SAP Certified Development Associate - SAP HANA 2.0 SPS06 Questions and Answers
What are the key characteristics of the calculation view's Input Parameter? There are 3 correct answers to this question.
Options:
It is passed using a WHERE clause.
It can NOT be used to filter measure values.
It can be used in a conditional expression.
It is passed via reserved word PLACEHOLDER.
It can be used to pass values to table functions.
Answer:
C, D, EExplanation:
A calculation view is a view that combines data from multiple sources, such as tables, views, or functions, using graphical or SQLScript logic. A calculation view can define input parameters, which are variables that allow the user to influence the query execution with values that are entered at runtime. Input parameters can be used for various purposes, such as filtering, currency conversion, or dynamic calculations.
Some of the key characteristics of the calculation view’s input parameter are:
- It can be used in a conditional expression. A conditional expression is an expression that evaluates to a value based on a condition. For example, an input parameter can be used to determine which column to use for aggregation, or which table function to call, based on the user’s input. A conditional expression can be written using the CASE or IF syntax in SQLScript, or using the graphical expression editor in the calculation view.
- It is passed via reserved word PLACEHOLDER. The reserved word PLACEHOLDER is used to pass the input parameter value to the calculation view when calling it from SQL. The syntax is PLACEHOLDER.“
inputparametername
” => ‘value’. For example, if the calculation view has an input parameter named CURRENCY, then the SQL statement to call the view with the value ‘USD’ would be SELECT * FROM “CALC_VIEW” (PLACEHOLDER.“
CURRENCY
” => ‘USD’).
- It can be used to pass values to table functions. A table function is a function that returns a table as its output. A table function can be used as a data source in a calculation view, and it can accept input parameters as arguments. For example, a table function can perform currency conversion based on the input parameter value, and return the converted data to the calculation view.
The other options are incorrect because they are not characteristics of the calculation view’s input parameter. It is not passed using a WHERE clause, as the WHERE clause is used to filter data based on a condition, not to pass values to a view. It can be used to filter measure values, as measure values are numeric values that can be aggregated, such as sales amount or quantity. An input parameter can be used to filter measure values based on a range, a comparison, or a calculation. References:
- SAP HANA Platform 2.0 SPS06: SAP HANA SQL and System Views Reference, Section 2.1.5.3
- SAP HANA Platform 2.0 SPS06: SAP HANA SQLScript Reference, Section 2.1.2.1
- SAP HANA Platform 2.0 SPS06: SAP HANA SQLScript Reference, Section 2.1.2.2
- SAP HANA Platform 2.0 SPS06: SAP HANA SQLScript Reference, Section 2.1.2.3
- SAP HANA Platform 2.0 SPS06: SAP HANA SQLScript Reference, Section 2.1.2.4
- SAP HANA Platform 2.0 SPS06: SAP HANA SQLScript Reference, Section 2.1.2.5
- SAP HANA Platform 2.0 SPS06: SAP HANA SQLScript Reference, Section 2.1.2.6
- SAP HANA Platform 2.0 SPS06: SAP HANA SQLScript Reference, Section 2.1.2.7
- SAP HANA Platform 2.0 SPS06: SAP HANA SQLScript Reference, Section 2.1.2.8
- SAP HANA Platform 2.0 SPS06: SAP HANA SQLScript Reference, Section 2.1.2.9
- SAP HANA Platform 2.0 SPS06: SAP HANA SQLScript Reference, Section 2.1.2.10
- SAP HANA Platform 2.0 SPS06: SAP HANA SQLScript Reference, Section 2.1.2.11
- SAP HANA Platform 2.0 SPS06: SAP HANA SQLScript Reference, Section 2.1.2.12
- SAP HANA Platform 2.0 SPS06: SAP HANA SQLScript Reference, Section 2.1.2.13
- SAP HANA Platform 2.0 SPS06: SAP HANA SQLScript Reference, Section 2.1.2.14
- SAP HANA Platform 2.0 SPS06: SAP HANA SQLScript Reference, Section 2.1.2.15
- SAP HANA Platform 2.0 SPS06: SAP HANA SQLScript Reference, Section 2.1.2.16
- SAP HANA Platform 2.0 SPS06: SAP HANA SQLScript Reference, Section 2.1.2.17
- SAP HANA Platform 2.0 SPS06: SAP HANA SQLScript Reference, Section 2.1.2.18
- SAP HANA Platform 2.0 SPS06: SAP HANA SQLScript Reference, Section 2.1.2.19
- SAP HANA Platform 2.0 SPS06: SAP HANA SQLScript Reference, Section 2.1.2.20
- SAP HANA Platform 2.0 SPS06: SAP HANA SQLScript Reference, Section 2.1.2.21
- SAP HANA Platform 2.0 SPS06: SAP HANA SQLScript Reference, Section 2.1.2.22
- SAP HANA Platform 2.0 SPS06: SAP HANA SQLScript Reference, Section 2.1.2.23
- SAP HANA Platform 2.0 SPS06: SAP HANA SQLScript Reference, Section 2.1.2.24
- SAP HANA Platform 2.0 SPS06: SAP HANA SQLScript Reference, Section 2.1.2.25
- SAP HANA Platform 2.0 SPS06: SAP HANA SQLScript Reference, Section 2.1.2.26
- SAP HANA Platform 2.0 SPS06: SAP HANA SQLScript Reference, Section 2.1.2.27
- SAP HANA Platform 2.0 SPS06: SAP HANA SQLScript Reference, Section 2.1.2.28
- SAP HANA Platform 2.0 SPS06: SAP HANA SQLScript Reference, Section 2.1.2.29
- SAP HANA Platform 2.0 SPS06: SAP HANA SQLScript Reference, Section 2.1.2.30
- SAP HANA Platform 2.0 SPS06: SAP HANA SQLScript Reference, Section 2.1.2.31
- SAP HANA Platform 2.0 SPS06: SAP HANA SQLScript Reference, Section 2.1.2.32
- SAP HANA Platform 2.0 SPS06: SAP HANA SQLScript Reference, Section 2.1.
In an SQL Script procedure, which feature do you use to initialize IN/OUT table parameters? Please choose the correct answer.
