Splunk Enterprise Certified Architect Questions and Answers
A customer has a four site indexer cluster. The customer has requirements to store five copies of searchable data, with one searchable copy of data at the origin site, and one searchable copy at the disaster recovery site (site4).
Which configuration meets these requirements?
Options:
site_replication_factor = origin:2, site4:l, total:3
site_replication_factor = origin:l, site4:l, total:5
site_search_factor = origin:2, site4:l, total:3
site search factor = origin:1, site4:l, total:5
Answer:
BExplanation:
The correct configuration to meet the customer’s requirements is site_replication_factor = origin:1, site4:1, total:5. This means that each bucket will have one copy at the origin site, one copy at the disaster recovery site (site4), and three copies at any other sites. The total number of copies will be five, as required by the customer. The site_replication_factor determines how many copies of each bucket are stored across the sites in a multisite indexer cluster1. The site_search_factor determines how many copies of each bucket are searchable across the sites in a multisite indexer cluster2. Therefore, option B is the correct answer, and options A, C, and D are incorrect.
1: Configure the site replication factor 2: Configure the site search factor
(Which command is used to initially add a search head to a single-site indexer cluster?)
Options:
splunk edit cluster-config -mode searchhead -manager_uri https://10.0.0.1:8089 -secret changeme
splunk edit cluster-config -mode peer -manager_uri https://10.0.0.1:8089 -secret changeme
splunk add cluster-manager -manager_uri https://10.0.0.1:8089 -secret changeme
splunk add cluster-manager -mode searchhead -manager_uri https://10.0.0.1:8089 -secret changeme
Answer:
AExplanation:
According to Splunk Enterprise Distributed Clustering documentation, when you add a search head to an indexer cluster, you must configure it to communicate with the Cluster Manager (previously known as Master Node). The proper way to initialize this connection is by editing the cluster configuration using the splunk edit cluster-config command.
The correct syntax for a search head is:
splunk edit cluster-config -mode searchhead -manager_uri
Here:
-mode searchhead specifies that this node will function as a search head that participates in distributed search across the indexer cluster.
-manager_uri provides the management URI of the cluster manager.
-secret defines the shared secret key used for secure communication between the manager and cluster members.
Once this configuration is applied, the search head must be restarted for the changes to take effect.
Using -mode peer (Option B) is for indexers joining the cluster, not search heads. The add cluster-manager command (Options C and D) is not a valid Splunk command.
References (Splunk Enterprise Documentation):
• Configure the Search Head for an Indexer Cluster
• Indexer Clustering: Configure the Cluster Manager, Peer, and Search Head Nodes
• Splunk Enterprise Admin Manual: splunk edit cluster-config Command Reference
When should a Universal Forwarder be used instead of a Heavy Forwarder?
Options:
When most of the data requires masking.
When there is a high-velocity data source.
When data comes directly from a database server.
When a modular input is needed.
Answer:
BExplanation:
According to the Splunk blog1, the Universal Forwarder is ideal for collecting data from high-velocity data sources, such as a syslog server, due to its smaller footprint and faster performance. The Universal Forwarder performs minimal processing and sends raw or unparsed data to the indexers, reducing the network traffic and the load on the forwarders. The other options are false because:
When most of the data requires masking, a Heavy Forwarder is needed, as it can perform advanced filtering and data transformation before forwarding the data2.
When data comes directly from a database server, a Heavy Forwarder is needed, as it can run modular inputs such as DB Connect to collect data from various databases2.
When a modular input is needed, a Heavy Forwarder is needed, as the Universal Forwarder does not include a bundled version of Python, which is required for most modular inputs2.
A multi-site indexer cluster can be configured using which of the following? (Select all that apply.)
Options:
Via Splunk Web.
Directly edit SPLUNK_HOME/etc./system/local/server.conf
Run a Splunk edit cluster-config command from the CLI.
Directly edit SPLUNK_HOME/etc/system/default/server.conf
Answer:
B, CExplanation:
A multi-site indexer cluster can be configured by directly editing SPLUNK_HOME/etc/system/local/server.conf or running a splunk edit cluster-config command from the CLI. These methods allow the administrator to specify the site attribute for each indexer node and the site_replication_factor and site_search_factor for the cluster. Configuring a multi-site indexer cluster via Splunk Web or directly editing SPLUNK_HOME/etc/system/default/server.conf are not supported methods. For more information, see Configure the indexer cluster with server.conf in the Splunk documentation.
In an existing Splunk environment, the new index buckets that are created each day are about half the size of the incoming data. Within each bucket, about 30% of the space is used for rawdata and about 70% for index files.
What additional information is needed to calculate the daily disk consumption, per indexer, if indexer clustering is implemented?
