HCIP-Cloud Computing V5.0 Questions and Answers
In HUAWEI CLOUD Stack, the management of BMSs depends on the component Ironic , which manages physical servers throughout their lifecycle. (Fill in the blank.)
Options:
Answer:
Ironic
Explanation:
The correct fill-in answer is Ironic . Huawei’s official HUAWEI CLOUD Stack documentation clearly states that Ironic provides BMS management services by working with components such as Nova and Neutron . Huawei’s BMS usage guide also explicitly refers to BMS lifecycle management operations , including actions such as starting, stopping, forcibly stopping, and other lifecycle tasks. This confirms that Ironic is the component responsible for managing physical servers through their lifecycle in a Huawei Cloud Stack environment.
This is consistent with standard OpenStack architecture as well, where Ironic is the OpenStack Bare Metal service used to provision and manage physical machines similarly to how Nova manages virtual machines. In Huawei Cloud Stack, BMS is not handled as a simple ECS variant; instead, it relies on Ironic for provisioning, state transitions, and lifecycle orchestration of dedicated hardware resources.
Therefore, after correcting the sentence, the blank should be filled with Ironic , and the fully verified answer is Ironic .
Which of the following statements are true about the network resource management function of Service OM?
Options:
Administrators can check the status of ports, for example, VM NIC ports.
Administrators can create virtual networks and private line access points.
Administrators can directly view the status of physical and virtual networks.
Administrators can create physical networks.
Answer:
A, B, CExplanation:
The best verified answer is A, B, and C. Huawei’s Managing Network Resources documentation states that on Service OM, administrators can view the number of created physical networks and virtual networks, which supports option C. The same Huawei material also says administrators can collect information for handling VM network faults, and related VPC/API guidance shows Service OM visibility into ports, including VM NIC-related ports, which supports A.
Huawei documentation for Direct Connect further shows that administrators can create Direct Connect access points on Service OM before tenants can use Direct Connect. In training-style wording, this aligns with the idea of creating private line access points, so B is also correct.
Option D is the one that does not fit as a standard Service OM network resource management action in the same way. Huawei documentation emphasizes viewing physical network information and managing related network resources, but creation or low-level configuration of physical networks is generally handled through platform network configuration workflows rather than as a routine Service OM tenant/resource function. Therefore, the correct set is A, B, C.
========
Match the following Auto Scaling (AS) concepts with their descriptions in Huawei Cloud Stack.

Options:
Answer:
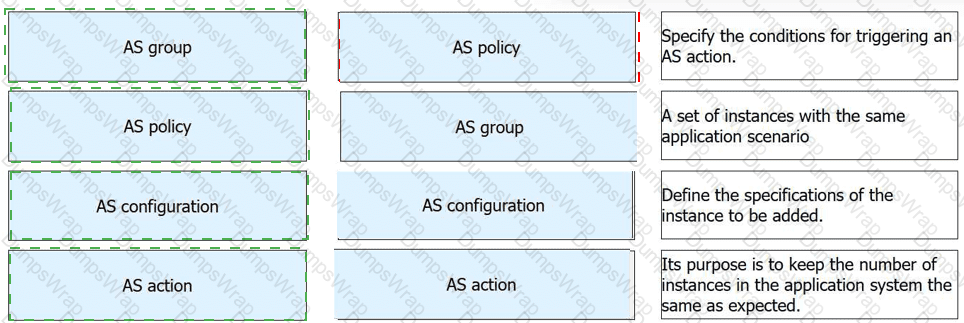
Explanation:
AS group → A set of instances with the same application scenario
AS policy → Specify the conditions for triggering an AS action
AS configuration → Define the specifications of the instance to be added
AS action → Its purpose is to keep the number of instances in the application system the same as expected
Comprehensive and Detailed 150 to 200 words of Explanation From HUAWEI CLOUD Computing Topics:
This matching is consistent with Huawei’s official Auto Scaling concept definitions. Huawei states that an AS group consists of a collection of instances that apply to the same application scenario , so that description belongs to AS group . Huawei also explains that an AS policy specifies the conditions for triggering a scaling action , which makes the second match straightforward.