Options:
IS_EMPTY
DEFAULT EMPTY
DEFAULT
SET
Answer:
BExplanation:
According to the SAP HANA Developer Guide, you can use the DEFAULT EMPTY clause to initialize IN/OUT table parameters in an SQL Script procedure. This clause specifies that the table parameter is initially empty when the procedure is called, and that the caller can pass an empty table or no table at all. This is useful when you want to use the table parameter as a temporary table inside the procedure, and return the result to the caller. For example, PROCEDURE proc1 (IN/OUT tab1 TABLE(col1 INT, col2 VARCHAR(10)) DEFAULT EMPTY) ... The other options are incorrect, because:
- IS_EMPTY is a function that returns a boolean value indicating whether a table is empty or not. It is not a clause that can be used to initialize table parameters.
- DEFAULT is a clause that can be used to assign a default value to scalar parameters, not table parameters.
- SET is a statement that can be used to assign values to variables or parameters, not a clause that can be used to initialize table parameters.
References: SAP HANA Developer Guide, Chapter 6, Section 6.4.2, page 2111.
You created an HDI database role, using the SAP Web IDE for SAP HANA and deployed your project. Afterward, you made some modifications to the runtime role.
What happens when you change and re-build the design-time role? Please choose the correct answer.
Options:
The runtime modifications are overwritten.
The deployment of the role fails.
The runtime modifications are kept.
You need to confirm the runtime modifications
Answer:
AExplanation:
When you create an HDI database role using the SAP Web IDE for SAP HANA, you define the role in a design-time file with the extension .hdbrole. This file is part of your project and can be deployed to the HDI container as a runtime role. However, if you make any changes to the runtime role directly in the database, such as granting or revoking privileges, those changes are not reflected in the design-time file. Therefore, if you change and re-build the design-time role, the runtime role will be overwritten with the new version of the design-time role, and any runtime modifications will be lost. This is because the deployment process always drops and recreates the runtime role based on the design-time role. The other options are incorrect because the deployment of the role will not fail, the runtime modifications will not be kept, and you do not need to confirm the runtime modifications. References:
- SAP HANA DI Administrator Roles - SAP Help Portal
- SAP HANA Deployment Infrastructure Reference - SAP Help Portal
- Modifying the default access_role in HDI containers - SAP Blogs
To perform a specific task of an XS advanced application, what does a user need? Please choose the correct answer.
Options:
To have directly assigned a Role Collection
To have directly assigned a Scope
To be assigned to an Organization
To be assigned to a Space
Answer:
AExplanation:
According to the SAP HANA Developer Guide, to perform a specific task of an XS advanced application, a user needs to have directly assigned a role collection. A role collection is a set of roles that grant the user the necessary privileges and authorizations to access and use the application. A role collection can be assigned to a user either directly by an administrator, or indirectly by a workflow or a self-service. The other options are incorrect, because:
- To have directly assigned a scope is not a way to perform a specific task of an XS advanced application, but a way to limit the access of a user to a subset of resources within an application. A scope is a qualifier that can be added to a role to restrict the user’s access to a specific resource, such as a space, an organization, or a service instance. A scope does not grant any privileges or authorizations by itself, but only modifies the existing ones.
- To be assigned to an organization is not a way to perform a specific task of an XS advanced application, but a way to group users and resources in a logical unit. An organization is a container that holds spaces, users, applications, and services. An organization can have one or more spaces, which are isolated environments for developing, deploying, and running applications. A user can belong to one or more organizations, but can only perform tasks in the spaces that they are assigned to.
- To be assigned to a space is not a way to perform a specific task of an XS advanced application, but a way to access a specific environment for developing, deploying, and running applications. A space is a sub-container within an organization that holds applications and services. A space can have one or more users, who can have different roles and permissions depending on their tasks. A user can belong to one or more spaces within an organization, but can only perform tasks in the spaces that they are assigned to.
References: SAP HANA Developer Guide, Chapter 6, Section 6.4.2, page 2111.
To which SAP HANA authorization entities can you grant a role? There are 2 correct answers to this question.
Options:
Object
Role
Privilege
User
Answer:
B, DExplanation:
You can grant a role to another role or to a user in SAP HANA. A role is a collection of privileges that can be assigned to users or other roles to authorize them to perform certain tasks or access certain objects in the database. A user is an individual account that can log on to the database and execute SQL statements. By granting a role to another role, you can create a hierarchy of roles that inherit the privileges of their parent roles. By granting a role to a user, you can assign the user the privileges of that role. You can use the GRANT statement or the SAP HANA cockpit to grant roles to roles or users. The other options are incorrect because you cannot grant a role to an object or a privilege. An object is a database entity, such as a table, view, procedure, etc., that can be accessed or manipulated by users or roles with the appropriate privileges. A privilege is a permission to perform a specific action or access a specific object in the database. You can grant privileges to users or roles, but not to roles or objects. References:
- Roles and Privileges - SAP Help Portal
- Users and Roles - SAP Help Portal
- GRANT Statement (Roles) - SAP Help Portal
- [Granting Roles to Users and Roles] - SAP Help Portal
You need to create a native SAP HANA application that fully leverages the SAP HANA platform. How do you implement data-intensive
calculations?
Please choose the correct answer.
Options:
Push the calculations onto the application layer.
Push the calculations onto the database layer
Push the calculations onto the presentation layer.
Distribute calculations between application layer and presentation layer.
Answer:
BExplanation:
To create a native SAP HANA application that fully leverages the SAP HANA platform, you should implement data-intensive calculations on the database layer, using SQLScript or calculation views. SQLScript is a scripting language that allows you to write stored procedures, functions, and triggers that perform complex calculations and data transformations on the SAP HANA database. Calculation views are graphical or scripted views that define data models based on tables, views, or other calculation views, and apply filters, joins, aggregations, and other operations on the data. By pushing the calculations onto the database layer, you can take advantage of the in-memory processing, parallelization, and optimization capabilities of SAP HANA, and reduce the data transfer and network latency between the application layer and the database layer123.