Options:
Total daily indexing volume, number of peer nodes, and number of accelerated searches.
Total daily indexing volume, number of peer nodes, replication factor, and search factor.
Total daily indexing volume, replication factor, search factor, and number of search heads.
Replication factor, search factor, number of accelerated searches, and total disk size across cluster.
Answer:
BExplanation:
The additional information that is needed to calculate the daily disk consumption, per indexer, if indexer clustering is implemented, is the total daily indexing volume, the number of peer nodes, the replication factor, and the search factor. These information are required to estimate how much data is ingested, how many copies of raw data and searchable data are maintained, and how many indexers are involved in the cluster. The number of accelerated searches, the number of search heads, and the total disk size across the cluster are not relevant for calculating the daily disk consumption, per indexer. For more information, see [Estimate your storage requirements] in the Splunk documentation.
Which of the following are client filters available in serverclass.conf? (Select all that apply.)
Options:
DNS name.
IP address.
Splunk server role.
Platform (machine type).
Answer:
A, B, DExplanation:
The client filters available in serverclass.conf are DNS name, IP address, and platform (machine type). These filters allow the administrator to specify which forwarders belong to a server class and receive the apps and configurations from the deployment server. The Splunk server role is not a valid client filter in serverclass.conf, as it is not a property of the forwarder. For more information, see [Use forwarder management filters] in the Splunk documentation.
Which search head cluster component is responsible for pushing knowledge bundles to search peers, replicating configuration changes to search head cluster members, and scheduling jobs across the search head cluster?
Options:
Master
Captain
Deployer
Deployment server
Answer:
BExplanation:
The captain is the search head cluster component that is responsible for pushing knowledge bundles to search peers, replicating configuration changes to search head cluster members, and scheduling jobs across the search head cluster. The captain is elected from among the search head cluster members and performs these tasks in addition to serving search requests. The master is the indexer cluster component that is responsible for managing the replication and availability of data across the peer nodes. The deployer is the standalone instance that is responsible for distributing apps and other configurations to the search head cluster members. The deployment server is the instance that is responsible for distributing apps and other configurations to the deployment clients, such as forwarders
Which of the following is unsupported in a production environment?
Options:
Cluster Manager can run on the Monitoring Console instance in smaller environments.
Search Head Cluster Deployer can run on the Monitoring Console instance in smaller environments.
Search heads in a Search Head Cluster can run on virtual machines.
Indexers in an indexer cluster can run on virtual machines.
Answer:
A, DExplanation:
Comprehensive and Detailed Explanation (From Splunk Enterprise Documentation)Splunk Enterprise documentation clarifies that none of the listed configurations are prohibited in production. Splunk allows the Cluster Manager to be colocated with the Monitoring Console in small deployments because both are management-plane functions and do not handle ingestion or search traffic. The documentation also states that the Search Head Cluster Deployer is not a runtime component and has minimal performance requirements, so it may be colocated with the Monitoring Console or Licensing Master when hardware resources permit.
Splunk also supports virtual machines for both search heads and indexers, provided they are deployed with dedicated CPU, storage throughput, and predictable performance. Splunk’s official hardware guidance specifies that while bare metal often yields higher performance, virtualized deployments are fully supported in production as long as sizing principles are met.
Because Splunk explicitly supports all four configurations under proper sizing and best-practice guidelines, there is no correct selection for “unsupported.” The question is outdated relative to current Splunk Enterprise recommendations.
Which props.conf setting has the least impact on indexing performance?
Options:
SHOULD_LINEMERGE
TRUNCATE
CHARSET
TIME_PREFIX
Answer:
CExplanation:
According to the Splunk documentation1, the CHARSET setting in props.conf specifies the character set encoding of the source data. This setting has the least impact on indexing performance, as it only affects how Splunk interprets the bytes of the data, not how it processes or transforms the data. The other options are false because:
The SHOULD_LINEMERGE setting in props.conf determines whether Splunk breaks events based on timestamps or newlines. This setting has a significant impact on indexing performance, as it affects how Splunk parses the data and identifies the boundaries of the events2.
The TRUNCATE setting in props.conf specifies the maximum number of characters that Splunk indexes from a single line of a file. This setting has a moderate impact on indexing performance, as it affects how much data Splunk reads and writes to the index3.
The TIME_PREFIX setting in props.conf specifies the prefix that directly precedes the timestamp in the event data. This setting has a moderate impact on indexing performance, as it affects how Splunk extracts the timestamp and assigns it to the event
Which of the following is a problem that could be investigated using the Search Job Inspector?
Options:
Error messages are appearing underneath the search bar in Splunk Web.
Dashboard panels are showing "Waiting for queued job to start" on page load.
Different users are seeing different extracted fields from the same search.