Huawei’s Auto Scaling documentation further distinguishes AS configuration from policy and action. The configuration defines the template or specifications for the instances that will be added during scaling, so define the specifications of the instance to be added correctly matches AS configuration . Finally, Huawei defines a scaling action as adding or removing ECS instances from an AS group, and states that its purpose is to keep the number of instances in the application system at the expected level. That directly matches the final description.
So the verified drag-and-drop mapping is: group = instance set , policy = trigger condition , configuration = instance specification , and action = maintain expected instance count .
When registering an image on Service OM, if the image is bigger than 6 GB, select FTP or NFS for uploading the image. (Fill in the blank.)
Options:
Answer:
FTP
Explanation:
The correct fill-in answer is FTP. Huawei documentation for image registration on Service OM shows that images can be uploaded using different modes, including local upload, FTP, and NFS. The guidance indicates that for larger image files, administrators should use a network-based upload mode rather than simple local browser upload. In the Huawei document snippet, the upload options explicitly include NFS, and the paired option used in this context is FTP, which matches the exam sentence structure: “select ____ or NFS.”
This makes sense operationally in HUAWEI CLOUD Stack because large image files are more reliably transferred through shared file or server-based methods, especially in enterprise O & M scenarios. Local browser-based uploads are less suitable for very large images due to session stability, browser limits, and transfer reliability. Using FTP or NFS improves image registration efficiency and reduces the chance of interrupted uploads during image onboarding. Therefore, after correcting the sentence, the blank should be filled with FTP.
========
Which of the following statements are true about security groups and network ACLs in HUAWEI CLOUD Stack?
Options:
Security group and network ACL settings are both mandatory by default.
Security group rules are combined when they conflict with each other, while network ACL rules are sorted by priority.
Security groups protect instances. Network ACLs protect subnets.
Security groups support packet filtering based on a 5-tuple. Network ACLs support packet filtering based on a 3-tuple.
Answer:
B, CExplanation:
The correct answers are B and C . Huawei documentation states that a security group is a collection of access control rules used to protect cloud servers or instances added to that group. Huawei also describes a network ACL as a security service for VPCs or subnets , which means it protects traffic at the subnet level rather than directly protecting individual instances. That makes C correct.
Huawei’s comparison guidance also distinguishes the way rules are processed. Security groups are stateful and their rules work together as a combined access-control set, while network ACLs are processed according to rule priority , which makes B correct. The official Huawei comparison page explicitly frames network ACLs as an additional security layer on top of security groups.
Option A is incorrect because network ACLs are not mandatory by default in the same way security-group association is standard for instances. Option D is not supported by the Huawei VPC/network ACL documentation cited here; the docs emphasize instance-vs-subnet scope and rule handling, not that exact 5-tuple versus 3-tuple split for these two features. Therefore, the best verified answer is B, C .
========
In OpenStack, when a VM is paused, its memory state is saved to disk, which requires only minimal resources.
Options:
TRUE
FALSE
Answer:
BExplanation:
The statement is FALSE . Official OpenStack documentation clearly distinguishes pause from suspend . When a server is paused , OpenStack states that the state of the VM is stored in RAM , and the instance continues in a frozen state. This means memory is not written to disk during a pause operation. Because RAM is still occupied, a paused VM does not reduce resource usage to a minimal level in the way the question suggests.
By contrast, when a server is suspended , OpenStack documentation says that its state is stored on disk , all memory is written to disk , and the server is stopped. This is the action that is conceptually similar to hibernation. The distinction is important in OpenStack and Huawei Cloud Stack operations because pause is mainly used for temporary freezing of execution, while suspend is used when preserving state on disk is required. Therefore, the statement in the question incorrectly describes suspend , not pause . For that reason, the correct answer is B (FALSE) .
In OpenStack, HOT and CFN templates both support YAML. CFN templates are more suitable for OpenStack deployments.
Options:
TRUE
FALSE
Answer:
BExplanation:
The statement is FALSE . Official OpenStack Heat documentation says that when the Orchestration service was originally introduced, it worked with AWS CloudFormation templates , which are in JSON format. It then states that Heat also runs HOT templates written in YAML . This directly disproves the claim that both HOT and CFN templates support YAML in the same native sense.