The other options are not correct because they do not fully leverage the SAP HANA platform, and they may result in poor performance, high resource consumption, and increased complexity. Pushing the calculations onto the application layer means that you use a programming language, such as Java or Node.js, to perform the calculations on the application server, which may not be as efficient or scalable as the database server. Pushing the calculations onto the presentation layer means that you use a UI framework, such as SAPUI5 or SAP Fiori, to perform the calculations on the client device, such as a browser or a mobile device, which may not have enough processing power or memory to handle large or complex data sets. Distributing the calculations between the application layer and the presentation layer means that you split the calculations into different parts and execute them on different layers, which may introduce inconsistency, redundancy, and dependency issues. References:
- SAP HANA Platform, SAP HANA SQL and System Views Reference, SQLScript Guide
- SAP HANA Platform, SAP HANA Modeling Guide for SAP HANA Web Workbench, Calculation Views
- SAP HANA Platform, Developing Applications with SAP HANA Cloud Platform, Developing Multi-Target Applications, Developing Database Modules
What statement must you insert to the following OData service to complete the navigation definition from the customer entity set to the corresponding sales orders? Please choose the correct answer.
service{ "sample.odata::customer" as customer" navigates ("Customer_Orders* as "toOrders); "sample.odata::salesorder" as "Orders";)
Options:
Aggregation
Association
Key specification
Join condition
Answer:
BExplanation:
To complete the navigation definition from the customer entity set to the corresponding sales orders, you need to insert an association statement between the two entity sets. An association defines a relationship between two entity sets based on a referential constraint, which specifies the foreign key and the principal key properties that link the entity sets. An association also defines the cardinality and the role names of the entity sets involved in the relationship1. In this case, the association statement should look something like this:
association Customer_Orders with referential constraint principal customer key CustomerID dependent Orders key CustomerID multiplicity “1” to “*”;
This statement defines an association named Customer_Orders that relates the customer entity set with the Orders entity set based on the CustomerID property. The principal role is assigned to the customer entity set, which means that each customer entity can have zero or more related Orders entities. The dependent role is assigned to the Orders entity set, which means that each Orders entity must have exactly one related customer entity2.
The other options are not correct because:
- Aggregation: This is a feature of calculation views that allows you to define measures and attributes for analytical queries. It is not related to OData service definitions3.
- Key specification: This is a clause that you use to define the key properties of an entity type in an OData service definition. It is not used to define navigation between entity sets1.
- Join condition: This is a clause that you use to specify how to join two tables or views in a SQL statement. It is not used to define navigation between entity sets4.
References: 1: OData Service Definition Language Syntax (XS Advanced) 2: OData Service-Definition Examples 3: Creating Calculation Views 4: SQL Reference Manual
In which of the following objects can you use Commit and Rollback statements? Please choose the correct answer.
Options:
Scalar user-defined function
SQL Script procedure
Table user-defined function
Scripted calculation view
Answer:
BExplanation:
You can use Commit and Rollback statements in SQL Script procedures to control the transactional behavior of your code. Commit and Rollback statements allow you to commit or undo the changes made by the SQL statements within the procedure. You can also use them in exception handlers to handle errors and ensure data consistency. You cannot use Commit and Rollback statements in scalar user-defined functions, table user-defined functions, or scripted calculation views, as they are not allowed to have any side effects on the database. References: COMMIT and ROLLBACK, SQLScript Procedures, [SQLScript Functions].
Which of the following are characteristics of database procedures?
Options:
Database procedures can have both input and output parameters; however, a parameter CANNOT be both input and output.
Database procedures can have several output parameters, and a mix of both scalar and table types is possible.
If, in the database procedure header, you use the READS SQL DATA option, then INSERT statements are prohibited; however, dynamic SQL is allowed.
If, in the database procedure header, you use the SQL SECURITY INVOKER option, then only the owner of the procedure can start it.
Answer:
A, BExplanation:
According to the SAP HANA SQLScript Reference1, database procedures are subroutines that can be called from SQL statements or other database procedures. Database procedures can have the following characteristics:
- Database procedures can have both input and output parameters; however, a parameter CANNOT be both input and output. Input parameters are used to pass values to the procedure, while output parameters are used to return values from the procedure. A parameter can be either scalar or table type, depending on the data type and cardinality. A parameter cannot be both input and output, because this would create ambiguity and inconsistency in the parameter passing mechanism. For example, you cannot declare a parameter as IN OUT, or assign a value to an input parameter, or read a value from an output parameter. For more information on database procedure parameters, see [Parameters of Database Procedures]2.
- Database procedures can have several output parameters, and a mix of both scalar and table types is possible. Output parameters are used to return values from the procedure to the caller. A procedure can have zero or more output parameters, depending on the purpose and logic of the procedure. Output parameters can be either scalar or table type, depending on the data type and cardinality. A procedure can have a mix of both scalar and table output parameters, as long as they are compatible with the caller’s expectations and syntax. For example, you can use a SELECT statement with INTO clause to assign values to scalar output parameters, or use a SELECT statement with RESULT clause to return a table output parameter. For more information on database procedure output parameters, see [Output Parameters of Database Procedures]3.
- If, in the database procedure header, you use the READS SQL DATA option, then INSERT statements are prohibited; however, dynamic SQL is allowed. The READS SQL DATA option is used to indicate that the procedure only reads data from the database, and does not modify or write any data. This option is useful for performance optimization and security enforcement, as it allows the database to apply certain optimizations and checks to the procedure. However, this option also imposes some restrictions on the procedure, such as prohibiting any INSERT, UPDATE, DELETE, or MERGE statements, or any other statements that modify the database state. Dynamic SQL, which is SQL code that is constructed and executed at run time, is still allowed, as long as it does not violate the READS SQL DATA option. For more information on the READS SQL DATA option, see [Procedure Header Options]4.
- If, in the database procedure header, you use the SQL SECURITY INVOKER option, then only the owner of the procedure can start it. The SQL SECURITY INVOKER option is used to indicate that the procedure is executed with the privileges of the user who invokes the procedure, rather than the privileges of the user who created the procedure. This option is useful for security enforcement and access control, as it allows the database to apply the appropriate authorization checks and restrictions to the procedure. However, this option does not affect who can start the procedure, as this is determined by the GRANT EXECUTE statement, which grants the execute privilege on the procedure to a specific user or role. The SQL SECURITY INVOKER option only affects how the procedure is executed, not who can execute it. For more information on the SQL SECURITY INVOKER option, see [Procedure Header Options]4.
References: 1: SAP HANA SQLScript Reference 2: Parameters of Database Procedures 3: Output Parameters of Database Procedures 4: Procedure Header Options
Which OData capacities are supported in SAP HANA extended application services, advanced model (XSA)? There are 3 correct answers to this question.