Events are not being sorted in reverse chronological order.
Answer:
AExplanation:
According to the Splunk documentation1, the Search Job Inspector is a tool that you can use to troubleshoot search performance and understand the behavior of knowledge objects, such as event types, tags, lookups, and so on, within the search. You can inspect search jobs that are currently running or that have finished recently. The Search Job Inspector can help you investigate error messages that appear underneath the search bar in Splunk Web, as it can show you the details of the search job, such as the search string, the search mode, the search timeline, the search log, the search profile, and the search properties. You can use this information to identify the cause of the error and fix it2. The other options are false because:
Dashboard panels showing “Waiting for queued job to start” on page load is not a problem that can be investigated using the Search Job Inspector, as it indicates that the search job has not started yet. This could be due to the search scheduler being busy or the search priority being low. You can use the Jobs page or the Monitoring Console to monitor the status of the search jobs and adjust the priority or concurrency settings if needed3.
Different users seeing different extracted fields from the same search is not a problem that can be investigated using the Search Job Inspector, as it is related to the user permissions and the knowledge object sharing settings. You can use the Access Controls page or the Knowledge Manager to manage the user roles and the knowledge object visibility4.
Events not being sorted in reverse chronological order is not a problem that can be investigated using the Search Job Inspector, as it is related to the search syntax and the sort command. You can use the Search Manual or the Search Reference to learn how to use the sort command and its options to sort the events by any field or criteria.
Which Splunk log file would be the least helpful in troubleshooting a crash?
Options:
splunk_instrumentation.log
splunkd_stderr.log
crash-2022-05-13-ll:42:57.1og
splunkd.log
Answer:
AExplanation:
The splunk_instrumentation.log file is the least helpful in troubleshooting a crash, because it contains information about the Splunk Instrumentation feature, which collects and sends usage data to Splunk Inc. for product improvement purposes. This file does not contain any information about the Splunk processes, errors, or crashes. The other options are more helpful in troubleshooting a crash, because they contain relevant information about the Splunk daemon, the standard error output, and the crash report12
1:
What information is written to the __introspection log file?
Options:
File monitor input configurations.
File monitor checkpoint offset.
User activities and knowledge objects.
KV store performance.
Answer:
DExplanation:
The __introspection log file contains data about the impact of the Splunk software on the host system, such as CPU, memory, disk, and network usage, as well as KV store performance1. This log file is monitored by default and the contents are sent to the _introspection index1. The other options are not related to the __introspection log file. File monitor input configurations are stored in inputs.conf2. File monitor checkpoint offset is stored in fishbucket3. User activities and knowledge objects are stored in the _audit and _internal indexes respectively4.
Which of the following commands is used to clear the KV store?
Options:
splunk clean kvstore
splunk clear kvstore
splunk delete kvstore
splunk reinitialize kvstore
Answer:
AExplanation:
The splunk clean kvstore command is used to clear the KV store. This command will delete all the collections and documents in the KV store and reset it to an empty state. This command can be useful for troubleshooting KV store issues or resetting the KV store data. The splunk clear kvstore, splunk delete kvstore, and splunk reinitialize kvstore commands are not valid Splunk commands. For more information, see Use the CLI to manage the KV store in the Splunk documentation.
On search head cluster members, where in $splunk_home does the Splunk Deployer deploy app content by default?
Options:
etc/apps/
etc/slave-apps/
etc/shcluster/
etc/deploy-apps/
Answer:
BExplanation:
According to the Splunk documentation1, the Splunk Deployer deploys app content to the etc/slave-apps/ directory on the search head cluster members by default. This directory contains the apps that the deployer distributes to the members as part of the configuration bundle. The other options are false because:
The etc/apps/ directory contains the apps that are installed locally on each member, not the apps that are distributed by the deployer2.
The etc/shcluster/ directory contains the configuration files for the search head cluster, not the apps that are distributed by the deployer3.
The etc/deploy-apps/ directory is not a valid Splunk directory, as it does not exist in the Splunk file system structure4.
Users who receive a link to a search are receiving an "Unknown sid" error message when they open the link.
Why is this happening?
Options:
The users have insufficient permissions.
An add-on needs to be updated.
The search job has expired.
One or more indexers are down.
Answer:
CExplanation:
According to the Splunk documentation1, the “Unknown sid” error message means that the search job associated with the link has expired or been deleted. The sid (search ID) is a unique identifier for each search job, and it is used to retrieve the results of the search. If the sid is not found, the search cannot be displayed. The other options are false because:
The users having insufficient permissions would result in a different error message, such as “You do not have permission to view this page” or "You do not have permission to run this search"1.
An add-on needing to be updated would not affect the validity of the sid, unless the add-on changes the search syntax or the data source in a way that makes the search invalid or inaccessible1.
