Designing and Implementing a Data Science Solution on Azure Questions and Answers
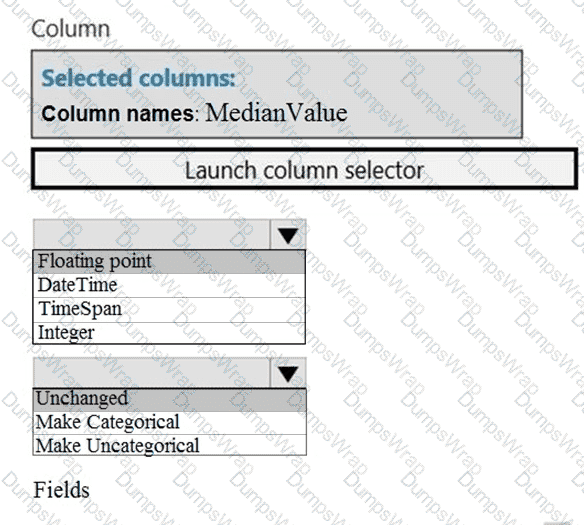
You need to select a feature extraction method.
Which method should you use?
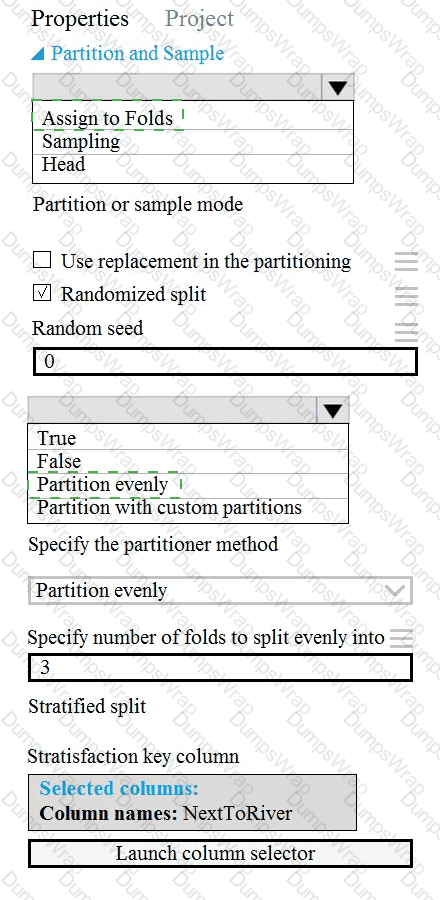
You need to identify the methods for dividing the data according to the testing requirements.
Which properties should you select? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.



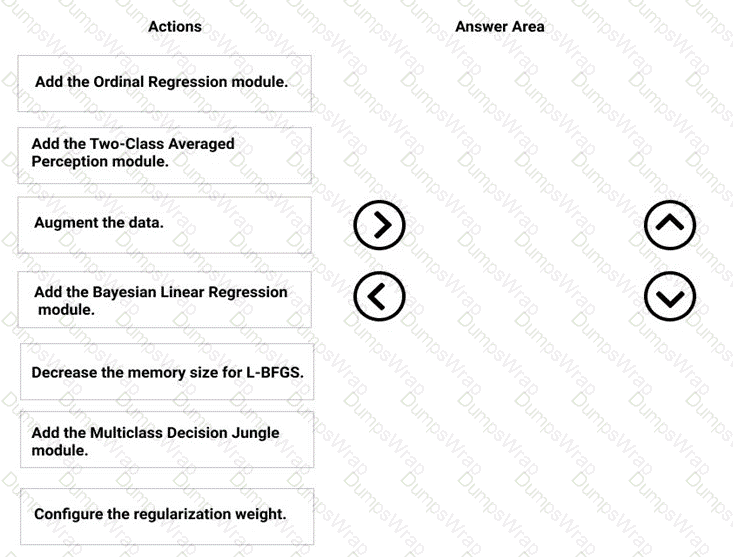
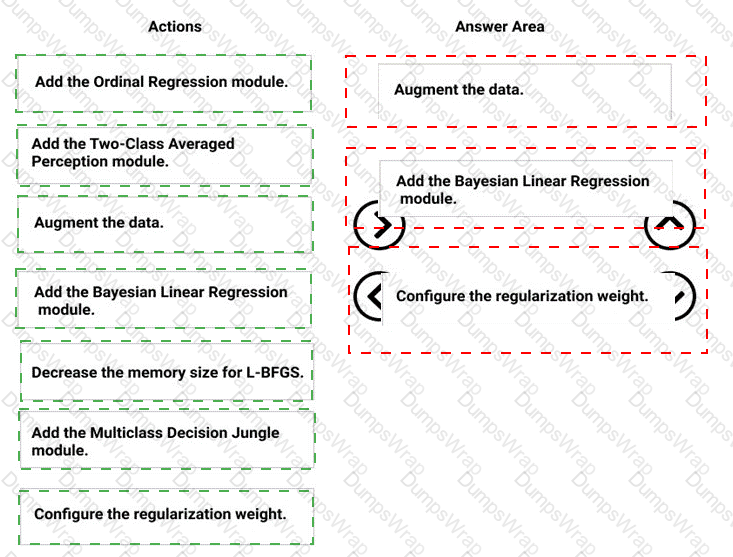
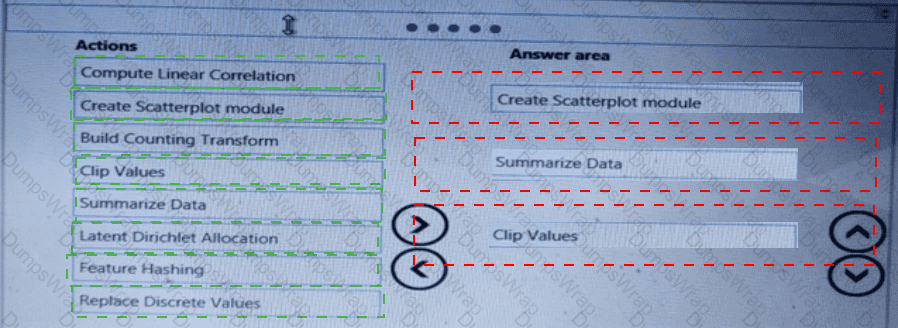
You need to correct the model fit issue.
Which three actions should you perform in sequence? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order.