Options:
Union
Aggregation
Join
Projection
Association
Answer:
B, C, EExplanation:
OData is a protocol for exposing and consuming data over the web using RESTful APIs. OData supports various capacities, such as query options, operations, and annotations, to enable flexible and powerful data access and manipulation. SAP HANA extended application services, advanced model (XSA) is a framework for developing and deploying cloud-native applications on SAP HANA. XSA supports OData v4 as one of the service types that can be defined and exposed by the SAP Cloud Application Programming Model (CAP). XSA supports the following OData capacities in CAP:
- Aggregation: This capacity allows you to perform aggregation functions, such as sum, count, min, max, and average, on the data returned by an OData service. You can use the $apply query option to specify the aggregation expressions and groupings. XSA supports the OData Aggregation Extension for applying aggregations on entity sets and collections.
- Join: This capacity allows you to perform join operations on the data returned by an OData service. You can use the $expand query option to include related entities or properties in the response. XSA supports the OData Association and Navigation concepts for defining and accessing the relationships between entities.
- Association: This capacity allows you to define and use associations between entities in an OData service. Associations are semantic links that describe the cardinality and referential constraints of the relationships. You can use the OData Association and Referential Constraint annotations to specify the association details in the service definition or the metadata document.
The other options are not correct because:
- A. Union: This capacity is not supported by OData or XSA. Union is a set operation that combines the results of two or more queries into a single result set. OData does not provide a query option or an extension for performing union operations on the data returned by an OData service.
- D. Projection: This capacity is supported by OData, but not by XSA. Projection is a query option that allows you to select a subset of properties or entities from an OData service. You can use the $select query option to specify the properties or entities you want to include in the response. However, XSA does not support the $select query option in CAP, as it relies on the projection capabilities of the underlying data source, such as SAP HANA or PostgreSQL.
References:
- SAP Cloud Application Programming Model, OData v4 Support
- SAP Cloud Application Programming Model, Annotations
- OData Version 4.0 Part 1: Protocol
- OData Version 4.0 Part 2: URL Conventions
- OData Aggregation Extension for Data Services Version 4.0
Which of the following can be used when implementing transaction management logic in SQLScript using savepoints? Note: There are 3 correct answers to this question.
Options:
Release savepoint
Rollback to savepoint
Savepoint
Reverse savepoint
Alter system savepoint
Answer:
A, B, CExplanation:
According to the SAP HANA SQLScript Reference, the following statements can be used when implementing transaction management logic in SQLScript using savepoints:
- Savepoint: Creates a savepoint with a specified name within the current transaction. A savepoint marks a point in the transaction that can be rolled back to without affecting the rest of the transaction. For example, SAVEPOINT sp1;
- Rollback to savepoint: Rolls back the current transaction to the specified savepoint. All changes made after the savepoint are undone, but the transaction remains active. For example, ROLLBACK TO SAVEPOINT sp1;
- Release savepoint: Releases the specified savepoint and all subsequent savepoints. The released savepoints are no longer valid and cannot be rolled back to. For example, RELEASE SAVEPOINT sp1;
The other options are incorrect, because:
- Reverse savepoint is not a valid statement in SQLScript. There is no such statement in the SAP HANA SQLScript Reference.
- Alter system savepoint is not a statement that can be used in SQLScript, but a statement that can be used in SQL. It triggers a savepoint operation for the entire database system, not for a specific transaction. It is used for administrative purposes, such as backup and recovery, not for transaction management logic.
References: SAP HANA SQLScript Reference, Chapter 6, Section 6.4.2, page 2111.
What do you use to set up unit testing for your SQL Script procedure? Please choose the correct answer.
Options:
SQL Script logging procedures
A library with language SQLSCRIPT TEST
The SQL Script debugger
The SQL Script Code Analyzer
Answer:
BExplanation:
To set up unit testing for your SQL Script procedure, you use a library with language SQLSCRIPT TEST. A library with language SQLSCRIPT TEST is a special type of library that contains SQL Script test cases for testing the behavior and performance of SQL Script procedures. A SQL Script test case is a SQL Script procedure that has the prefix TEST_ and that uses the ASSERT and EXPECT statements to verify the expected results and outputs of the procedure under test. A library with language SQLSCRIPT TEST can be created in the SAP Web IDE for SAP HANA or in the SAP HANA Studio, and can be executed by using the SQL Script Test Framework, which is a tool that runs the test cases and generates a test report.
The following options are not used to set up unit testing for your SQL Script procedure, but for other purposes:
- SQL Script logging procedures: SQL Script logging procedures are procedures that use the APPLY_FILTER and APPLY_AGGREGATION statements to perform logging operations on table variables or cursors. SQL Script logging procedures can be used to monitor and analyze the execution of SQL Script procedures, but not to test their correctness or functionality.
- The SQL Script debugger: The SQL Script debugger is a tool that allows you to debug SQL Script procedures by setting breakpoints, inspecting variables, and stepping through the code. The SQL Script debugger can be used to identify and fix errors or bugs in SQL Script procedures, but not to verify their expected results or outputs.
- The SQL Script Code Analyzer: The SQL Script Code Analyzer is a tool that analyzes SQL Script code and provides suggestions and recommendations for improving its quality, performance, and maintainability. The SQL Script Code Analyzer can be used to optimize and refactor SQL Script code, but not to test its behavior or functionality.
References:
- [SAP HANA Platform Documentation], SAP HANA SQLScript Reference, Chapter 6: SQLScript Test Framework, pp. 153-158.
- [SAP HANA Platform Documentation], SAP HANA Developer Guide for SAP HANA XS Advanced Model, Chapter 7: Developing SQLScript Procedures, Section 7.4: Testing SQLScript Procedures, pp. 137-140.
What are the characteristics of the calculation view of type "SQL Access Only"? There are 2 correct answers to this question.