One or more indexers being down would not cause the “Unknown sid” error, as the sid is stored on the search head, not the indexers. However, it could cause other errors, such as “Unable to distribute to peer” or "Search peer has the following message: not enough disk space"1.
A single-site indexer cluster has a replication factor of 3, and a search factor of 2. What is true about this cluster?
Options:
The cluster will ensure there are at least two copies of each bucket, and at least three copies of searchable metadata.
The cluster will ensure there are at most three copies of each bucket, and at most two copies of searchable metadata.
The cluster will ensure only two search heads are allowed to access the bucket at the same time.
The cluster will ensure there are at least three copies of each bucket, and at least two copies of searchable metadata.
Answer:
DExplanation:
A single-site indexer cluster is a group of Splunk Enterprise instances that index and replicate data across the cluster1. A bucket is a directory that contains indexed data, along with metadata and other information2. A replication factor is the number of copies of each bucket that the cluster maintains1. A search factor is the number of searchable copies of each bucket that the cluster maintains1. A searchable copy is a copy that contains both the raw data and the index files3. A search head is a Splunk Enterprise instance that coordinates the search activities across the peer nodes1.
Option D is the correct answer because it reflects the definitions of replication factor and search factor. The cluster will ensure that there are at least three copies of each bucket, one on each peer node, to satisfy the replication factor of 3. The cluster will also ensure that there are at least two searchable copies of each bucket, one primary and one searchable, to satisfy the search factor of 2. The primary copy is the one that the search head uses to run searches, and the searchable copy is the one that can be promoted to primary if the original primary copy becomes unavailable3.
Option A is incorrect because it confuses the replication factor and the search factor. The cluster will ensure there are at least three copies of each bucket, not two, to meet the replication factor of 3. The cluster will ensure there are at least two copies of searchable metadata, not three, to meet the search factor of 2.
Option B is incorrect because it uses the wrong terms. The cluster will ensure there are at least, not at most, three copies of each bucket, to meet the replication factor of 3. The cluster will ensure there are at least, not at most, two copies of searchable metadata, to meet the search factor of 2.
Option C is incorrect because it has nothing to do with the replication factor or the search factor. The cluster does not limit the number of search heads that can access the bucket at the same time. The search head can search across multiple clusters, and the cluster can serve multiple search heads1.
1: The basics of indexer cluster architecture - Splunk Documentation 2: About buckets - Splunk Documentation 3: Search factor - Splunk Documentation
Which of the following security options must be explicitly configured (i.e. which options are not enabled by default)?
Options:
Data encryption between Splunk Web and splunkd.
Certificate authentication between forwarders and indexers.
Certificate authentication between Splunk Web and search head.
Data encryption for distributed search between search heads and indexers.
Answer:
BExplanation:
The following security option must be explicitly configured, as it is not enabled by default:
Certificate authentication between forwarders and indexers. This option allows the forwarders and indexers to verify each other’s identity using SSL certificates, which prevents unauthorized data transmission or spoofing attacks. This option is not enabled by default, as it requires the administrator to generate and distribute the certificates for the forwarders and indexers. For more information, see [Secure the communication between forwarders and indexers] in the Splunk documentation. The following security options are enabled by default:
Data encryption between Splunk Web and splunkd. This option encrypts the communication between the Splunk Web interface and the splunkd daemon using SSL, which prevents data interception or tampering. This option is enabled by default, as Splunk provides a self-signed certificate for this purpose. For more information, see [About securing Splunk Enterprise with SSL] in the Splunk documentation.
Certificate authentication between Splunk Web and search head. This option allows the Splunk Web interface and the search head to verify each other’s identity using SSL certificates, which prevents unauthorized access or spoofing attacks. This option is enabled by default, as Splunk provides a self-signed certificate for this purpose. For more information, see [About securing Splunk Enterprise with SSL] in the Splunk documentation.
Data encryption for distributed search between search heads and indexers. This option encrypts the communication between the search heads and the indexers using SSL, which prevents data interception or tampering. This option is enabled by default, as Splunk provides a self-signed certificate for this purpose. For more information, see [Secure your distributed search environment] in the Splunk documentation.
What information is needed about the current environment before deploying Splunk? (select all that apply)
Options:
List of vendors for network devices.
Overall goals for the deployment.
Key users.
Data sources.
Answer:
B, C, DExplanation:
Before deploying Splunk, it is important to gather some information about the current environment, such as:
Overall goals for the deployment: This includes the business objectives, the use cases, the expected outcomes, and the success criteria for the Splunk deployment. This information helps to define the scope, the requirements, the design, and the validation of the Splunk solution1.