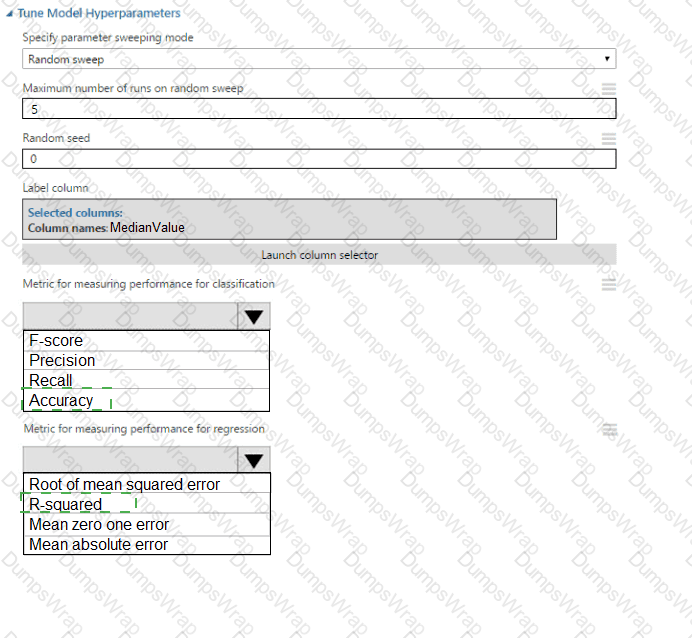
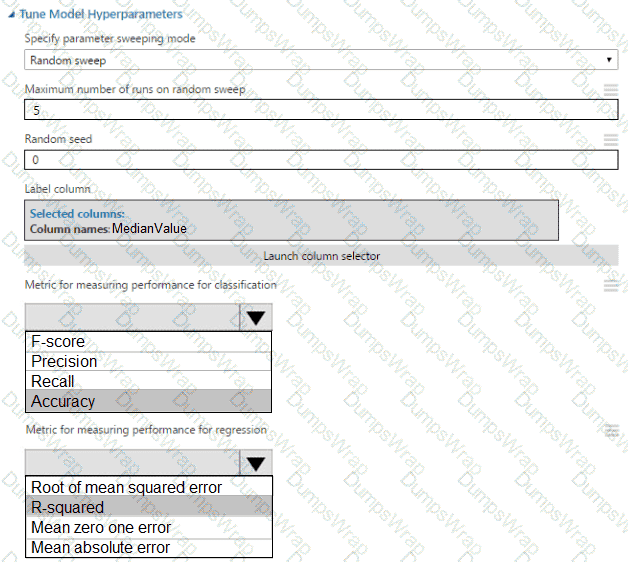
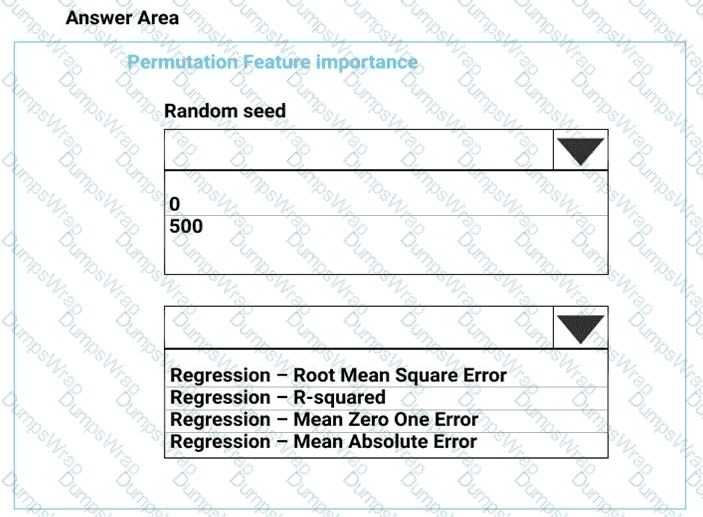
You need to set up the Permutation Feature Importance module according to the model training requirements.
Which properties should you select? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
You need to identify the methods for dividing the data according, to the testing requirements.
Which properties should you select? To answer, select the appropriate option-, m the answer area. NOTE: Each correct selection is worth one point.
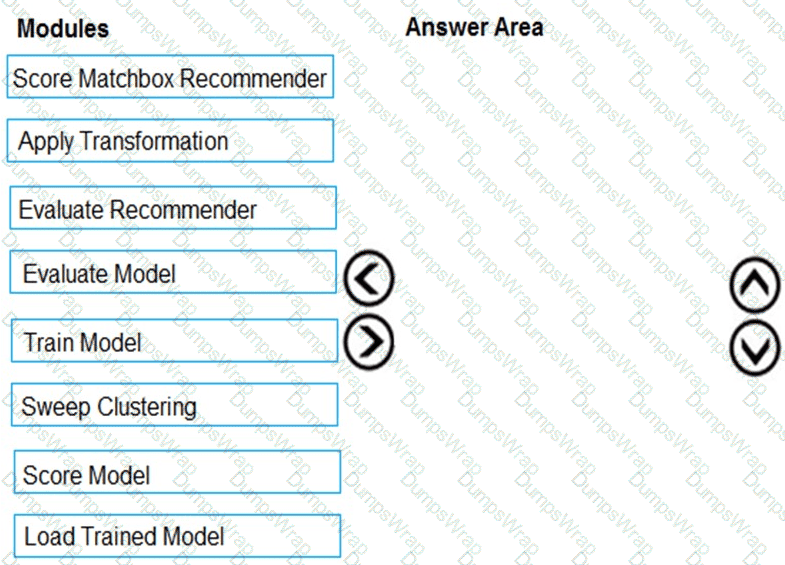
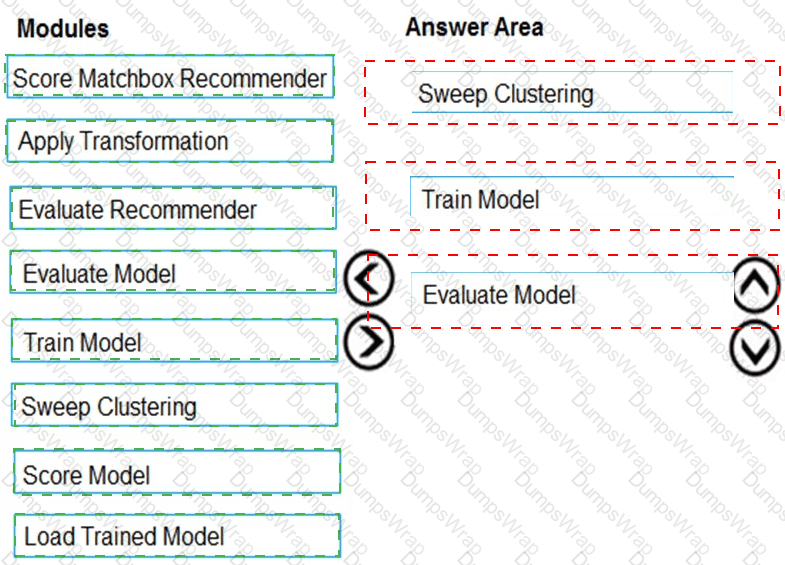
You need to produce a visualization for the diagnostic test evaluation according to the data visualization requirements.
Which three modules should you recommend be used in sequence? To answer, move the appropriate modules from the list of modules to the answer area and arrange them in the correct order.

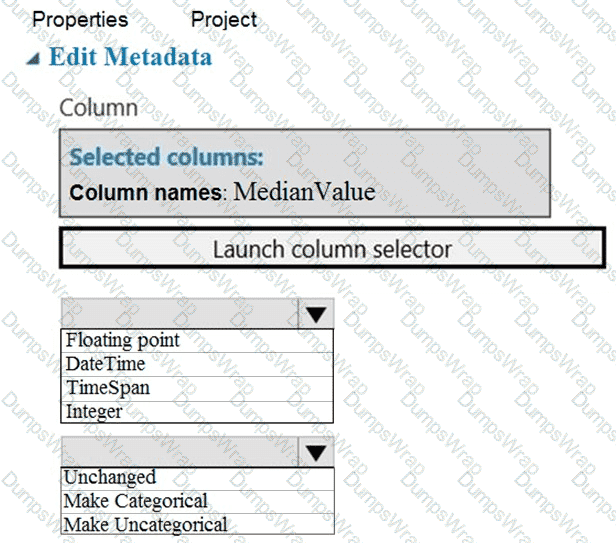
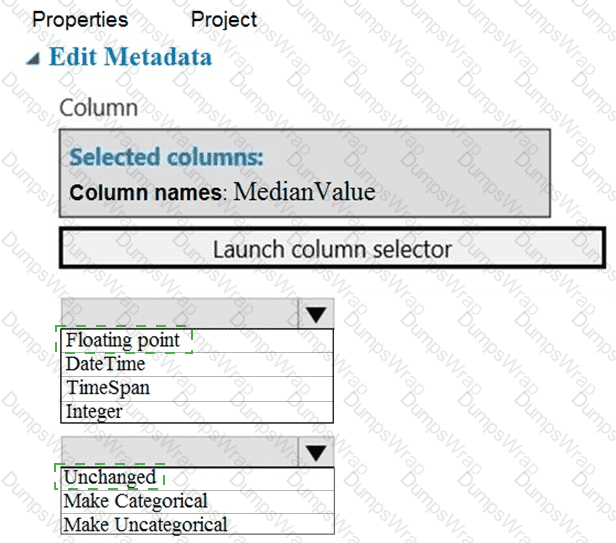
You need to configure the Edit Metadata module so that the structure of the datasets match.
Which configuration options should you select? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
You need to visually identify whether outliers exist in the Age column and quantify the outliers before the outliers are removed.
Which three Azure Machine Learning Studio modules should you use in sequence? To answer, move the appropriate modules from the list of modules to the answer area and arrange them in the correct order.