Options:
Can be directly exposed to all client tools
Can be directly used for multidimensional analysis
Can be direct y accessed via SQL
Can be directly used as modelled data source for another view
Answer:
C, DExplanation:
A calculation view of type “SQL Access Only” is a calculation view that is not visible to the reporting tools and does not support multidimensional reporting. However, it can be directly accessed via SQL and used as a modelled data source for another view. This type of calculation view is useful for scenarios where you want to perform complex calculations or transformations on the data, but do not need to expose the result to the end users or analytical applications. You can use the SQL Access Only calculation view as an intermediate step in your data modelling process, and then use another calculation view with data category Cube or Dimension to provide the final output for reporting or analysis. The other options are incorrect because a calculation view of type “SQL Access Only” cannot be directly exposed to all client tools or used for multidimensional analysis. These features are only available for calculation views with data category Cube or Dimension. References:
- Supported Data Categories for Calculation Views - SAP Help Portal
- Quick Reference: Calculation View Properties - SAP Help Portal
- SAP HANA Modeling Guide for SAP HANA Studio - SAP Help Portal
- New Hierarchy SQL enablement with Calculation Views in SAP HANA 1.0 SPS 10 - SAP Blogs
- HA300 - SAP HANA 2.0 SPS06 Modeling - SAP Training
You need to consume a Node.js service in an SAPUI5 application. In which section of the mta.xml file do you define the variable for the
exposed service?
Please choose the correct answer.
Options:
In the path section of the Node.js module
In the provides section of the Node.js module
In the properties sect on of the MTA resources
In the requires sect on of the HTML5 module
Answer:
DExplanation:
To consume a Node.js service in an SAPUI5 application, you need to define the variable for the exposed service in the requires section of the HTML5 module in the mta.xml file. This way, you can specify the dependency of the SAPUI5 application on the Node.js service and bind them together. The requires section allows you to reference a resource or a module that provides a service or a capability that your module needs. You can also define additional properties and parameters for the required element, such as the name of the variable that holds the service URL. References: The MTA Development Descriptor, The MTA Deployment Descriptor, Developing Multi-Target Applications
Which services can you use in SAP HANA, express edition? There are 3 correct answers to this question.
Options:
Dynamic tiering
Text analytics
Multi-core and parallelization
System replication
Columnar OLTP and OLAP
Answer:
B, C, EExplanation:
SAP HANA, express edition is a streamlined version of SAP HANA that can run on laptops and other resource-constrained hosts, such as a cloud-hosted virtual machine. SAP HANA, express edition is free to use for in-memory databases up to 32 GB of RAM. SAP HANA, express edition supports the following services:
- Text analytics: This service allows you to analyze unstructured text data, such as documents, emails, tweets, and blogs, using natural language processing techniques. You can use text analytics to extract entities, facts, sentiments, and keywords from text data, and to perform linguistic analysis, such as tokenization, lemmatization, and part-of-speech tagging.
- Multi-core and parallelization: This service allows you to leverage the multi-core architecture and parallel processing capabilities of SAP HANA to optimize the performance of data-intensive operations, such as queries, calculations, and transformations. You can use multi-core and parallelization to distribute the workload across multiple CPU cores and threads, and to execute tasks in parallel or in batches.
- Columnar OLTP and OLAP: This service allows you to store and process data in a columnar format, which enables faster data compression, aggregation, and analysis. You can use columnar OLTP and OLAP to support both transactional and analytical workloads on the same data set, without requiring data duplication or pre-aggregation.
The other options are not correct because:
- A. Dynamic tiering: This service allows you to extend the SAP HANA in-memory database with disk-based tables that can store large volumes of warm or cold data. You can use dynamic tiering to reduce the memory footprint and cost of SAP HANA, while still maintaining query access to the disk-based data. However, dynamic tiering is not supported by SAP HANA, express edition, as it requires additional hardware and software components.
- D. System replication: This service allows you to create and maintain one or more secondary SAP HANA systems that are identical copies of a primary SAP HANA system. You can use system replication to ensure high availability and disaster recovery of SAP HANA, as the secondary systems can take over the role of the primary system in case of a failure. However, system replication is not supported by SAP HANA, express edition, as it requires additional licenses and configuration.
References:
- SAP HANA, express edition, Overview
- SAP HANA, express edition, Features
- SAP HANA, express edition, FAQ
Which keywords do you use to define an OData association? There are 3 correct answers to this question.
Options:
JOIN
DEPENDENT
UNION
MULTIPLICITY
PRINCIPAL
Answer:
B, D, EExplanation:
OData associations are used to define the relationships between two or more entity types in an OData service. Associations can be simple or complex, depending on whether the relationship information is stored in one of the participating entities or in a separate association table. Associations are composed of two ends, each of which has a role name, a multiplicity, and a set of properties that form the referential constraint. The keywords that are used to define an OData association are:
- DEPENDENT: This keyword is used to specify the role name of the dependent end of the association, which is the entity type that contains the foreign key properties that refer to the principal entity type. For example, in the association Customer_Orders, the entity type Orders is the dependent end, as it contains the property CustomerID that refers to the entity type Customers.
- MULTIPLICITY: This keyword is used to specify the cardinality of each end of the association, which indicates how many instances of one entity type can be related to one instance of another entity type. The possible values for multiplicity are: 0…1 (zero or one), 1 (exactly one), or * (many). For example, in the association Customer_Orders, the multiplicity of the principal end Customers is 1, meaning that each customer can have only one instance, and the multiplicity of the dependent end Orders is *, meaning that each customer can have many orders.
- PRINCIPAL: This keyword is used to specify the role name of the principal end of the association, which is the entity type that is referenced by the foreign key properties of the dependent entity type. For example, in the association Customer_Orders, the entity type Customers is the principal end, as it is referenced by the property CustomerID of the entity type Orders.
The following keywords are not used to define an OData association, but for other purposes:
- JOIN: This keyword is used to specify the join condition between two entity sets in a query expression, which is used to retrieve data from multiple sources. For example, the query expression Customers?$expand=Orders($filter=Status eq ‘Open’) uses a join condition to filter the orders that have the status ‘Open’ for each customer.
- UNION: This keyword is used to specify the union operation between two query expressions, which is used to combine the results of both queries into one result set. For example, the query expression Customers?$filter=Country eq ‘US’ union Customers?$filter=Country eq ‘CA’ uses a union operation to get the customers that are from either the US or Canada.
You are working on an entity using Core Data Services. Which properties can you define inside the Technical Configuration section? There are 2 correct answers to this question.
