Implementing Data Engineering Solutions Using Microsoft Fabric Questions and Answers
You need to ensure that the data analysts can access the gold layer lakehouse.
What should you do?
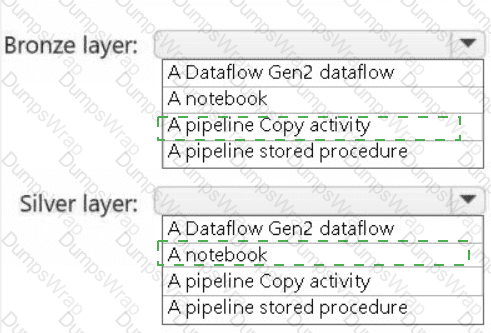
You need to recommend a method to populate the POS1 data to the lakehouse medallion layers.
What should you recommend for each layer? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.

 A screenshot of a computer Description automatically generated
A screenshot of a computer Description automatically generatedYou need to populate the MAR1 data in the bronze layer.
Which two types of activities should you include in the pipeline? Each correct answer presents part of the solution.
NOTE: Each correct selection is worth one point.
You need to recommend a solution for handling old files. The solution must meet the technical requirements. What should you include in the recommendation?
You need to recommend a solution to resolve the MAR1 connectivity issues. The solution must minimize development effort. What should you recommend?