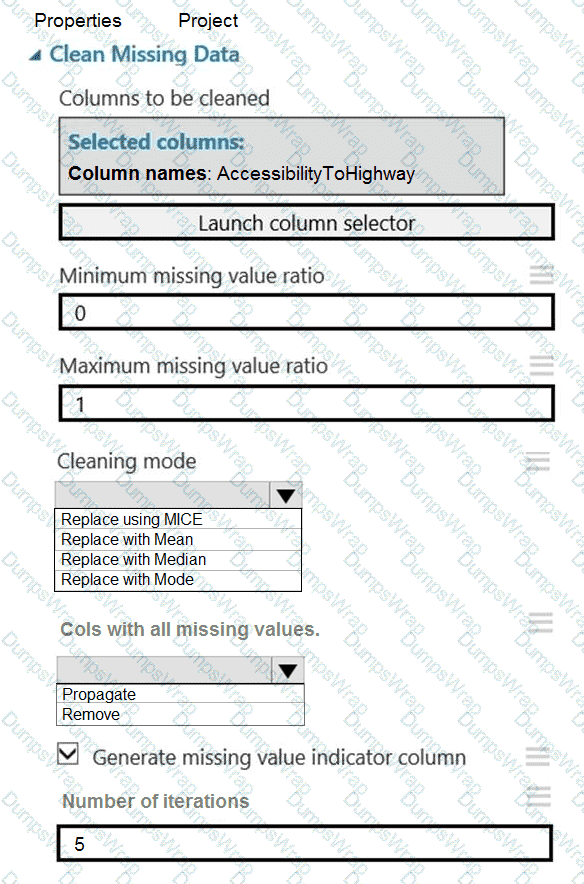
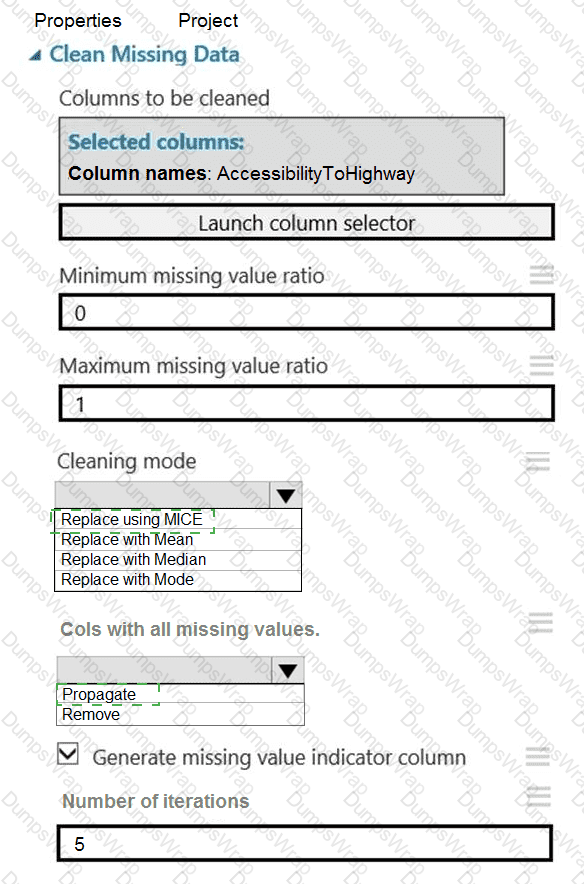
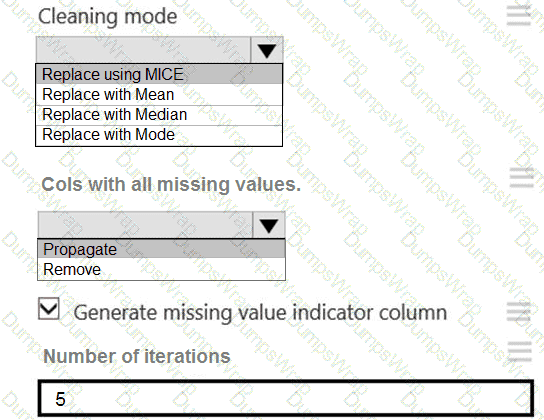
You need to replace the missing data in the AccessibilityToHighway columns.
How should you configure the Clean Missing Data module? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
You need to select a feature extraction method.
Which method should you use?
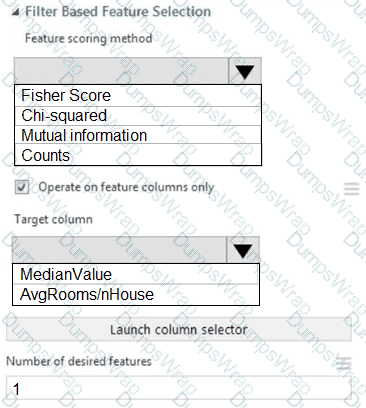
You need to configure the Feature Based Feature Selection module based on the experiment requirements and datasets.
How should you configure the module properties? To answer, select the appropriate options in the dialog box in the answer area.
NOTE: Each correct selection is worth one point.
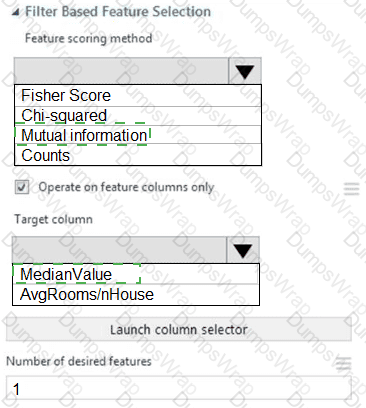
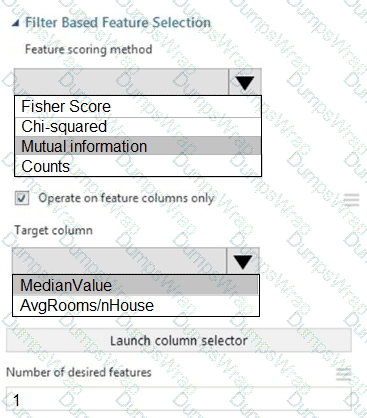
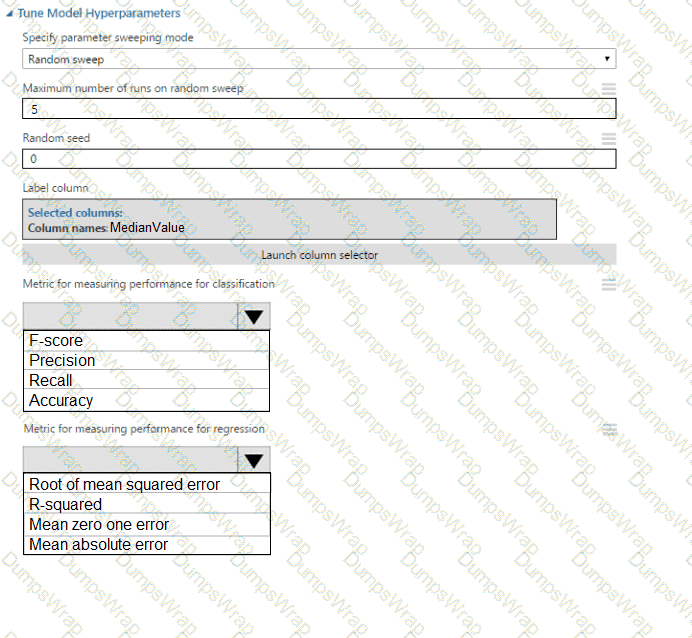
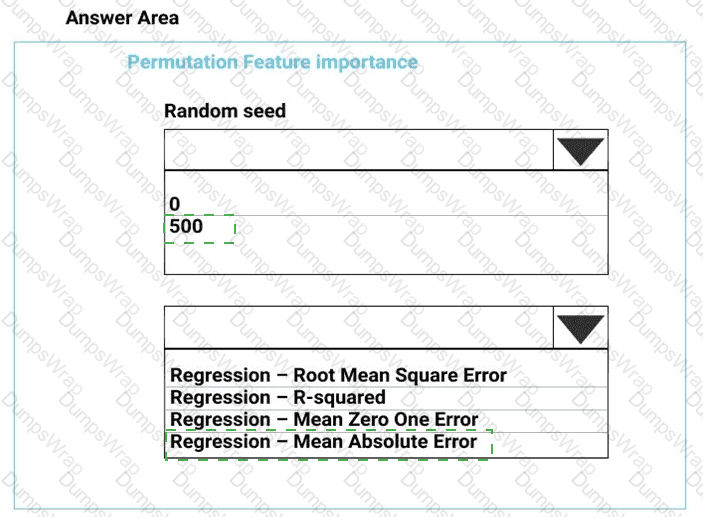
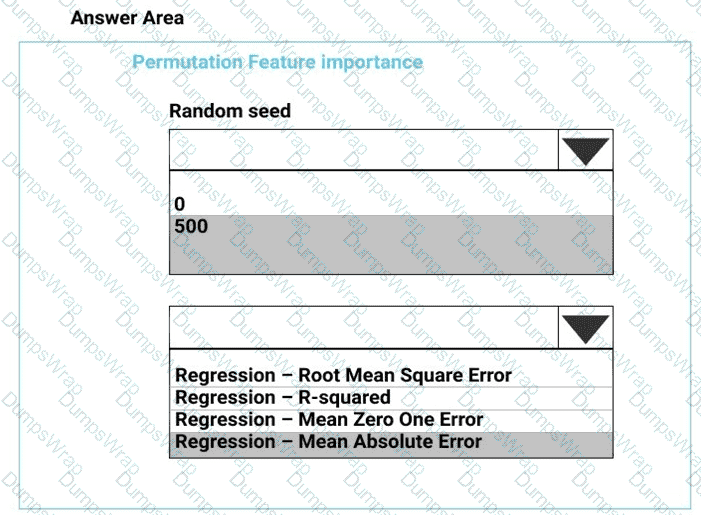
You need to configure the Permutation Feature Importance module for the model training requirements.
What should you do? To answer, select the appropriate options in the dialog box in the answer area.
NOTE: Each correct selection is worth one point.
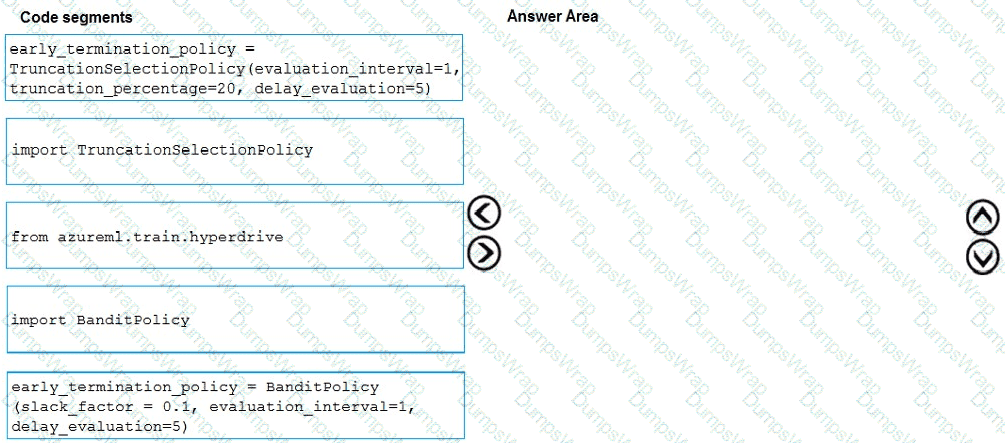
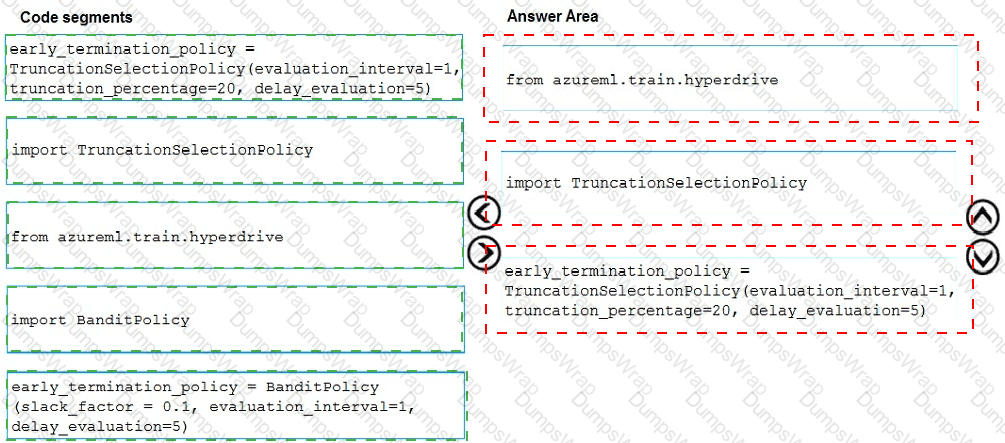
You need to implement early stopping criteria as suited in the model training requirements.
Which three code segments should you use to develop the solution? To answer, move the appropriate code segments from the list of code segments to the answer area and arrange them in the correct order.
NOTE: More than one order of answer choices is correct. You will receive credit for any of the correct orders you select.