Key users: This includes the roles, the responsibilities, the expectations, and the needs of the different types of users who will interact with the Splunk deployment, such as administrators, analysts, developers, and end users. This information helps to determine the user access, the user experience, the user training, and the user feedback for the Splunk solution1.
Data sources: This includes the types, the formats, the volumes, the locations, and the characteristics of the data that will be ingested, indexed, and searched by the Splunk deployment. This information helps to estimate the data throughput, the data retention, the data quality, and the data analysis for the Splunk solution1.
Option B, C, and D are the correct answers because they reflect the essential information that is needed before deploying Splunk. Option A is incorrect because the list of vendors for network devices is not a relevant information for the Splunk deployment. The network devices may be part of the data sources, but the vendors are not important for the Splunk solution.
What is the logical first step when starting a deployment plan?
Options:
Inventory the currently deployed logging infrastructure.
Determine what apps and use cases will be implemented.
Gather statistics on the expected adoption of Splunk for sizing.
Collect the initial requirements for the deployment from all stakeholders.
Answer:
DExplanation:
The logical first step when starting a deployment plan is to collect the initial requirements for the deployment from all stakeholders. This includes identifying the business objectives, the data sources, the use cases, the security and compliance needs, the scalability and availability expectations, and the budget and timeline constraints. Collecting the initial requirements helps to define the scope and the goals of the deployment, and to align the expectations of all the parties involved.
Inventorying the currently deployed logging infrastructure, determining what apps and use cases will be implemented, and gathering statistics on the expected adoption of Splunk for sizing are all important steps in the deployment planning process, but they are not the logical first step. These steps can be done after collecting the initial requirements, as they depend on the information gathered from the stakeholders.
Which command will permanently decommission a peer node operating in an indexer cluster?
Options:
splunk stop -f
splunk offline -f
splunk offline --enforce-counts
splunk decommission --enforce counts
Answer:
CExplanation:
The splunk offline --enforce-counts command will permanently decommission a peer node operating in an indexer cluster. This command will remove the peer node from the cluster and delete its data. This command should be used when the peer node is no longer needed or is being replaced by another node. The splunk stop -f command will stop the Splunk service on the peer node, but it will not decommission it from the cluster. The splunk offline -f command will take the peer node offline, but it will not delete its data or enforce the replication and search factors. The splunk decommission --enforce-counts command is not a valid Splunk command. For more information, see Remove a peer node from an indexer cluster in the Splunk documentation.
A Splunk architect has inherited the Splunk deployment at Buttercup Games and end users are complaining that the events are inconsistently formatted for a web source. Further investigation reveals that not all weblogs flow through the same infrastructure: some of the data goes through heavy forwarders and some of the forwarders are managed by another department.
Which of the following items might be the cause of this issue?
Options:
The search head may have different configurations than the indexers.
The data inputs are not properly configured across all the forwarders.
The indexers may have different configurations than the heavy forwarders.
The forwarders managed by the other department are an older version than the rest.
Answer:
CExplanation:
The indexers may have different configurations than the heavy forwarders, which might cause the issue of inconsistently formatted events for a web sourcetype. The heavy forwarders perform parsing and indexing on the data before sending it to the indexers. If the indexers have different configurations than the heavy forwarders, such as different props.conf or transforms.conf settings, the data may be parsed or indexed differently on the indexers, resulting in inconsistent events. The search head configurations do not affect the event formatting, as the search head does not parse or index the data. The data inputs configurations on the forwarders do not affect the event formatting, as the data inputs only determine what data to collect and how to monitor it. The forwarder version does not affect the event formatting, as long as the forwarder is compatible with the indexer. For more information, see [Heavy forwarder versus indexer] and [Configure event processing] in the Splunk documentation.
When troubleshooting monitor inputs, which command checks the status of the tailed files?
Options:
splunk cmd btool inputs list | tail
splunk cmd btool check inputs layer
Answer:
CExplanation:
The curl command is used to check the status of the tailed files when troubleshooting monitor inputs. Monitor inputs are inputs that monitor files or directories for new data and send the data to Splunk for indexing. The TailingProcessor:FileStatus endpoint returns information about the files that are being monitored by the Tailing Processor, such as the file name, path, size, position, and status. The splunk cmd btool inputs list | tail command is used to list the inputs configurations from the inputs.conf file and pipe the output to the tail command. The splunk cmd btool check inputs layer command is used to check the inputs configurations for syntax errors and layering. The curl command does not exist, and it is not a valid endpoint.
A search head cluster with a KV store collection can be updated from where in the KV store collection?
Options:
The search head cluster captain.
The KV store primary search head.
Any search head except the captain.
Any search head in the cluster.