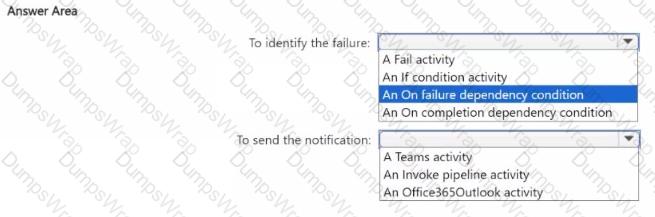
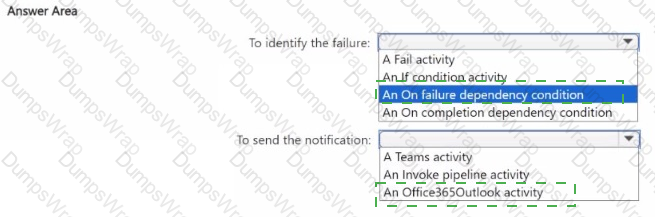
You need to ensure that the data engineers are notified if any step in populating the lakehouses fails. The solution must meet the technical requirements and minimize development effort.
What should you use? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
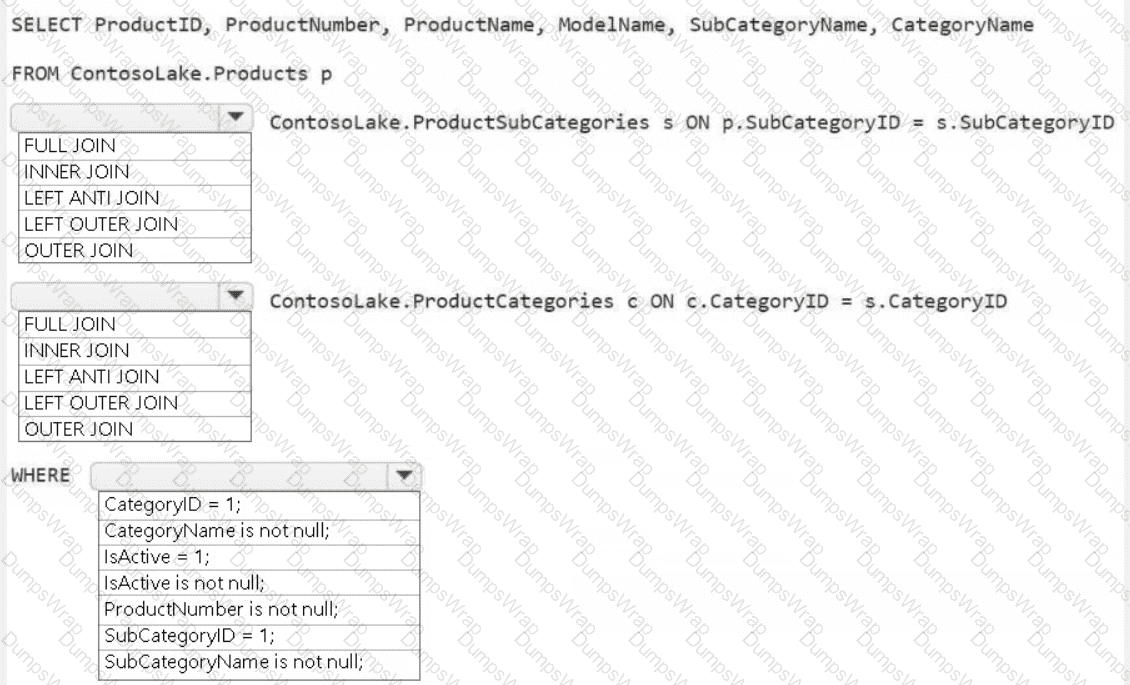
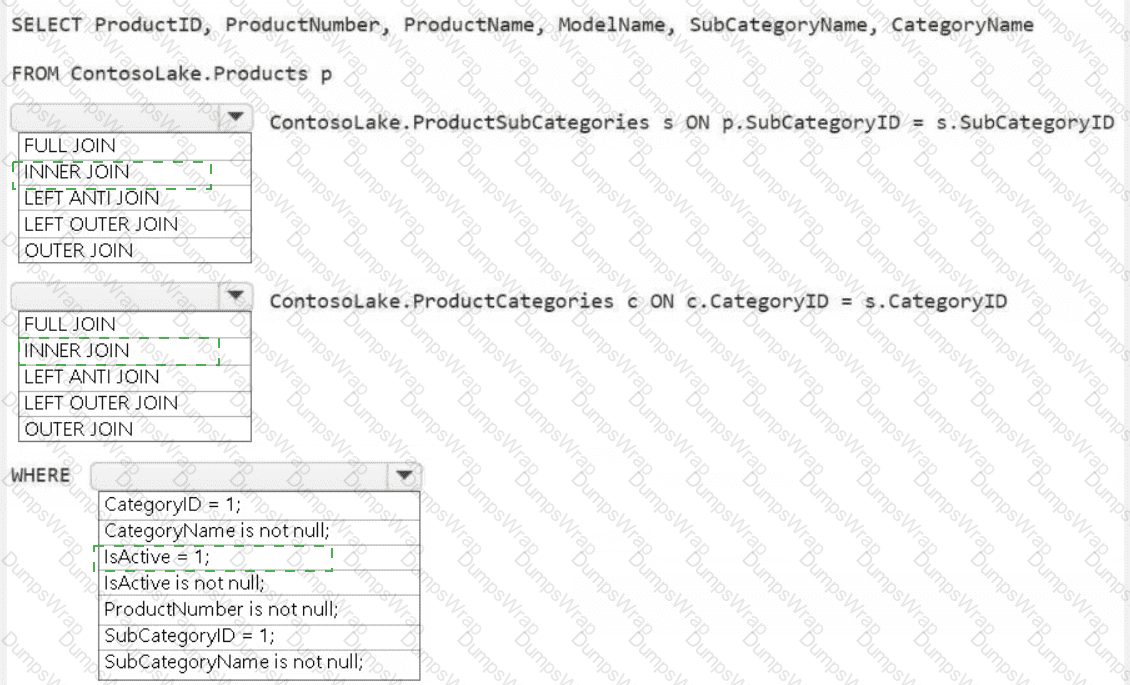
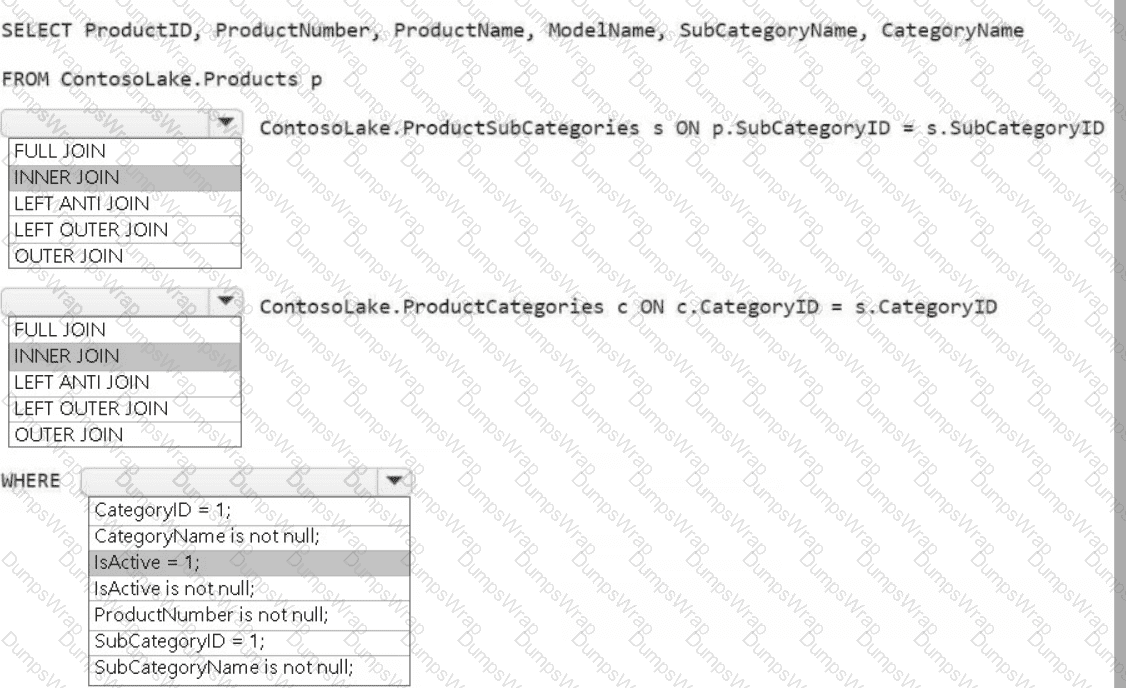
You need to create the product dimension.
How should you complete the Apache Spark SQL code? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
 A screenshot of a computer Description automatically generated
A screenshot of a computer Description automatically generatedYou need to schedule the population of the medallion layers to meet the technical requirements.
What should you do?
You need to ensure that WorkspaceA can be configured for source control. Which two actions should you perform?
Each correct answer presents part of the solution. NOTE: Each correct selection is worth one point.