You manage an Azure Machine Learning workspace.
You must provide explanations for the behavior of the models with feature importance measures.
You need to configure a Responsible Al dashboard in Azure Machine Learning.
Which dashboard component should you configure?
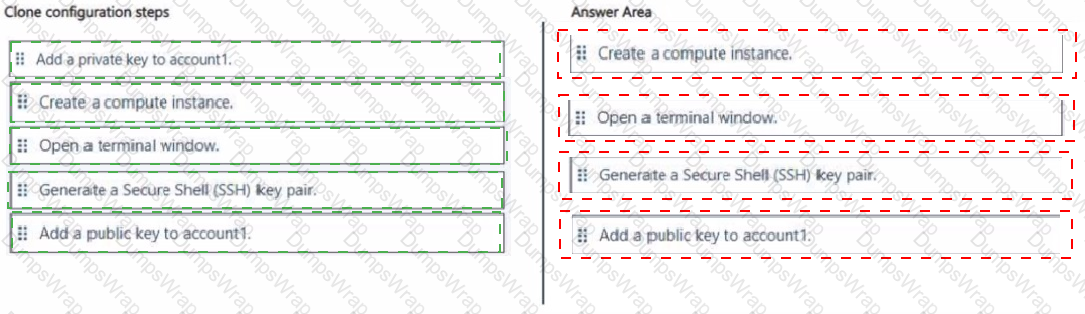
You have an Azure Machine Learning workspace named WS1 and a GitHub account named accountl that hosts a private repository named rapot You need to clone repol to make it available directly from WS1. The configuration must maximize the performance of the repol clone. Which four anions should you perform in sequence?

You create a script that trains a convolutional neural network model over multiple epochs and logs the validation loss after each epoch. The script includes arguments for batch size and learning rate.
You identify a set of batch size and learning rate values that you want to try.
You need to use Azure Machine Learning to find the combination of batch size and learning rate that results in the model with the lowest validation loss.
What should you do?
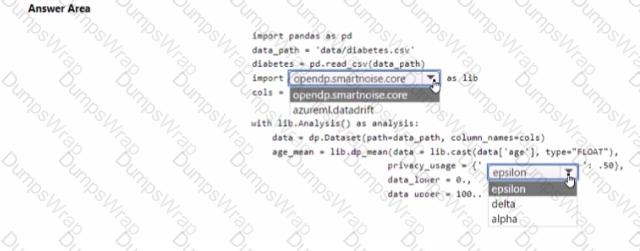
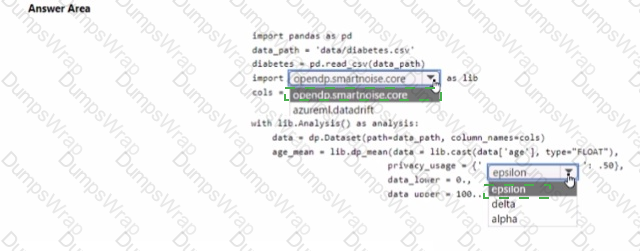
You are developing code to analyse a dataset that includes age information for a large group of diabetes patients. You create an Azure Machine Learning workspace and install all required libraries. You set the privacy budget to 1.0).
You must analyze the dataset and preserve data privacy. The code must run twice before the privacy budget is depleted.
You need to complete the code.
Which values should you use? To answer, select the appropriate options m the answer area.
NOTE: Each correct selection is worth one point.
You have the following Azure subscriptions and Azure Machine Learning service workspaces:

You need to obtain a reference to the mi-protect workspace
Solution: Run the following Python code.
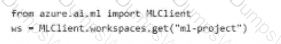
Does the solution meet the goal?
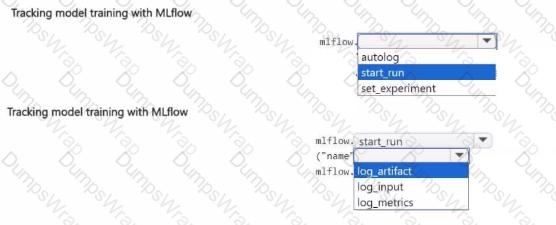
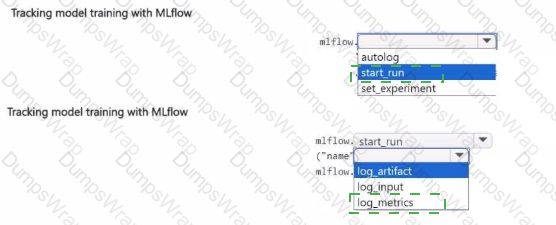
You manage an Azure Machine Learning workspace.
You train a model interactively with a Jupyter Notebook in the workspace During training, a dataset is created with accuiacy and loss metrics for each epoch.
You need to configure model tracking with MLflow to log the dataset created during the training.
How should you complete the code segment? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
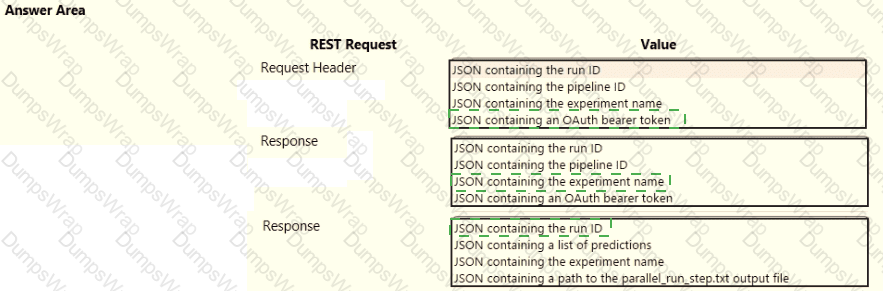
You publish a batch inferencing pipeline that will be used by a business application.
The application developers need to know which information should be submitted to and returned by the REST interface for the published pipeline.
You need to identify the information required in the REST request and returned as a response from the published pipeline.
Which values should you use in the REST request and to expect in the response? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.


You manage an Azure Machine Learning workspace. The development environment for managing the workspace is configured to use Python SDK v2 in Azure Machine Learning Notebooks
A Synapse Spark Compute is currently attached and uses system-assigned identity
You need to use Python code to update the Synapse Spark Compute to use a user-assigned identity.
Solution: Create an instance of the MICIient class.
Does the solution meet the goal?
You use the following code to define the steps for a pipeline:
from azureml.core import Workspace, Experiment, Run
from azureml.pipeline.core import Pipeline
from azureml.pipeline.steps import PythonScriptStep
ws = Workspace.from_config()
. . .
step1 = PythonScriptStep(name= " step1 " , ...)
step2 = PythonScriptsStep(name= " step2 " , ...)
pipeline_steps = [step1, step2]
You need to add code to run the steps.
Which two code segments can you use to achieve this goal? Each correct answer presents a complete solution.
NOTE: Each correct selection is worth one point.
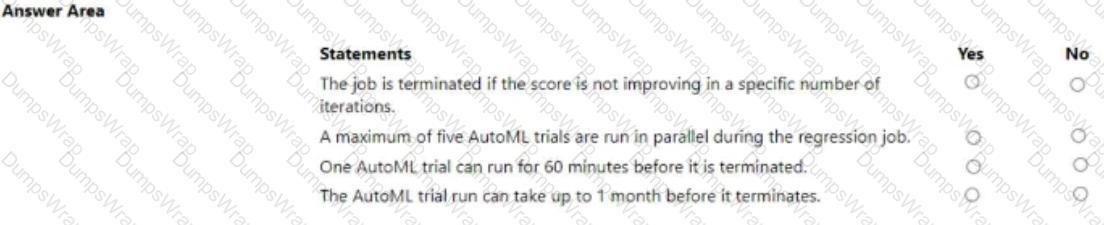
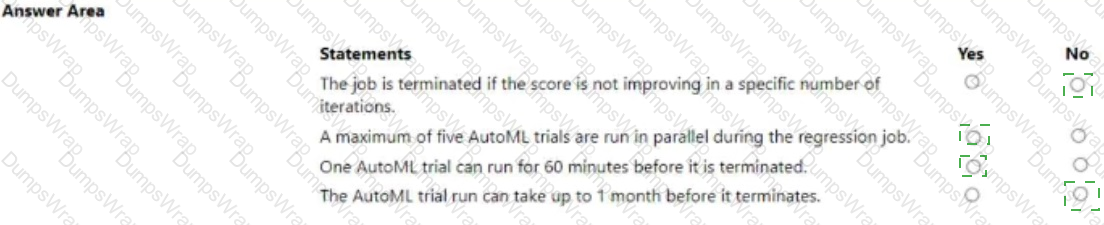
You manage an Azure Machine Learning workspace. You configure an automated machine learning regression training job by using the Azure Machine Learning Python SDK v2. You configure the regression job by using the following script:

