Implementing Data Engineering Solutions Using Azure Databricks Questions and Answers
You need to complete the PySpark code for the Spark Structured Streaming pipelines. The solution must meet the data ingestion and processing requirements.
How should you complete the code segment? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.


Which SCD type should you use to support the planned data modeling changes? To answer, drag the appropriate types to the correct issues. Each type may be used once, more than once, or not at all. You may need to drag the split bar between panes or scroll to view content.
NOTE: Each correct selection is worth one point.


You need to develop the task logic for a new job in Lakeflow Jobs that processes telemetry data.
Each task must contain only the appropriate logic for its step in the pipeline. The solution must support the planned changes and meet the data ingestion and processing requirements.
What should you do?
You need to configure compute for the ingestion of telemetry data. The solution must meet the data ingestion and processing requirements.
What should you do?
Which ingestion option should you recommend for each data source? To answer, drag the appropriate options to the correct data sources. Each option may be used once, more than once, or not at all. You may need to drag the split bar between panes or scroll to view content.
NOTE: Each correct selection is worth one point.


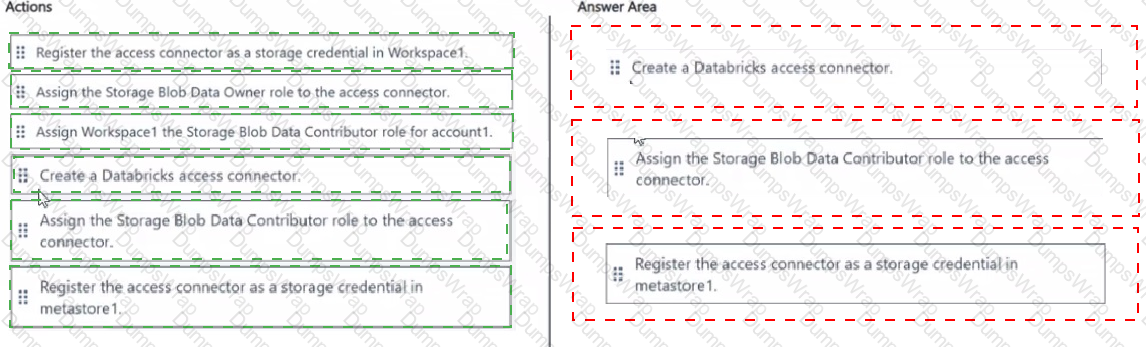
You have an Azure Databricks workspace named Workspace1 that is attached to a Unity Catalog metastore named metastore1
You need to register an Azure Storage account named account1 that has a hierarchical namespace enabled as an external location The external location must use a managed identity to authenticate to account1 and the solution must follow the principle of least privilege.
Which three actions should you perform in sequence' To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order.

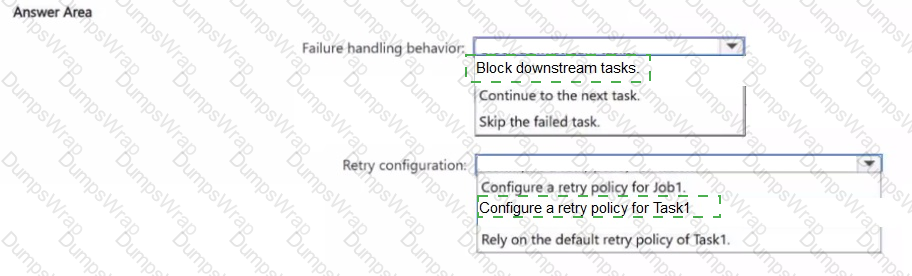
You have an Azure Databricks job named Job1 that contains an ingestion task named Task1 and transformation task named Task2. You need to ensure that if Task1 fails, the task retries automatically, and Task2 is prevented from running How should you configure Job1? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.

You have an Azure Databricks workspace named Workspace1 that contains a lakehouse and is enabled for Unity Catalog.
You have a connection to a Microsoft SQL Server database named DB1.
You need to expose the schemas and tables of DB1 to meet the following requirements:
• The schemas and tables can be queried in Databricks.
• The schemas and tables appear alongside other Unity Catalog objects.
• The data is NOT copied into Databricks-managed storage.
Solution: You create a Lakeflow Connect pipeline and connect it to DB1. Does this meet the goal?
You have an Azure Databricks workspace.
You need to ingest streaming data from Azure Event Hubs by using Apache Spark Structured Streaming The solution must authenticate to Event Hubs and read the event payload.
How should you complete the PySpark code segment? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.