You need to ensure that usage of the data in the Amazon S3 bucket meets the technical requirements.
What should you do?
You need to ensure that processes for the bronze and silver layers run in isolation How should you configure the Apache Spark settings?
You need to resolve the sales data issue. The solution must minimize the amount of data transferred.
What should you do?
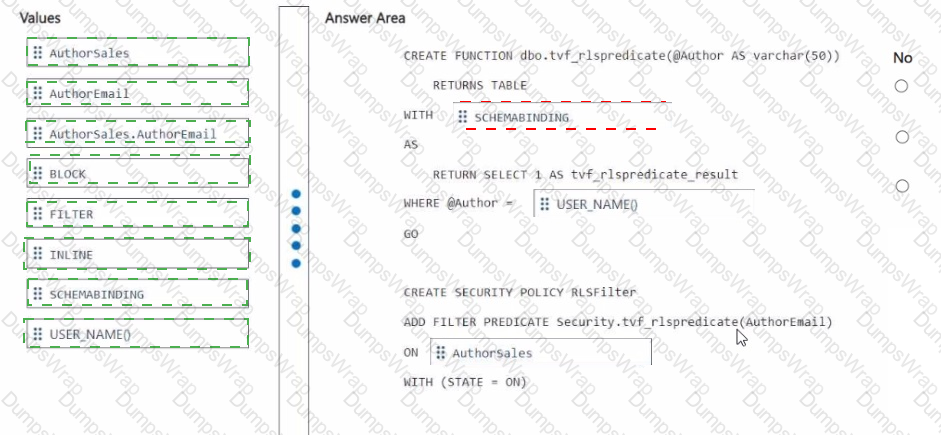
You need to ensure that the authors can see only their respective sales data.
How should you complete the statement? To answer, drag the appropriate values the correct targets. Each value may be used once, more than once, or not at all. You may need to drag the split bar between panes or scroll to view content
NOTE: Each correct selection is worth one point.

You have an Azure event hub. Each event contains the following fields:
BikepointID
Street
Neighbourhood
Latitude
Longitude
No_Bikes
No_Empty_Docks
You need to ingest the events. The solution must only retain events that have a Neighbourhood value of Chelsea, and then store the retained events in a Fabric lakehouse.