For each of the following statements, select Yes if the statement is true. Otherwise, select No.
: 215
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution.
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
You train a classification model by using a logistic regression algorithm.
You must be able to explain the model’s predictions by calculating the importance of each feature, both as an overall global relative importance value and as a measure of local importance for a specific set of predictions.
You need to create an explainer that you can use to retrieve the required global and local feature importance values.
Solution: Create a MimicExplainer.
Does the solution meet the goal?
You use the Azure Machine Learning Python SDK to create a batch inference pipeline.
You must publish the batch inference pipeline so that business groups in your organization can use the pipeline. Each business group must be able to specify a different location for the data that the pipeline submits to the model for scoring.
You need to publish the pipeline.
What should you do?
You use the Azure Machine Learning Python SDK to define a pipeline to train a model.
The data used to train the model is read from a folder in a datastore.
You need to ensure the pipeline runs automatically whenever the data in the folder changes.
What should you do?
You have an Azure Machine Learning workspace.
You plan to tune a model hyperparameter when you train the model.
You need to define a search space that returns a normally distributed value.
Which parameter should you use?
You are creating a classification model for a banking company to identify possible instances of credit card fraud. You plan to create the model in Azure Machine Learning by using automated machine learning.
The training dataset that you are using is highly unbalanced.
You need to evaluate the classification model.
Which primary metric should you use?
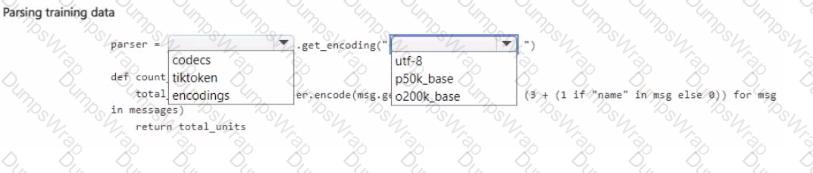
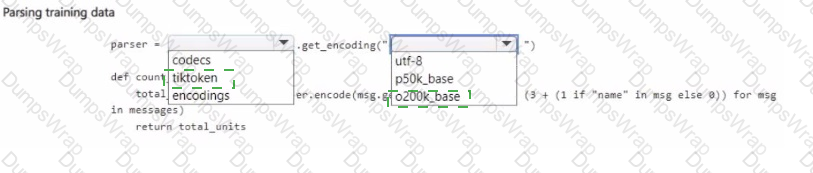
You manage an Azure OpenAI Service deployment of the gpt-4o-mini base model.
You plan to fine-tune the deployed model by using OpenAI Python la code. In the code, you import all required Python libraries and create a sample training data set.
You need to complete the next section of the code to estimate the cost of fine-tuning by using the sample training data set.
How should you complete the code section? To answer, select the appropnate options in the answer area.
NOTE: Each correct selection is worth one point.
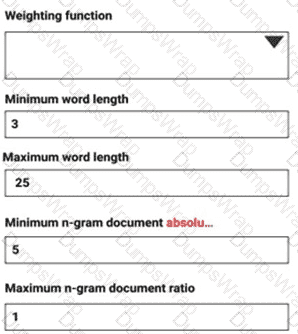
You are performing sentiment analysis using a CSV file that includes 12,000 customer reviews written in a short sentence format. You add the CSV file to Azure Machine Learning Studio and configure it as the starting point dataset of an experiment. You add the Extract N-Gram Features from Text module to the experiment to extract key phrases from the customer review column in the dataset.
You must create a new n-gram dictionary from the customer review text and set the maximum n-gram size to trigrams.
What should you select? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.



You are designing an Azure Machine Learning solution.
The model must be trained by using automated machine learning. The compute must be a shared resource with users in the Azure Machine Learning workspace. After you train the model, it must be deployed for batch scoring on a serverless compute.
You need to select the appropriate computation options for the solution.
Which compute options should you select for training and deployment? To answer, move the appropriate compute options to the correct project activities. You may use each compute option once, more than once, or not at all. You may need to move the split bar between panes or scroll to view content
NOTE: Each correct selection is worth one point.


You manage an Azure Al Foundry project.
You plan to evaluate a fine-tuned large language model by doing the following:
• Identifying discrepancies between runs of the same model to pinpoint the areas where adjustments may be needed.
• Verifying the Al-generated responses align with and are validated by the provided context.
You need to identify an evaluation metric and a comparison feature to assess the performance of the model. Which assessment techniques should you use? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.


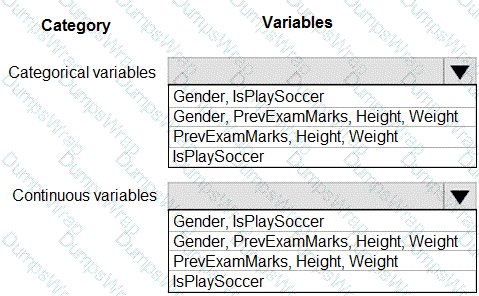
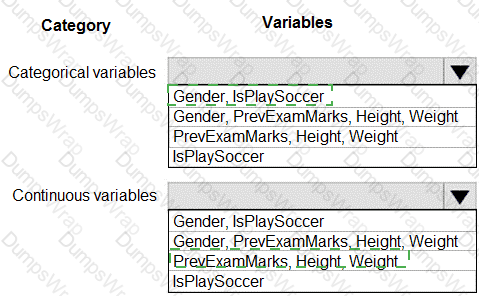
You are working on a classification task. You have a dataset indicating whether a student would like to play soccer and associated attributes. The dataset includes the following columns:
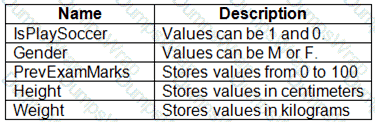
You need to classify variables by type.
Which variable should you add to each category? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution.
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
You train and register a machine learning model.
You plan to deploy the model as a real-time web service. Applications must use key-based authentication to use the model.
You need to deploy the web service.
Solution:
Create an AksWebservice instance.
Set the value of the auth_enabled property to True.
Deploy the model to the service.
Does the solution meet the goal?
You manage an Azure Machine Learning workspace. You plan to import data from Azure Data Lake Storage Gen2. You need to build a URI that represents the storage location. Which protocol should you use?
You are preparing to use the Azure ML SDK to run an experiment and need to create compute. You run the following code:
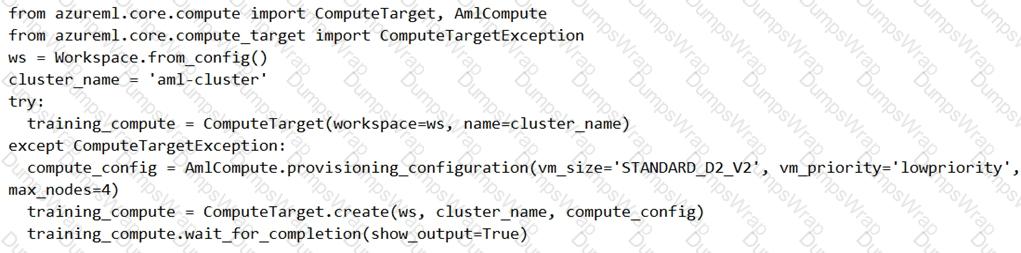
For each of the following statements, select Yes if the statement is true. Otherwise, select No.
NOTE: Each correct selection is worth one point.



You manage an Azure Machine Learning workspace. You submit a training job with the Azure Machine Learning Python SDK v2. You must use MLflow to log metrics, model parameters, and model artifacts automatically when training a model.
You start by writing the following code segment:

For each of the following statements, select Yes If the statement is true. Otherwise, select No.