Answer:
DExplanation:
According to the Splunk documentation1, any search head in the cluster can update the KV store collection. The KV store collection is replicated across all the cluster members, and any write operation is delegated to the KV store captain, who then synchronizes the changes with the other members. The KV store primary search head is not a valid term, as there is no such role in a search head cluster. The other options are false because:
The search head cluster captain is not the only node that can update the KV store collection, as any member can initiate a write operation1.
Any search head except the captain can also update the KV store collection, as the write operation will be delegated to the captain1.
Other than high availability, which of the following is a benefit of search head clustering?
Options:
Allows indexers to maintain multiple searchable copies of all data.
Input settings are synchronized between search heads.
Fewer network ports are required to be opened between search heads.
Automatic replication of user knowledge objects.
Answer:
DExplanation:
According to the Splunk documentation1, one of the benefits of search head clustering is the automatic replication of user knowledge objects, such as dashboards, reports, alerts, and tags. This ensures that all cluster members have the same set of knowledge objects and can serve the same search results to the users. The other options are false because:
Allowing indexers to maintain multiple searchable copies of all data is a benefit of indexer clustering, not search head clustering2.
Input settings are not synchronized between search heads, as search head clusters do not collect data from inputs. Data collection is done by forwarders or independent search heads3.
Fewer network ports are not required to be opened between search heads, as search head clusters use several ports for communication and replication among the members4.
Which Splunk internal index contains license-related events?
Options:
_audit
_license
_internal
_introspection
Answer:
CExplanation:
The _internal index contains license-related events, such as the license usage, the license quota, the license pool, the license stack, and the license violations. These events are logged by the license manager in the license_usage.log file, which is part of the _internal index. The _audit index contains audit events, such as user actions, configuration changes, and search activity. These events are logged by the audit trail in the audit.log file, which is part of the _audit index. The _license index does not exist in Splunk, as the license-related events are stored in the _internal index. The _introspection index contains platform instrumentation data, such as the resource usage, the disk objects, the search activity, and the data ingestion. These data are logged by the introspection generator in various log files, such as resource_usage.log, disk_objects.log, search_activity.log, and data_ingestion.log, which are part of the _introspection index. For more information, see About Splunk Enterprise logging and [About the _internal index] in the Splunk documentation.
When adding or decommissioning a member from a Search Head Cluster (SHC), what is the proper order of operations?
Options:
1. Delete Splunk Enterprise, if it exists.2. Install and initialize the instance.3. Join the SHC.
1. Install and initialize the instance.2. Delete Splunk Enterprise, if it exists.3. Join the SHC.
1. Initialize cluster rebalance operation.2. Remove master node from cluster.3. Trigger replication.
1. Trigger replication.2. Remove master node from cluster.3. Initialize cluster rebalance operation.
Answer:
AExplanation:
When adding or decommissioning a member from a Search Head Cluster (SHC), the proper order of operations is:
Delete Splunk Enterprise, if it exists.
Install and initialize the instance.
Join the SHC.
This order of operations ensures that the member has a clean and consistent Splunk installation before joining the SHC. Deleting Splunk Enterprise removes any existing configurations and data from the instance. Installing and initializing the instance sets up the Splunk software and the required roles and settings for the SHC. Joining the SHC adds the instance to the cluster and synchronizes the configurations and apps with the other members. The other order of operations are not correct, because they either skip a step or perform the steps in the wrong order.
(Based on the data sizing and retention parameters listed below, which of the following will correctly calculate the index storage required?)
• Daily rate = 20 GB / day
• Compress factor = 0.5
• Retention period = 30 days
• Padding = 100 GB
Options:
(20 * 30 + 100) * 0.5 = 350 GB
20 / 0.5 * 30 + 100 = 1300 GB
20 * 0.5 * 30 + 100 = 400 GB
20 * 30 + 100 = 700 GB
Answer:
CExplanation:
The Splunk Capacity Planning Manual defines the total required storage for indexes as a function of daily ingest rate, compression factor, retention period, and an additional padding buffer for index management and growth.
The formula is:
Storage = (Daily Data * Compression Factor * Retention Days) + Padding
Given the values:
Daily rate = 20 GB
Compression factor = 0.5 (50% reduction)
Retention period = 30 days
Padding = 100 GB
Plugging these into the formula gives:
20 * 0.5 * 30 + 100 = 400 GB
This result represents the estimated storage needed to retain 30 days of compressed indexed data with an additional buffer to accommodate growth and Splunk’s bucket management overhead.
Compression factor values typically range between 0.5 and 0.7 for most environments, depending on data type. Using compression in calculations is critical, as indexed data consumes less space than raw input after Splunk’s tokenization and compression processes.
Other options either misapply the compression ratio or the order of operations, producing incorrect totals.