What should you use?
You have a Fabric workspace that contains a warehouse named Warehouse1.
You have an on-premises Microsoft SQL Server database named Database1 that is accessed by using an on-premises data gateway.
You need to copy data from Database1 to Warehouse1.
Which item should you use?
You have a Microsoft Power Apps app named App1 that has data stored in Microsoft Dataverse. You need to access the App1 data by using Fabric. What should you use?
You have a Fabric workspace that contains an eventstream named EventStream1. EventStream1 outputs events to a table in a lakehouse.
You need to remove files that are older than seven days and are no longer in use.
Which command should you run?
You have a Fabric workspace that contains a warehouse named Warehouse1. Data is loaded daily into Warehouse1 by using data pipelines and stored procedures.
You discover that the daily data load takes longer than expected.
You need to monitor Warehouse1 to identify the names of users that are actively running queries.
Which view should you use?
You have a Fabric warehouse named Warehouse1 that contains a table named Table1. Table 1 has a column named EmailAddress. All users have access to Warehouse1.
You need to configure dynamic data masking for the EmailAddress column. The solution must meet the following requirements:
• The solution must NOT change the data in Warehouse1.
• The solution must NOT require changes to the queries that access Table1.
• The solution must NOT require changes to the security or permissions granted to Warehouse1.
What should you use?
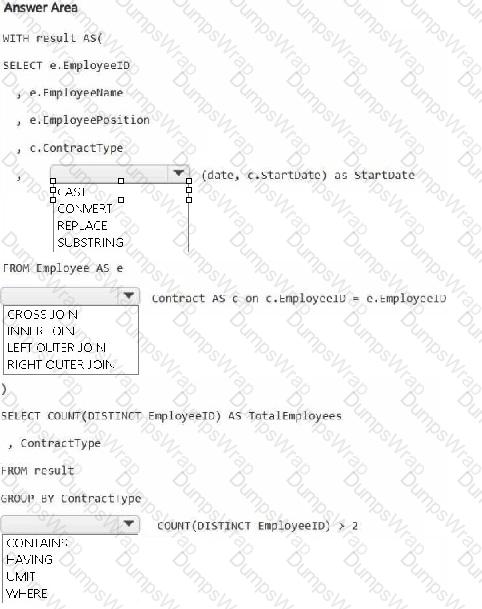
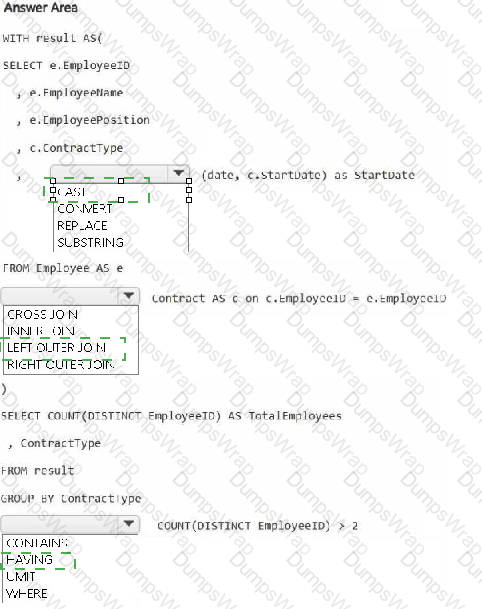
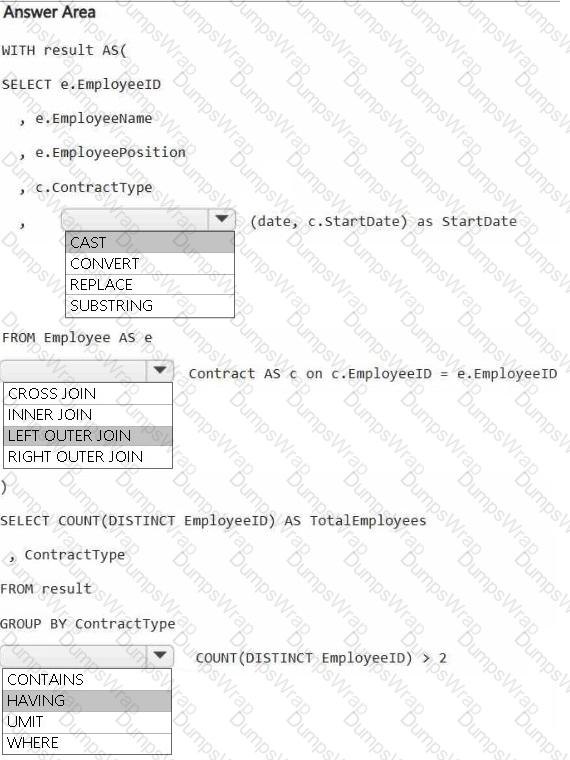
HOTSPOT
You have a Fabric workspace that contains a warehouse named Warehouse1. Warehouse1 contains the following tables and columns.
