCenter. To support this, you will need to modify the ExposureDetailDV container to support the different LOBs. Following best practices, which of the following implementations should be used?
The Panel Ref in the screenshot below displays a List View with a toolbar. Add and Remove buttons have been added to the toolbar, but they appear in red, indicating an error. The Row Iterator has toAdd and toRemove buttons correctly defined.
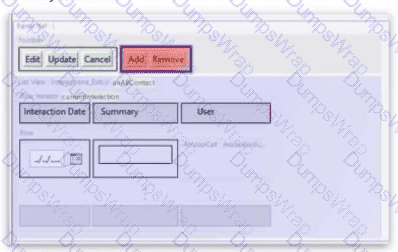
What needs to be configured to fix the error?
Succeed Insurance would like a list of all Notes related to all Policies for an Account. Which approach follows best practices for retrieving this data more efficiently?
The Guidewire Cloud Platform (GWCP) uses an astronomy metaphor to describe its logical partitions. Which statements accurately describe how different levels within this metaphor provide isolation? (Choose 2)
A query is known to return 500,000 rows. Which two are recommended to process all 500,000 rows efficiently? (Select two)
An insurer doing business globally wants to use a validation expression to verify that a contact ' s postal code is a real postal code for the country specified in the contact ' s address.
A developer has created a method with the signature validatePostalCode(anAddress: Address): boolean, which returns true if and only if the postal code is valid.
What would be the correct validation expression?
Which statements describe best practices when using bundles in Gosu to save new entities/edit existing entities? (Select Two)
There is a requirement to add fields specific to Auto Rental Agencies. The additional fields required are; Auto Renta License, Offers Roadside Assistance, and Offers Insurance. Other fields will come from the existing ABCompanyVendor entity.
For reference, the diagram below shows the ABCompany subtype of the ABContact entity:
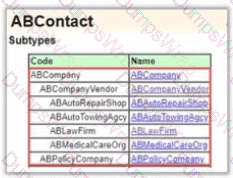
How should this requirement be configured following best practices?
An insurer ran the DBCC checks against a copy of their production database and found three errors with high counts in the category Data update and reconciliation. What are two best practices for resolving the errors? (Select two)
Succeed Insurance needs to add a new getter property to the Java class generated from the Contact entity. According to best practices, what steps below would allow this to get implemented? (Select Two)
A developer is creating an enhancement class for the entity AuditMethod_Ext in PolicyCenter for an insurer, Succeed Insurance. Which package structure of the gosu class and function name follows best practice?
An insurer has extended the ABContact entity in ContactManager with an array of Notes to capture information of interest about the contact over time. A developer has been asked to write a function to process all the notes for a given contact. Which code satisfies the requirement and follows best practices?
Which two statements are true regarding the Guidewire Cloud Assurance process? (Select two)
For ABPerson contacts only, the marketing team has requested to store the name of the individual ' s favorite sports team. What data model extension follows best practices to fulfill this requirement?
A developer is creating an entity for home inspections that contains a field for the inspection date. Which configuration of the file name and the field name fulfills the requirement and follows best practices?
An insurance carrier needs the ability to capture information for different kinds of watercraft, such as power boats, personal water craft, sailboats, etc. The development team has created a Watercraft_Ext entity with subtype entities to store the distinct properties of each type of watercraft. Which represents the best approach to provide the ability to edit the data for watercraft in the User Interface?