References (Splunk Enterprise Documentation):
• Capacity Planning for Indexes – Storage Sizing and Compression Guidelines
• Managing Index Storage and Retention Policies
• Splunk Enterprise Admin Manual – Understanding Index Bucket Sizes
• Indexing Performance and Storage Optimization Guide
When should multiple search pipelines be enabled?
Options:
Only if disk IOPS is at 800 or better.
Only if there are fewer than twelve concurrent users.
Only if running Splunk Enterprise version 6.6 or later.
Only if CPU and memory resources are significantly under-utilized.
Answer:
DExplanation:
Multiple search pipelines should be enabled only if CPU and memory resources are significantly under-utilized. Search pipelines are the processes that execute search commands and return results. Multiple search pipelines can improve the search performance by running concurrent searches in parallel. However, multiple search pipelines also consume more CPU and memory resources, which can affect the overall system performance. Therefore, multiple search pipelines should be enabled only if there are enough CPU and memory resources available, and if the system is not bottlenecked by disk I/O or network bandwidth. The number of concurrent users, the disk IOPS, and the Splunk Enterprise version are not relevant factors for enabling multiple search pipelines
When designing the number and size of indexes, which of the following considerations should be applied?
Options:
Expected daily ingest volume, access controls, number of concurrent users
Number of installed apps, expected daily ingest volume, data retention time policies
Data retention time policies, number of installed apps, access controls
Expected daily ingest volumes, data retention time policies, access controls
Answer:
DExplanation:
When designing the number and size of indexes, the following considerations should be applied:
Expected daily ingest volumes: This is the amount of data that will be ingested and indexed by the Splunk platform per day. This affects the storage capacity, the indexing performance, and the license usage of the Splunk deployment. The number and size of indexes should be planned according to the expected daily ingest volumes, as well as the peak ingest volumes, to ensure that the Splunk deployment can handle the data load and meet the business requirements12.
Data retention time policies: This is the duration for which the data will be stored and searchable by the Splunk platform. This affects the storage capacity, the data availability, and the data compliance of the Splunk deployment. The number and size of indexes should be planned according to the data retention time policies, as well as the data lifecycle, to ensure that the Splunk deployment can retain the data for the desired period and meet the legal or regulatory obligations13.
Access controls: This is the mechanism for granting or restricting access to the data by the Splunk users or roles. This affects the data security, the data privacy, and the data governance of the Splunk deployment. The number and size of indexes should be planned according to the access controls, as well as the data sensitivity, to ensure that the Splunk deployment can protect the data from unauthorized or inappropriate access and meet the ethical or organizational standards14.
Option D is the correct answer because it reflects the most relevant and important considerations for designing the number and size of indexes. Option A is incorrect because the number of concurrent users is not a direct factor for designing the number and size of indexes, but rather a factor for designing the search head capacity and the search head clustering configuration5. Option B is incorrect because the number of installed apps is not a direct factor for designing the number and size of indexes, but rather a factor for designing the app compatibility and the app performance. Option C is incorrect because it omits the expected daily ingest volumes, which is a crucial factor for designing the number and size of indexes.
Which Splunk Enterprise offering has its own license?
Options:
Splunk Cloud Forwarder
Splunk Heavy Forwarder
Splunk Universal Forwarder
Splunk Forwarder Management
Answer:
CExplanation:
The Splunk Universal Forwarder is the only Splunk Enterprise offering that has its own license. The Splunk Universal Forwarder license allows the forwarder to send data to any Splunk Enterprise or Splunk Cloud instance without consuming any license quota. The Splunk Heavy Forwarder does not have its own license, but rather consumes the license quota of the Splunk Enterprise or Splunk Cloud instance that it sends data to. The Splunk Cloud Forwarder and the Splunk Forwarder Management are not separate Splunk Enterprise offerings, but rather features of the Splunk Cloud service. For more information, see [About forwarder licensing] in the Splunk documentation.
What does setting site=site0 on all Search Head Cluster members do in a multi-site indexer cluster?
Options:
Disables search site affinity.
Sets all members to dynamic captaincy.
Enables multisite search artifact replication.
Enables automatic search site affinity discovery.
Answer:
AExplanation:
Setting site=site0 on all Search Head Cluster members disables search site affinity. Search site affinity is a feature that allows search heads to preferentially search the peer nodes that are in the same site as the search head, to reduce network latency and bandwidth consumption. By setting site=site0, which is a special value that indicates no site, the search heads will search all peer nodes regardless of their site. Setting site=site0 does not set all members to dynamic captaincy, enable multisite search artifact replication, or enable automatic search site affinity discovery. Dynamic captaincy is a feature that allows any member to become the captain, and it is enabled by default. Multisite search artifact replication is a feature that allows search artifacts to be replicated across sites, and it is enabled by setting site_replication_factor to a value greater than 1. Automatic search site affinity discovery is a feature that allows search heads to automatically determine their site based on the network latency to the peer nodes, and it is enabled by setting site=auto
Which Splunk server role regulates the functioning of indexer cluster?