You create a workspace by using Azure Machine Learning Studio.
You must run a Python SDK v2 notebook in the workspace by using Azure Machine Learning Studio. You must preserve the current values of variables set in the notebook for the current instance.
You need to maintain the state of the notebook.
What should you do?
You have an Azure Machine Learning workspace named Workspace 1 Workspace! has a registered Mlflow model named model 1 with PyFunc flavor
You plan to deploy model1 to an online endpoint named endpoint1 without egress connectivity by using Azure Machine learning Python SDK vl
You have the following code:
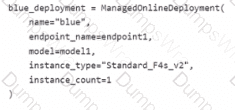
You need to add a parameter to the ManagedOnllneDeployment object to ensure the model deploys successfully
Solution: Add the scoring_script parameter.
Does the solution meet the goal?
You manage an Azure Machine Learning workspace.
You choose the urijolder data type as an output of a pipeline component.
You need to define the data access mode that is supported by your configuration.
Which mode should you define?
You are a data scientist working for a bank and have used Azure ML to train and register a machine learning model that predicts whether a customer is likely to repay a loan.
You want to understand how your model is making selections and must be sure that the model does not violate government regulations such as denying loans based on where an applicant lives.
You need to determine the extent to which each feature in the customer data is influencing predictions.
What should you do?
You design a project for interactive data mangling with Apache Spark in an Azure Machine Learning workspace. The data pipeline must provide the following solution:
• Ingest and process a vast amount of data from various sources and linked services, such as databases and APIs
• Visualize the results in Microsoft Power Bl.
• Include a possibility to quickly identify and address issues by observing only a small amount of data using the fewest resources.
You need to select a computation option for project activities.


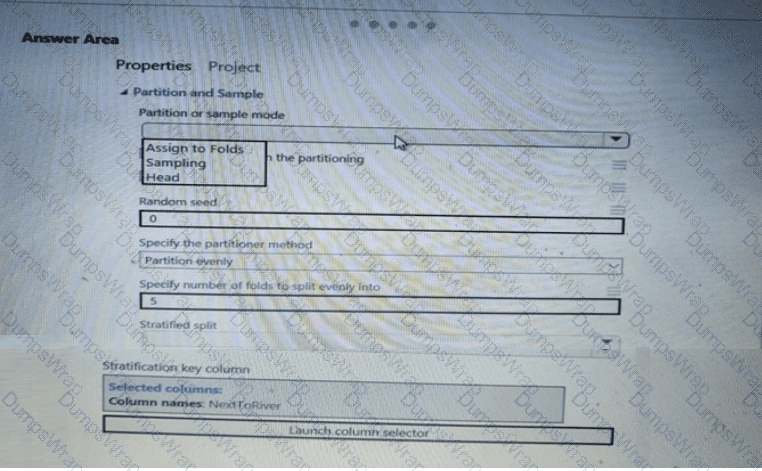
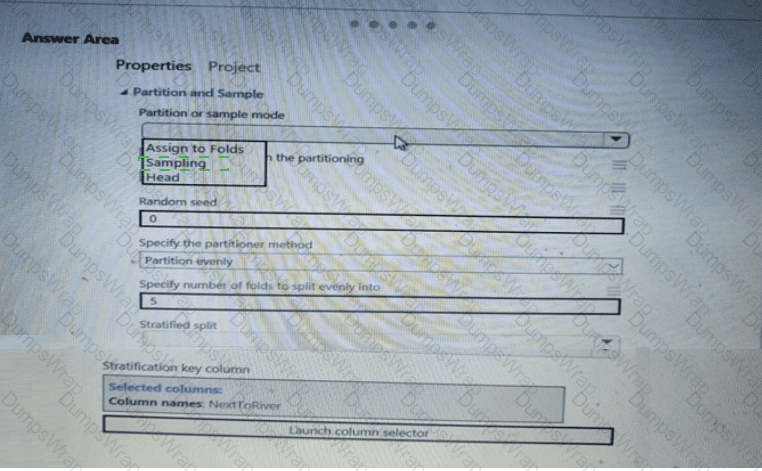
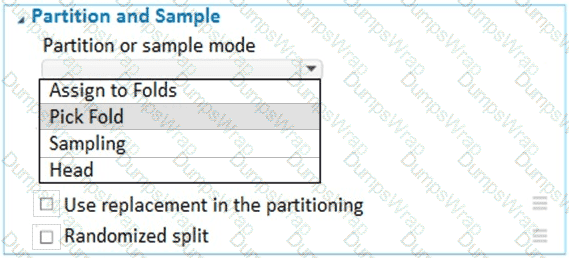
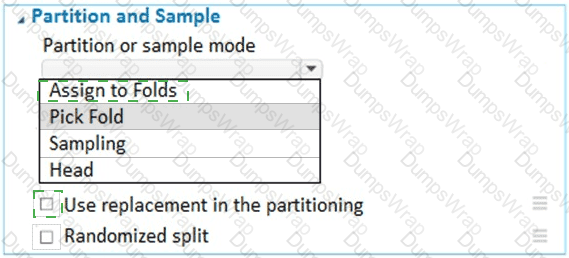
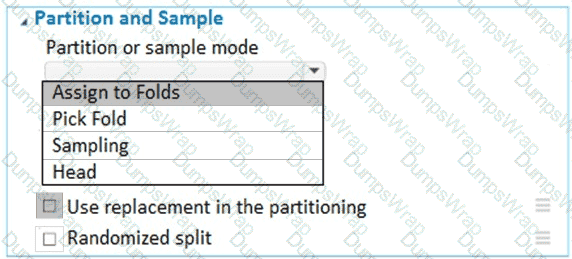
You have a dataset that contains 2,000 rows. You are building a machine learning classification model by using Azure Learning Studio. You add a Partition and Sample module to the experiment.
You need to configure the module. You must meet the following requirements:
Divide the data into subsets
Assign the rows into folds using a round-robin method
Allow rows in the dataset to be reused
How should you configure the module? To answer, select the appropriate options in the dialog box in the answer area.
NOTE: Each correct selection is worth one point.
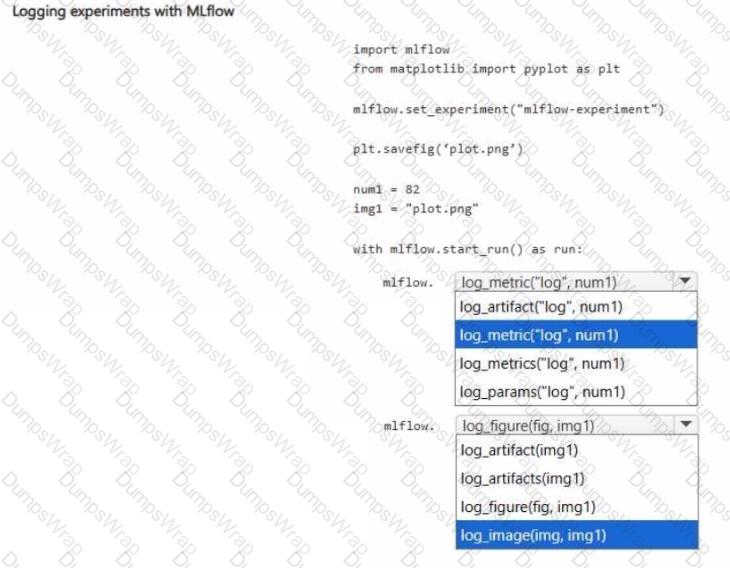
You have an Azure Machine Learning workspace.
You plan to set up logging and tracking experiments by using MLflow Tracking.
You need to log the accuracy as a numerical value and the training loss as a plot.
How should you complete the commands? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.

You create an Azure Machine learning workspace. The workspace contains a folder named src. The folder contains a Python script named script 1 .py.
You use the Azure Machine Learning Python SDK v2 to create a control script. You must use the control script to run script l.py as part of a training job.
You need to complete the section of script that defines the job parameters.
How should you complete the script? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.


You use Azure Machine Learning designer to create a real-time service endpoint. You have a single Azure Machine Learning service compute resource. You train the model and prepare the real-time pipeline for deployment You need to publish the inference pipeline as a web service. Which compute type should you use?
You are building a regression model tot estimating the number of calls during an event.
You need to determine whether the feature values achieve the conditions to build a Poisson regression model.
Which two conditions must the feature set contain? I ach correct answer presents part of the solution. NOTE: Each correct selection is worth one point.
You create a workspace by using Azure Machine Learning Studio.
You must run a Python SDK v2 notebook in the workspace by using Azure Machine Learning Studio.
You need to reset the state of the notebook.
Which three actions should you use? Each correct answer presents a complete solution.
NOTE: Each correct selection is worth one point.
You have an Azure Machine Learning workspace named Workspace 1 Workspace! has a registered Mlflow model named model 1 with PyFunc flavor
You plan to deploy model1 to an online endpoint named endpointl without egress connectivity by using Azure Machine learning Python SDK vl
You have the following code:
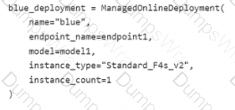
You need to add a parameter to the ManagedOnllneDeployment object to ensure the model deploys successfully
Solution: Add the with_package parameter.
Does the solution meet the goal?
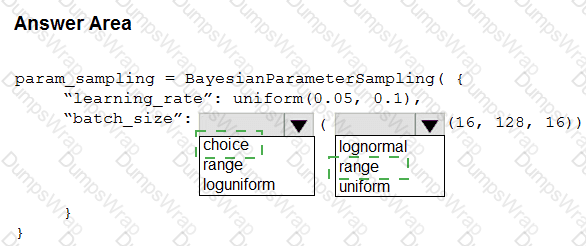
You are implementing hyperparameter tuning for a model training from a notebook. The notebook is in an Azure Machine Learning workspace. You add code that imports all relevant Python libraries.
You must configure Bayesian sampling over the search space for the num_hidden_layers and batch_size hyperparameters.
You need to complete the following Python code to configure Bayesian sampling.
Which code segments should you use? To answer, select the appropriate options in the answer area
NOTE: Each correct selection is worth one point.

Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution.
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
You are using Azure Machine Learning to run an experiment that trains a classification model.
You want to use Hyperdrive to find parameters that optimize the AUC metric for the model. You configure a HyperDriveConfig for the experiment by running the following code:

variable named y_test variable, and the predicted probabilities from the model are stored in a variable named y_predicted. You need to add logging to the script to allow Hyperdrive to optimize hyperparameters for the AUC metric. Solution: Run the following code:

Does the solution meet the goal?
You manage an Azure Machine Learning workspace. You develop a regression model training pipeline by using Notebooks. You need to determine the appropriate evaluation metric for the experiment.
Which two metrics should you choose? Each correct answer presents a complete solution. Choose two. NOTE: Each correct selection is worth one point.
You manage an Azure Al Foundry project.
You plan 10 build a RAG solution. The solution must include two models:
• One for text output, named Model1. This model must resemble human language and read naturally.
• One for creating embeddings, named Model2. This model must maximize the retrieval of relevant results (high recall)
You need to compare different models by using benchmarking metrics to select the appropriate models for Model1 and Model?


You need to resolve the local machine learning pipeline performance issue. What should you do?
You need to define an evaluation strategy for the crowd sentiment models.
Which three actions should you perform in sequence? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order.

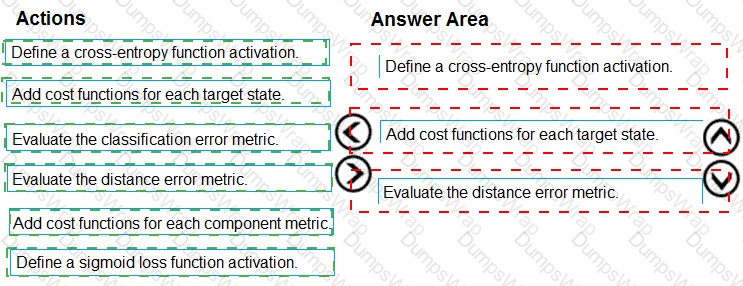

You need to define an evaluation strategy for the crowd sentiment models.
Which three actions should you perform in sequence? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order.

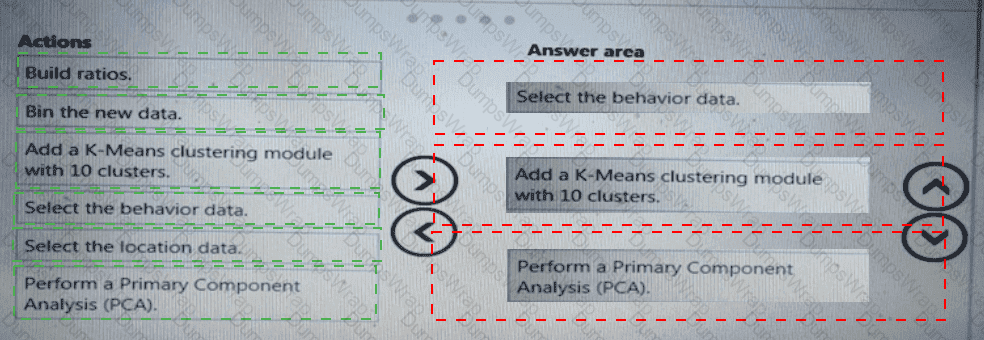
You need to define a process for penalty event detection.
Which three actions should you perform in sequence? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order.
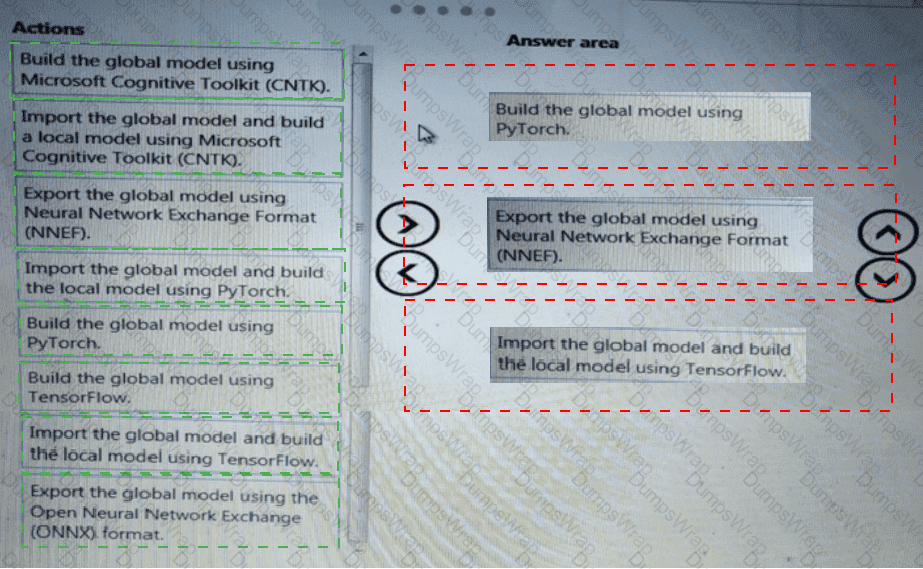
You need to define a modeling strategy for ad response.
Which three actions should you perform in sequence? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order.
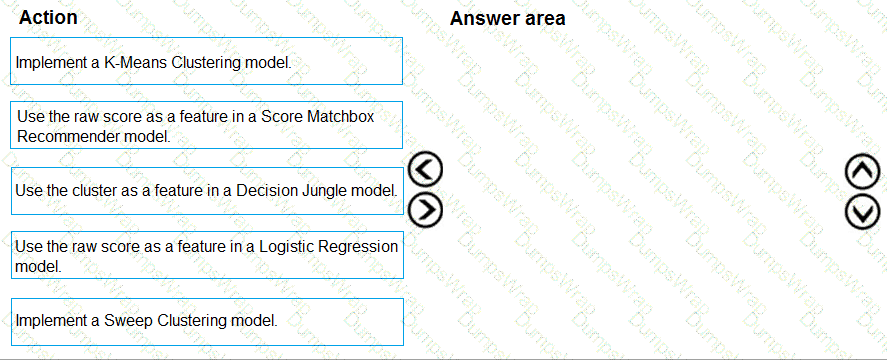
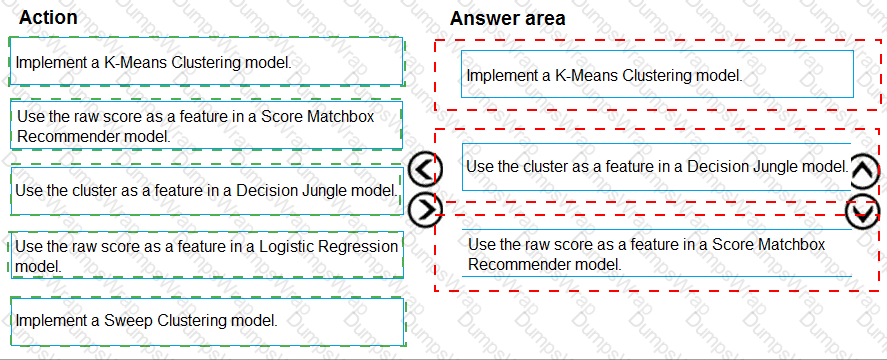