Options:
Index
Import
Storage Type
Association
Answer:
A, CExplanation:
The Technical Configuration section of a Core Data Services (CDS) entity allows you to define properties that affect the physical storage and performance of the entity in the database. You can define the following properties inside the Technical Configuration section1:
- Index: You can create one or more indexes on the entity to improve the query performance. You can specify the index name, the columns to be indexed, and the index type (such as unique, full-text, or spatial)2.
- Storage Type: You can specify the storage type of the entity, such as column store or row store, to optimize the data access and compression. You can also specify the partitioning mode and criteria for the entity, such as hash, range, or round-robin3.
The other two options, Import and Association, are not properties that can be defined inside the Technical Configuration section. Import is a keyword that allows you to import another CDS entity or a database table into the current CDS entity, and use its columns as part of the projection list4. Association is a keyword that allows you to create a relationship between two CDS entities, and use the associated entity’s columns as part of the projection list or the join condition. References: 1: Technical Configuration | SAP Help Portal 2: Index Definition | SAP Help Portal 3: Storage Type | SAP Help Portal 4: Import | SAP Help Portal : [Association | SAP Help Portal]
A Node.js module is executed for the first time in SAP HANA extended application services, advanced model (XS advanced). Which of the following activities are performed automatically? There are 2 correct answers to this question.
Options:
The source code is compiled to create an executable binary file.
A new SAP HANA Deployment Infrastructure (HDI) container is created.
The required modules are downloaded based on module dependencies.
A new service is executed on the application server.
Answer:
B, CExplanation:
When a Node.js module is executed for the first time in SAP HANA extended application services, advanced model (XS advanced), the following activities are performed automatically12:
- A new SAP HANA Deployment Infrastructure (HDI) container is created: An HDI container is a logical database schema that contains the database objects and data that are required by the Node.js module. An HDI container is created based on the configuration and definition files of the Node.js module, such as the package.json, the mta.yaml, and the hdi-config.json. The HDI container is bound to the Node.js module as a service, and it can be accessed using the HDI client library or the SQL client library.
- The required modules are downloaded based on module dependencies: The Node.js module may depend on other modules or libraries that provide additional functionality or services, such as express, hdb, or passport. These dependencies are specified in the package.json file of the Node.js module, and they are downloaded and installed automatically from the npm registry or the SAP npm registry when the Node.js module is executed for the first time.
The other options are not correct because they are not activities that are performed automatically when a Node.js module is executed for the first time in XS advanced. The source code is not compiled to create an executable binary file, but rather interpreted and executed by the Node.js runtime environment. A new service is not executed on the application server, but rather the existing Node.js module is executed as a service on the application server. References:
- SAP HANA Platform, Developing Applications with SAP HANA Cloud Platform, Developing Multi-Target Applications, Developing Node.js Modules
- SAP HANA Platform, SAP HANA Extended Application Services, Advanced Model, Developing and Deploying Applications, Developing Node.js Applications
What is the package descriptor package.json used for? There are 2 correct answers to this question.
Options:
To define back-end destinations
To set the router version
To list the package dependencies
To define the routes
Answer:
C, DExplanation:
The package descriptor package.json is a JSON file that defines the build, deployment, and runtime dependencies of a JavaScript application in SAP HANA XS Advanced. The package.json file is mandatory for JavaScript applications and it is located in the general section of the project. As well as the application name and version, dependencies to other Node.js modules, the Node.js version, run scripts, and the main program are configured. The package descriptor package.json is used for the following purposes:
- To list the package dependencies: The package.json file contains a dependencies property that lists the names and versions of the Node.js modules that the application depends on. These modules are installed by the npm install command during the build process and are available in the node_modules folder of the application. The dependencies property can also specify the scope and type of the dependencies, such as devDependencies for development-only modules, or peerDependencies for modules that are required by other modules.
- To define the routes: The package.json file contains a sap.cloud.service property that defines the name of the service that the application provides or consumes. This name is used to generate the routes for the application in the XS advanced environment. The routes are defined in the xs-app.json file, which is located in the same folder as the package.json file. The routes specify the rules for forwarding requests to the back-end microservices or destinations.
The following purposes are not achieved by the package descriptor package.json, but by other files or tools:
- To define back-end destinations: The back-end destinations are defined in the mta.yaml file, which is the deployment descriptor file that specifies the metadata and dependencies for the multi-target application (MTA) project. The mta.yaml file is located in the root folder of the MTA project and is used by the Cloud Foundry environment to deploy the application. The back-end destinations are declared as resources of type org.cloudfoundry.existing-service or org.cloudfoundry.managed-service, and are bound to the application modules by the requires property.
- To set the router version: The router version is set by the @sap/approuter module, which is a Node.js module that provides the application router service for the XS advanced environment. The application router service is responsible for routing requests to the appropriate destinations and for authenticating users. The @sap/approuter module is installed by the npm install command during the build process and is available in the node_modules folder of the application. The version of the @sap/approuter module is specified in the dependencies property of the package.json file.
References:
- [SAP HANA Deployment Infrastructure Reference], Chapter 5: HDI with XS Advanced, Section 5.1: Developing with the SAP Web IDE for SAP HANA, Subsection 5.1.2: Configure Application Routing (xs-app.json), pp. 101-104.
- [SAP HANA Platform Documentation], SAP HANA Developer Guide for SAP HANA XS Advanced Model, Chapter 4: Developing HTML5 Applications, Section 4.1: Developing HTML5 Applications Using SAP Web IDE for SAP HANA, Subsection 4.1.3: Configure Application Routing (xs-app.json), pp. 77-80.
Which OData service do you use to prevent changes to existing line items of the sap.test :myTable table? Please choose the correct answer.
A)
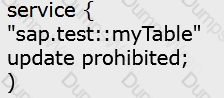
B)
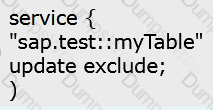
C)

D)

Options:
Option A
Option B
Option C
Option D
Answer:
AExplanation:
To prevent changes to existing line items of the sap.test::myTable table, you can use the OData service that specifies the update authorization as no-authorization for the table. This means that the OData service does not allow any update operations on the table, such as PUT, PATCH, or MERGE. The option A shows the code snippet that defines the OData service with this restriction. The other options do not have the update no-authorization clause for the table, and therefore, they do not prevent changes to the existing line items. References: OData Service Authorization, OData Security Considerations.