OpenStack Heat documentation also explains that HOT was introduced to replace the Heat CloudFormation-compatible format (CFN) as the native format supported by Heat over time. That means HOT, not CFN, is the format more suitable for OpenStack-native deployments. The documentation further notes that YAML is easier to write, parse, and maintain, which is one reason HOT became the preferred OpenStack format.
Although internal parsing code shows the API can accept a JSON- or YAML-formatted document in some contexts, the OpenStack-native orchestration model clearly favors HOT and identifies CFN as the older CloudFormation-compatible format. So the combined statement is incorrect, and the correct answer is B (FALSE) .
========
In HUAWEI CLOUD Stack, the maximum size of a Scalable File System (SFS) file is 240 TB. The capacity of a file system can be increased to ______. (Fill in the blank.)
Options:
Answer:
PB level
Explanation:
The correct fill-in answer is PB level . Huawei’s official HUAWEI CLOUD Stack SFS documentation states that the maximum capacity of a single file is 240 TB , and it further explains that the file system capacity can be scaled to the PB level . This is the exact Huawei wording used to describe the upper expansion capability of SFS.
This reflects the design goal of SFS in Huawei Cloud Stack: to provide managed, shared file storage for applications that require large-scale file-system growth over time. In other words, the size of one individual file and the total expandable capacity of the file system are two different things. A single file has a stated upper limit, but the whole file system can continue to grow far beyond that limit, reaching petabyte-scale capacity
Therefore, after correcting the sentence structure, the blank should be filled with PB level , which is the official Huawei description of the scalable upper capacity for the file system.
========
Which of the following is not a core value proposition of Horizon in OpenStack?
Options:
API eventual consistency
View consistency
API backward compatibility
Scalability
Answer:
AExplanation:
Horizon is the web-based dashboard for OpenStack, designed to provide a consistent graphical interface for managing cloud resources. In practice, Horizon focuses on presenting a consistent view of services to users and administrators, and OpenStack components commonly maintain API backward compatibility to support upgrades and continued interoperability. OpenStack documentation also shows that Horizon can be used in larger and multi-region environments, which supports the idea that scalability is relevant to its operational value.
However, API eventual consistency is not a Horizon value proposition. “Eventual consistency” is a concept found in distributed storage systems such as OpenStack Swift/Object Storage, where updates may take time to become visible everywhere. OpenStack documentation explicitly uses this term in the context of Object Storage behavior, not Horizon dashboard design. Because Horizon is a management dashboard rather than a distributed storage consistency model, API eventual consistency does not belong as one of its core value propositions. Therefore, the correct answer is A . This is the best-supported conclusion from official OpenStack documentation and aligns with Huawei Cloud training-style OpenStack topic coverage.
Which of the following O & M scenarios can be supported by a CMDB’s dynamic dependency in HUAWEI CLOUD Stack?
Options:
Root cause locating
Resource capacity planning
Application deployment topology display
Certificate replacement in batches
Answer:
A, CExplanation:
The correct answers are A and C. Huawei’s cloud-service monitoring documentation shows that administrators can view the cloud service topology and dependencies between the current cloud service and other cloud services. This is exactly the kind of capability enabled by a CMDB’s dynamic dependency model, and it clearly supports application deployment topology display, which corresponds to option C.
Dynamic dependency information is also highly relevant to root cause locating, because dependency graphs help O & M personnel trace failures from one service to dependent services and identify the likely upstream or downstream source of an issue. Huawei troubleshooting materials reference locating faults of dependent services, which aligns with option A.
By contrast, resource capacity planning is a capacity-management scenario rather than a dynamic-dependency scenario, and certificate replacement in batches is an operational maintenance task that does not primarily depend on CMDB dynamic dependencies. Therefore, the supported scenarios are A and C, making the verified answer A, C.
In HUAWEI CLOUD Stack, the weak affinity policy of a VM group schedules VMs in the same group to one host when resources are sufficient. If resources are insufficient, the rule can be broken.
Options:
TRUE
FALSE
Answer:
AExplanation:
The correct answer is A (TRUE) . Huawei Cloud Stack compute resource management documentation explicitly describes the behavior of soft-affinity , which is the practical equivalent of weak affinity in scheduling policy terms. Huawei states that if host resources are sufficient, VMs in the same soft-affinity group will be scheduled to the same host . It further states that if resources are insufficient or the current host is faulty, the VMs can be scheduled to different hosts . This matches the wording of the question almost exactly.