You need to select an environment that will meet the business and data requirements.
Which environment should you use?
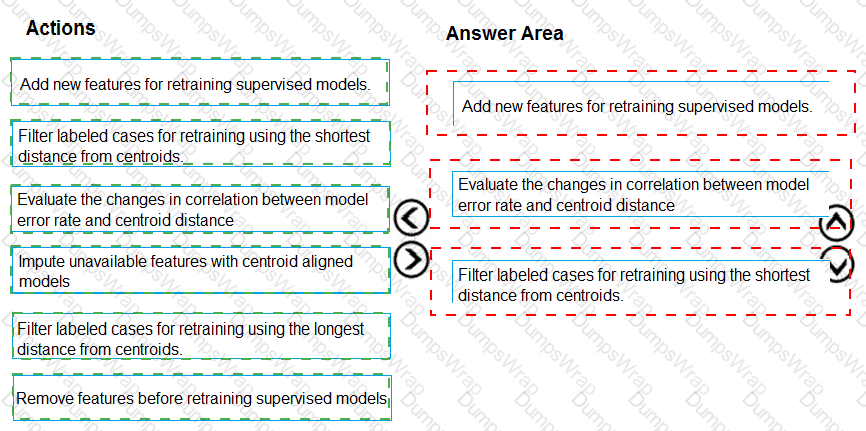
You need to define a process for penalty event detection.
Which three actions should you perform in sequence? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order.
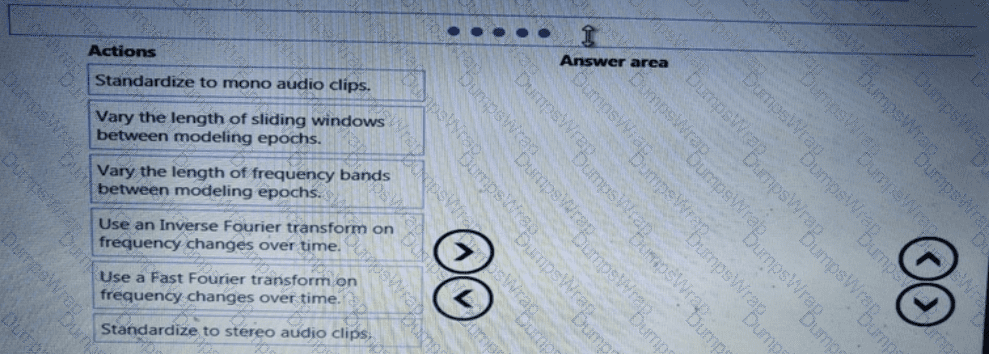
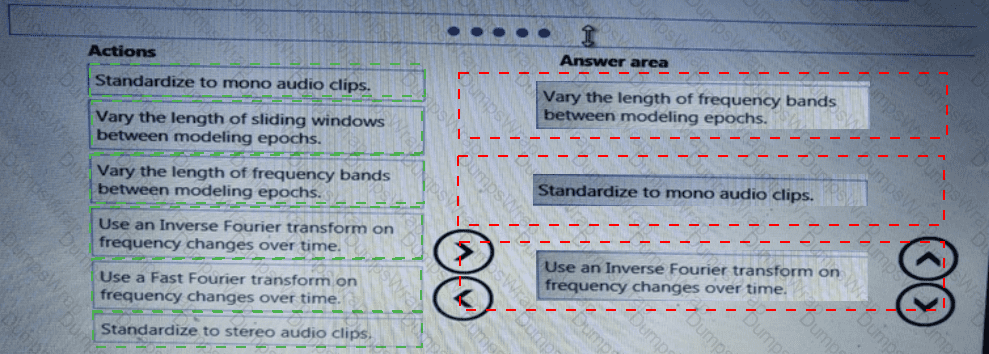
You need to modify the inputs for the global penalty event model to address the bias and variance issue.
Which three actions should you perform in sequence? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order.

You need to implement a new cost factor scenario for the ad response models as illustrated in the
performance curve exhibit.
Which technique should you use?

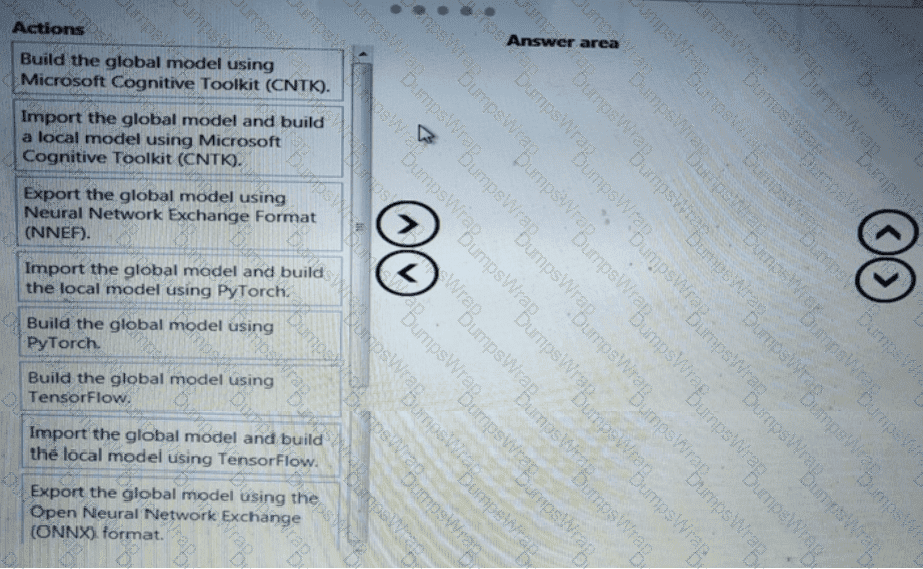
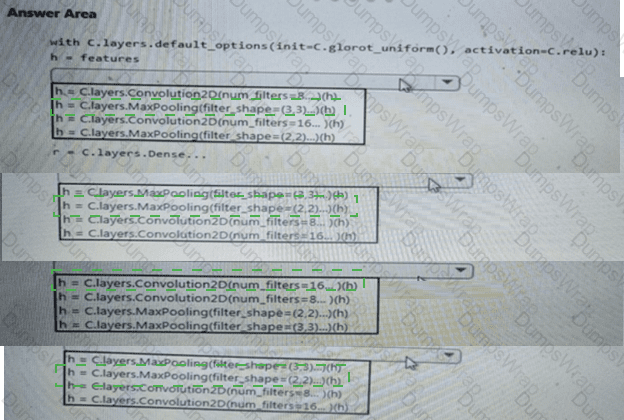
You need to build a feature extraction strategy for the local models.
How should you complete the code segment? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.

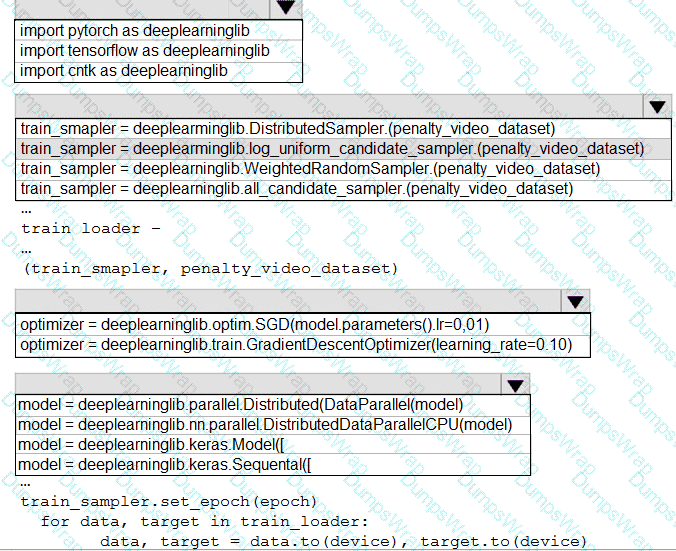
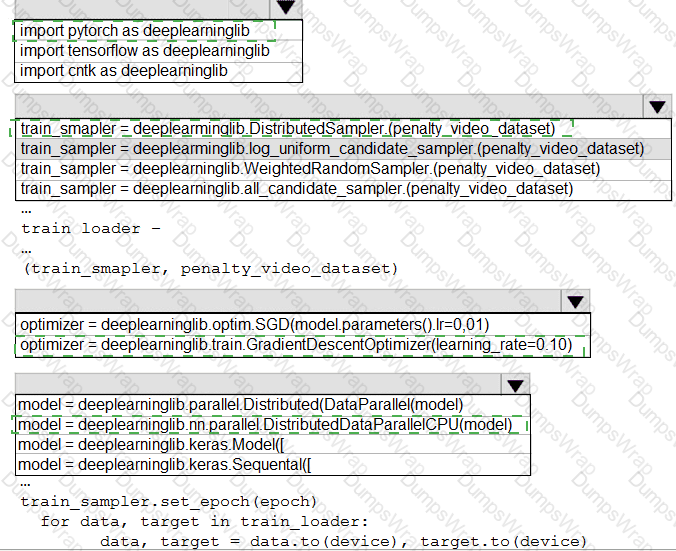
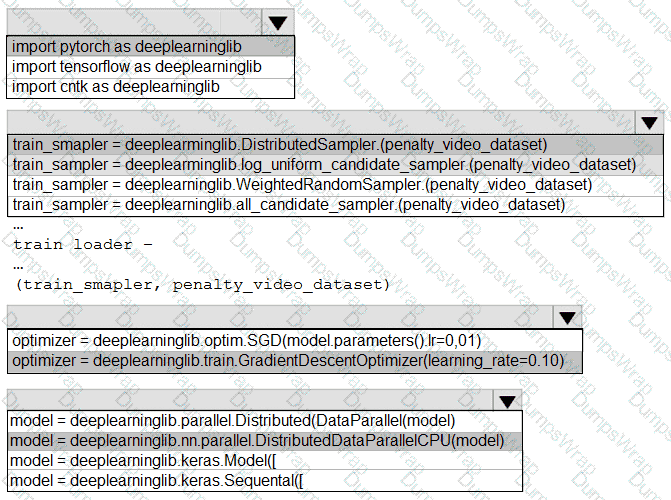
You need to use the Python language to build a sampling strategy for the global penalty detection models.
How should you complete the code segment? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
You need to implement a scaling strategy for the local penalty detection data.
Which normalization type should you use?
You need to implement a feature engineering strategy for the crowd sentiment local models.
What should you do?
You need to implement a model development strategy to determine a user’s tendency to respond to an ad.
Which technique should you use?