Which metadata declarations can you specify in a SQL Script procedure when you use the SAP HANA Deployment Infrastructure? There are 2 correct answers to this question.
Options:
Security
Language
Default schema
Authorization
Answer:
B, CExplanation:
You can specify the language and the default schema as metadata declarations in a SQL Script procedure when you use the SAP HANA Deployment Infrastructure (HDI). The language declaration defines the language mode of the procedure, which can be SQLSCRIPT or SQL. The default schema declaration defines the schema that is used to resolve unqualified object names in the procedure body. These declarations are optional and can be specified after the procedure name and before the parameter list. For example:
CREATE PROCEDURE MY_PROCEDURE LANGUAGE SQLSCRIPT DEFAULT SCHEMA MY_SCHEMA ( … )
The other options are incorrect because security and authorization are not valid metadata declarations for SQL Script procedures. Security and authorization are handled by the HDI framework, which automatically grants the necessary privileges to the technical users and roles that access the HDI container objects. You do not need to specify any security or authorization clauses in the SQL Script procedure definition. References:
- Procedure Metadata - SAP Help Portal
- CREATE PROCEDURE Statement (Procedural) - SAP Help Portal
- SAP HANA Deployment Infrastructure - SAP Help Portal
- HA150 - SAP HANA 2.0 SPS06 SQLScript for SAP HANA - SAP Training
How do you debug a Node.js module in SAP Web IDE for SAP HANA? Please choose the correct answer.
Options:
Set the enabled parameter to true in the section debugger of the xsengine.ini file.
Add the sap.hana .xs.debugger::Debugger role to the HDI Container's #RT User.
Start the debugger from the XS command line interface and run the program in SAP Web IDE for SAP HANA.
Attach the debugger to the application in the SAP Web IDE for SAP HANA.
Answer:
DExplanation:
According to the SAP Web IDE for SAP HANA Developer Guide, you can debug a Node.js module in SAP Web IDE for SAP HANA by attaching the debugger to the application in the SAP Web IDE for SAP HANA. To do this, you need to open the debugger panel, attach your application, and choose your multi-target application and select a debug target. Then, you can perform the regular debugging tasks, such as setting breakpoints, stepping through the code, examining the variables, and so on. The other options are incorrect, because:
- Setting the enabled parameter to true in the section debugger of the xsengine.ini file is not a way to debug a Node.js module in SAP Web IDE for SAP HANA, but a way to enable the XS JavaScript debugger for XSJS applications. This is not relevant for Node.js modules, which use a different runtime and debugger.
- Adding the sap.hana.xs.debugger::Debugger role to the HDI Container’s #RT User is not a way to debug a Node.js module in SAP Web IDE for SAP HANA, but a way to grant the XS JavaScript debugger privileges to the runtime user of the HDI container. This is not relevant for Node.js modules, which use a different runtime and debugger.
- Starting the debugger from the XS command line interface and running the program in SAP Web IDE for SAP HANA is not a way to debug a Node.js module in SAP Web IDE for SAP HANA, but a way to debug a Node.js module using command-line tools. This is an alternative option for debugging Node.js modules, but it does not use the SAP Web IDE for SAP HANA.
References: SAP Web IDE for SAP HANA Developer Guide, Chapter 6, Section 6.4.2, page 2111.
You need to install SAP HANA 2.0, express edition to develop a native SAP HANA application. Which of the following deployment options do you have?
There are 2 correct answers to this question.
Options:
Installation on Windows Server
Installation on Mac OS
Installation on Linux OS
Usage of virtual machine on Microsoft Windows
Answer:
C, DExplanation:
SAP HANA 2.0, express edition is a streamlined version of SAP HANA that can run on laptops and other resource-constrained hosts. It supports native SAP HANA application development and can be installed on Linux OS or used as a virtual machine on Microsoft Windows. Installation on Windows Server or Mac OS is not supported by SAP HANA 2.0, express edition. References:
- SAP HANA 2.0 SPS06 - Application Development for SAP HANA1, Section 1.1, p. 5
- SAP HANA, express edition - Installation Guide, Section 1.1, p. 7
- SAP HANA, express edition - FAQ, Question 1
You need to initially load data from a .csv file into a Core Data Services table in SAP HANA extended application services, advanced model (XS advanced). Which file type do you create? Please choose the correct answer.
Options:
A file with extension .hdbtable data
A fie with extension .hdbtable
A file with extension .hdbdd
A file with extension .hdbti
Answer:
DExplanation:
To initially load data from a .csv file into a Core Data Services (CDS) table in SAP HANA extended application services, advanced model (XS advanced), you need to create a file with extension .hdbti, which stands for HDB Table Import. This file defines the configuration and mapping for importing data from a local or remote file into a table in the HDI container. You can specify the source file name, location, format, delimiter, header, encoding, etc., as well as the target table name, schema, and column mapping. You can also specify whether to truncate the target table before importing, or to append the data to the existing table. You can use the SAP Web IDE for SAP HANA to create and deploy the .hdbti file, or use the HDI deployer CLI tool. The other options are incorrect because they are not the correct file types for importing data into a CDS table. A file with extension .hdbtabledata is a file that contains the data for a table in a JSON format, but it is not used for importing data from a .csv file. A file with extension .hdbtable is a file that defines the structure and properties of a table, but it does not contain any data. A file with extension .hdbdd is a file that defines the CDS entities, such as contexts, types, views, associations, etc., but it does not import any data. References:
- Importing Data into Tables - SAP Help Portal
- Creating Table Import Configuration Files - SAP Help Portal
- HDI Deployer CLI Tool - SAP Help Portal
- [HA300 - SAP HANA 2.0 SPS06 Modeling] - SAP Training
You developed a multi-target application that contains only a database module. Which environment are the runtime objects created in? Please choose the correct answer.