Huawei ECS group documentation also explains that an ECS group can be configured with affinity, anti-affinity, weak affinity, or weak anti-affinity policies, which confirms that weak affinity is an officially recognized scheduling policy in Huawei Cloud Stack. The “weak” part means the scheduler prefers a placement rule but is allowed to violate it when necessary to ensure successful deployment or continuity.
Therefore, the statement accurately reflects Huawei’s documented scheduling behavior: under normal conditions, VMs tend to be placed together, but if resources are inadequate, the rule may be broken. So the verified answer is TRUE .
Which of the following scenarios is not suitable for resource sets in HUAWEI CLOUD Stack?
Options:
Simplifying batch authorization of finance department resources
Managing the services or resources of branches across regions
Dividing resources of different projects in a VDC
Isolating R & D test resources from production services in the same VDC
Answer:
BExplanation:
The correct answer is B. Managing the services or resources of branches across regions . In HUAWEI CLOUD Stack, resource sets are primarily used as an internal organizational and authorization tool within a tenant or VDC . They are well suited for grouping resources by department , project , or environment , such as production versus test resources. This means options A , C , and D are all typical and appropriate use cases because they involve structuring and controlling resources inside the same logical management domain. ( )
By contrast, managing services or resources of branches across regions is broader than the normal scope of a resource set. Cross-region branch management usually involves higher-level multi-region organizational constructs, regional administration, or broader tenant/VDC design rather than simply creating a resource set. Resource sets help refine governance inside an established tenant structure; they are not the main mechanism for organizing geographically distributed branch operations across regions.
So after correcting the wording, the scenario that is not suitable for resource sets is B , because it describes a cross-region management requirement that typically belongs to a higher-level cloud planning and governance model rather than a resource-set grouping function. Therefore, the verified answer is B .
In HUAWEI CLOUD Stack, to view details about a specific instance, you can run openstack server _____ < server > . The < server > parameter specifies the instance ID or name. Which of the following parameters should be entered in the blank?
Options:
list
query
show
conf
Answer:
CExplanation:
The correct answer is C. show . Official OpenStack command-line documentation explicitly lists the command openstack server show < server > and explains that it is used to show server details . The same documentation states that the < server > argument represents the server name or ID , which matches the wording in your question exactly.
The other options are not correct in this context. openstack server list displays a list of servers rather than the details of one specific instance. query and conf are not valid standard subcommands for this OpenStack server-detail operation. Since HUAWEI CLOUD Stack operations in this area follow OpenStack command syntax for instance inspection and lifecycle management, the proper command for viewing one instance’s details is openstack server show < server > .
Therefore, after correcting the sentence format, the blank should be filled with show , and the full verified command is openstack server show < server > . That makes the correct answer C .
========
Which of the following is not a service plugin in Neutron?
Options:
L3 Service Plugin
ML2 Plugin
VPN Service Plugin
LB Service Plugin
Answer:
BExplanation:
The correct answer is B. ML2 Plugin . In OpenStack Neutron, ML2 stands for Modular Layer 2 and is the main core networking plugin framework used to support different network types and mechanism drivers. Official OpenStack documentation describes ML2 as a plug-in with components for network types and mechanisms, not as a service plugin .
Service plugins in Neutron are different. They add higher-level networking services beyond basic Layer 2 connectivity. OpenStack deployment documentation shows optional service areas such as load balancing and virtual private network services, and Neutron’s router-related functionality is commonly associated with the L3 service plugin . These are examples of service plugins layered on top of the core networking plugin model.
So the key distinction is this: ML2 is the core plugin architecture , while L3, VPN, and load balancing belong to the service-plugin category. In Huawei Cloud Stack networking topic coverage, this separation between the core Neutron plugin and optional service plugins is also fundamental. Therefore, the option that is not a service plugin is B. ML2 Plugin .
========
Which of the following components can be used to process Network Address Translation (NAT) and route forwarding in Neutron?
Options:
L2 Agent
L3 Agent
NAT Agent
DHCP Agent
Answer:
BExplanation:
The correct answer is B. L3 Agent . Official OpenStack Neutron documentation states that routers provide virtual Layer 3 services such as routing and NAT , and that the Networking service uses a layer-3 agent to manage routers. OpenStack also explicitly says that the neutron-l3-agent uses the Linux IP stack and iptables to perform L3 forwarding and NAT . This directly matches the wording of the question.