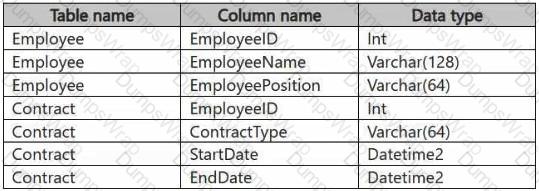
You need to denormalize the tables and include the ContractType and StartDate columns in the Employee table. The solution must meet the following requirements:
Ensure that the StartDate column is of the date data type.
Ensure that all the rows from the Employee table are preserved and include any matching rows from the Contract table.
Ensure that the result set displays the total number of employees per contract type for all the contract types that have more than two employees.
How should you complete the statement? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
 C:\Users\Waqas Shahid\Desktop\Mudassir\Untitled.jpg
C:\Users\Waqas Shahid\Desktop\Mudassir\Untitled.jpgYou have a Fabric workspace that contains a lakehouse named Lakehouse1. Data is ingested into Lakehouse1 as one flat table. The table contains the following columns.

You plan to load the data into a dimensional model and implement a star schema. From the original flat table, you create two tables named FactSales and DimProduct. You will track changes in DimProduct.
You need to prepare the data.
Which three columns should you include in the DimProduct table? Each correct answer presents part of the solution.
NOTE: Each correct selection is worth one point.
You have a Fabric workspace named Workspace1 that contains a lakehouse named Lakehouse1. You perform the following actions:
• Connect Workspace1 to a Git repository and select the main branch.
• Create a new branch named feature! and modify Lakehouse1.
• Merge the changes from feature1 into the main branch.
You need to ensure that the changes are available in Workspace1. The solution must minimize changes to Workspace1 What should you do?
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution.
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
You have a KQL database that contains two tables named Stream and Reference. Stream contains streaming data in the following format.
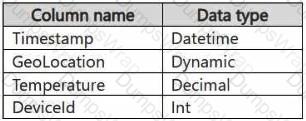
Reference contains reference data in the following format.

Both tables contain millions of rows.
You have the following KQL queryset.

You need to reduce how long it takes to run the KQL queryset.
Solution: You change project to extend.
Does this meet the goal?
You have a Fabric workspace that contains a lakehouse named Lakehouse1.
In an external data source, you have data files that are 500 GB each. A new file is added every day.
You need to ingest the data into Lakehouse1 without applying any transformations. The solution must meet the following requirements
Trigger the process when a new file is added.
Provide the highest throughput.
Which type of item should you use to ingest the data?
You have a Fabric data warehouse that contains the following tables.
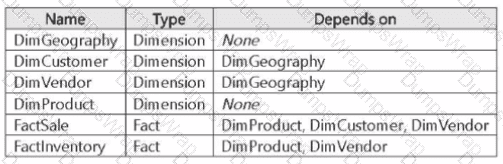
You need to refresh the tables by using an automated pipeline. The solution must ensure that table updates occur in the correct order to maintain referential integrity.
Which two tables should you refresh first? Each correct answer presents part of the solution.
NOTE: Each correct selection is worth one point.
You have an Azure Data Lake Storage Gen2 account named storage1 and an Amazon S3 bucket named storage2.
You have the Delta Parquet files shown in the following table.

You have a Fabric workspace named Workspace1 that has the cache for shortcuts enabled. Workspace1 contains a lakehouse named Lakehouse1. Lakehouse1 has the following shortcuts:
A shortcut to ProductFile aliased as Products
A shortcut to StoreFile aliased as Stores
A shortcut to TripsFile aliased as Trips
The data from which shortcuts will be retrieved from the cache?