Options:
Java Runtime Environment (JRE)
SAP HANA Runtime Tools (HRTT)
SAP Web IDE for SAP HANA
HANA Deployment Infrastructure Container
Answer:
DExplanation:
A multi-target application (MTA) is a single application that consists of multiple modules that are developed using different technologies and designed to run on different target runtime environments. A database module is a module that contains database artifacts, such as tables, views, procedures, or functions, that are deployed to a SAP HANA database. A HANA Deployment Infrastructure (HDI) container is a logical grouping of database objects that are isolated from other containers and schemas in the same database. An HDI container has its own technical user, roles, and privileges, and can be accessed only through a service binding. When a database module is built, the SAP Web IDE for SAP HANA or the SAP Business Application Studio automatically creates an HDI container and binds it as a resource to the database module. It also creates the runtime objects, such as physical tables or views, in the schema associated with the HDI container. Therefore, the runtime objects of a database module are created in the HDI container, which is the correct answer. The other options are incorrect because they are not the environments where the runtime objects of a database module are created. The Java Runtime Environment (JRE) is a software environment that provides the minimum requirements for executing a Java application. The SAP HANA Runtime Tools (HRTT) are a set of tools that enable developers to create, run, and debug SAP HANA native applications in Eclipse. The SAP Web IDE for SAP HANA is a web-based development environment that supports the development of MTA projects and modules. References:
- SAP HANA Platform 2.0 SPS06: Developing Multitarget Applications, Section 1.1
- SAP HANA Platform 2.0 SPS06: SAP HANA Deployment Infrastructure, Section 1
- SAP HANA Platform 2.0 SPS06: SAP HANA Database Application Development, Section 2.1
- SAP HANA Platform 2.0 SPS06: SAP HANA Database Application Development, Section 2.2
- SAP HANA Platform 2.0 SPS06: SAP HANA Database Application Development, Section 2.3
- SAP Business Application Studio Multitarget Application (MTA) development toolkit, Section 2
You implement a native SAP HANA application using SAP HANA extended application services, advanced model (XS advanced) and SAPUI5. Where is the UI rendering executed? Please choose the correct answer.
Options:
On the SAPUI5 HTML5 module
On the SAP Fiori front-end server
On the front-end client device
On the XS advanced application server
Answer:
CExplanation:
The UI rendering is executed on the front-end client device, such as a browser or a mobile device, that accesses the SAP HANA application. SAPUI5 is a JavaScript-based UI framework that enables the development of responsive and user-friendly web applications. SAPUI5 applications run in the browser and communicate with the back-end server via RESTful services, such as OData. The SAPUI5 HTML5 module is a component of the multi-target application (MTA) that contains the UI logic and resources, such as views, controllers, models, and libraries. The SAPUI5 HTML5 module is deployed to the XS advanced application server, which serves the static UI files to the front-end client device. The SAP Fiori front-end server is a separate component that provides the SAP Fiori launchpad, a single entry point for SAP Fiori apps, and the SAP Fiori UI components, such as controls, themes, and icons. The SAP Fiori front-end server is not required for SAP HANA native applications, but it can be used to integrate them with other SAP Fiori apps123. References:
- SAP HANA Platform, Developing Applications with SAP HANA Cloud Platform, Developing Multi-Target Applications, Developing HTML5 Modules
- SAP HANA Platform, SAP HANA Extended Application Services, Advanced Model, Developing and Deploying Applications, Developing HTML5 Applications
- SAP HANA Platform, SAP HANA Extended Application Services, Advanced Model, Developing and Deploying Applications, Developing SAP Fiori Applications
An OData service contains an entity set called Products. Which resource path do you add to the OData service URL to view all available products?
Please choose the correct answer.
Options:
/Products/$metadata
/Products/'
/Products
/Products/ALL
Answer:
CExplanation:
According to the SAP HANA Developer Guide, the resource path of an OData service URL identifies the entity or entity set that is requested. The resource path consists of the service root URI followed by a slash (/) and the name of the entity set. For example, to view all available products in the Products entity set, the resource path is /Products. The other options are incorrect, because:
- /Products/$metadata is not a valid resource path, but a system query option that returns the metadata document of the OData service.
- /Products/’ is not a valid resource path, but a syntax error. The single quotation mark is not needed after the entity set name.
- /Products/ALL is not a valid resource path, but a filter expression that can be used as a query option. The filter expression must be preceded by a question mark (?) and the $filter system query option. For example, /Products?$filter=ALL.
References: SAP HANA Developer Guide, Chapter 6, Section 6.4.2, page 2111.
Which OData capacity do you use when you need to restrict the number or selection of exposed columns? Please choose the correct answer.
Options:
Parameter entity sets
Aggregation
Key specification
Property projection
Answer:
DExplanation:
Property projection is an OData capability that allows you to restrict the number or selection of exposed columns in an OData service. Property projection is achieved by using the $select query option, which specifies a subset of properties to be included in the response. The $select query option can be applied to a single entity, a collection of entities, or a complex type. Property projection can be used to reduce the payload size and improve the performance of the OData service.
For example, suppose you have an OData service that exposes a Products entity set with the following properties: ID, Name, Category, Price, and Description. If you want to restrict the number or selection of exposed columns to only ID and Name, you can use the $select query option as follows:
GET /Products?$select=ID,Name
The result is:
{ “@odata.context”: “$metadata#Products(ID,Name)”, “value”: [ { “ID”: 1, “Name”: “Laptop” }, { “ID”: 2, “Name”: “Mouse” }, { “ID”: 3, “Name”: “Keyboard” } ] }
The following OData capabilities are not used to restrict the number or selection of exposed columns, but for other purposes:
- Parameter entity sets: Parameter entity sets are a way to define entity sets that require one or more parameters to be specified in the request. Parameter entity sets can be used to implement function imports or actions that return a collection of entities. Parameter entity sets can also be used to filter or sort the results based on the parameters.
- Aggregation: Aggregation is a way to apply aggregate functions, such as sum, count, min, max, or average, to the properties of an entity set or a complex type. Aggregation can be used to perform calculations or analysis on the data. Aggregation is achieved by using the $apply query option, which specifies a transformation pipeline with various operators, such as groupby, aggregate, filter, or order by.
- Key specification: Key specification is a way to define the key properties of an entity type, which uniquely identify an entity instance within an entity set. Key specification is part of the entity type definition in the metadata document of the OData service. Key specification can be used to retrieve a single entity by its key values.
References:
- [OData Version 4.0 Part 2: URL Conventions], Section 5.1.1: System Query Option $select, pp. 10-11.
- [OData Version 4.0 Part 3: Common Schema Definition Language (CSDL)], Section 13: Entity Model, Subsection 13.2: Entity Sets, pp. 88-89.