The other options do not fit. The L2 agent handles local virtual switch configuration and Layer 2 networking behavior, not routing and NAT. The DHCP agent provides DHCP services to tenant networks. “ NAT Agent ” is not the standard Neutron component name used in official OpenStack architecture. OpenStack documentation consistently identifies the L3 agent as the component responsible for router namespace management, forwarding, floating IP behavior, and source NAT functions.
This is also consistent with Huawei Cloud Stack networking architecture topics, where routing and NAT functions are tied to Neutron Layer 3 services. Therefore, the fully verified answer is B. L3 Agent .
In OpenStack, Diskimage Builder can automatically create images for multiple operating systems, so it is suitable for creating standard images in batches.
Options:
TRUE
FALSE
Answer:
AExplanation:
The statement is TRUE . OpenStack’s official image creation documentation describes Diskimage Builder (DIB) as an automated disk image creation tool that supports a variety of Linux distributions and architectures. The documentation explicitly states that DIB can build images for Fedora, Red Hat Enterprise Linux, Ubuntu, Debian, CentOS, and openSUSE , which confirms that it can generate images for multiple operating systems from a standardized build framework. It also supports reusable “elements,” allowing operators to define image content in a modular and repeatable way.
Because of this automation and modularity, DIB is well suited for batch creation of standard images in enterprise cloud environments, including OpenStack-based platforms such as Huawei Cloud Stack. Instead of manually creating images one by one, administrators can define consistent build templates and produce multiple images with the same baseline security, packages, and configuration standards. That aligns directly with the role of standardized image management in cloud O & M and service deployment. Therefore, the correct answer is A (TRUE) .
========
In HUAWEI CLOUD Stack, which of the following is the main function of Service OM?
Options:
Infrastructure hardware monitoring
Centralized cross-product monitoring
Cloud platform deployment and upgrade
Resource pool and basic cloud service management
Answer:
DExplanation:
The correct answer is D. Resource pool and basic cloud service management . Huawei’s official License Guide includes a dedicated section called “Resource Pool & Basic Cloud Services” and explicitly instructs administrators to enter Service OM to perform management actions there. This directly ties Service OM to the management plane for resource pools and basic cloud services , rather than positioning it primarily as a hardware-monitoring tool or a deployment platform.
Huawei Cloud Stack O & M materials also show Service OM being used for operational management tasks such as viewing VMs, host groups, cloud services, and system resource status. In contrast, deployment and upgrade are associated with dedicated installation and upgrade tools, not Service OM as the main function. Similarly, centralized monitoring across products is broader than Service OM’s core purpose and is covered by other monitoring and O & M capabilities in the Huawei Cloud Stack architecture.
Therefore, among the available choices, the description that best matches Huawei’s official positioning of Service OM is resource pool and basic cloud service management . That makes D the most accurate and fully verified answer.
========
In HUAWEI CLOUD Stack, which of the following features reflect the elasticity of ECSs?
Options:
Quick creation of instances based on IMS images
Automatic scaling of instances in combination with AS
Specification downgrade (for example, by reducing the number of CPU cores) to reduce costs
Online upgrade of CPUs and memory
Resource isolation at the physical server level
Answer:
A, B, DExplanation:
The correct answers are A, B, and D. Huawei’s official ECS documentation highlights several elasticity-related capabilities. It states that Auto Scaling (AS) can automatically add or remove ECSs based on service demand, which directly supports option B. Huawei also states that ECS flavors can be modified, including changes to CPU and memory, which supports D as an elastic scaling feature. In addition, Huawei’s IMS documentation explains that images can be used to create ECSs in batches and, together with AS, support dynamic scale-out, which makes A a valid reflection of ECS elasticity as well.
Option C is not well supported as stated, because Huawei documentation emphasizes flavor modification and online flavor change mainly in the context of scaling resources, especially increasing CPUs and memory, not “specification downgrade” as a core elasticity feature. Option E refers to physical isolation, which is a BMS characteristic rather than an ECS elasticity feature. Therefore, the best verified answer is A, B, D.