Options:
Indexer
Deployer
Master Node
Monitoring Console
Answer:
CExplanation:
The master node is the Splunk server role that regulates the functioning of the indexer cluster. The master node coordinates the activities of the peer nodes, such as data replication, data searchability, and data recovery. The master node also manages the cluster configuration bundle and distributes it to the peer nodes. The indexer is the Splunk server role that indexes the incoming data and makes it searchable. The deployer is the Splunk server role that distributes apps and configuration updates to the search head cluster members. The monitoring console is the Splunk server role that monitors the health and performance of the Splunk deployment. For more information, see About indexer clusters and index replication in the Splunk documentation.
Which of the following artifacts are included in a Splunk diag file? (Select all that apply.)
Options:
OS settings.
Internal logs.
Customer data.
Configuration files.
Answer:
B, DExplanation:
The following artifacts are included in a Splunk diag file:
Internal logs. These are the log files that Splunk generates to record its own activities, such as splunkd.log, metrics.log, audit.log, and others. These logs can help troubleshoot Splunk issues and monitor Splunk performance.
Configuration files. These are the files that Splunk uses to configure various aspects of its operation, such as server.conf, indexes.conf, props.conf, transforms.conf, and others. These files can help understand Splunk settings and behavior. The following artifacts are not included in a Splunk diag file:
OS settings. These are the settings of the operating system that Splunk runs on, such as the kernel version, the memory size, the disk space, and others. These settings are not part of the Splunk diag file, but they can be collected separately using the diag --os option.
Customer data. These are the data that Splunk indexes and makes searchable, such as the rawdata and the tsidx files. These data are not part of the Splunk diag file, as they may contain sensitive or confidential information. For more information, see Generate a diagnostic snapshot of your Splunk Enterprise deployment in the Splunk documentation.
What log file would you search to verify if you suspect there is a problem interpreting a regular expression in a monitor stanza?
Options:
btool.log
metrics.log
splunkd.log
tailing_processor.log
Answer:
DExplanation:
The tailing_processor.log file would be the best place to search if you suspect there is a problem interpreting a regular expression in a monitor stanza. This log file contains information about how Splunk monitors files and directories, including any errors or warnings related to parsing the monitor stanza. The splunkd.log file contains general information about the Splunk daemon, but it may not have the specific details about the monitor stanza. The btool.log file contains information about the configuration files, but it does not log the runtime behavior of the monitor stanza. The metrics.log file contains information about the performance metrics of Splunk, but it does not log the event breaking issues. For more information, see About Splunk Enterprise logging in the Splunk documentation.
(How can a Splunk admin control the logging level for a specific search to get further debug information?)
Options:
Configure infocsv_log_level = DEBUG in limits.conf.
Insert | noop log_debug=* after the base search.
Open the Search Job Inspector in Splunk Web and modify the log level.
Use Settings > Server settings > Server logging in Splunk Web.
Answer:
BExplanation:
Splunk Enterprise allows administrators to dynamically increase logging verbosity for a specific search by adding a | noop log_debug=* command immediately after the base search. This method provides temporary, search-specific debug logging without requiring global configuration changes or restarts.
The noop (no operation) command passes all results through unchanged but can trigger internal logging actions. When paired with the log_debug=* argument, it instructs Splunk to record detailed debug-level log messages for that specific search execution in search.log and the relevant internal logs.
This approach is officially documented for troubleshooting complex search issues such as:
Unexpected search behavior or slow performance.
Field extraction or command evaluation errors.
Debugging custom search commands or macros.
Using this method is safer and more efficient than modifying server-wide logging configurations (server.conf or limits.conf), which can affect all users and increase log noise. The “Server logging” page in Splunk Web (Option D) adjusts global logging levels, not per-search debugging.
References (Splunk Enterprise Documentation):
• Search Debugging Techniques and the noop Command
• Understanding search.log and Per-Search Logging Control
• Splunk Search Job Inspector and Debugging Workflow
• Troubleshooting SPL Performance and Field Extraction Issues
Configurations from the deployer are merged into which location on the search head cluster member?
Options:
SPLUNK_HOME/etc/system/local
SPLUNK_HOME/etc/apps/APP_HOME/local
SPLUNK_HOME/etc/apps/search/default
SPLUNK_HOME/etc/apps/APP_HOME/default
Answer:
BExplanation:
Configurations from the deployer are merged into the SPLUNK_HOME/etc/apps/APP_HOME/local directory on the search head cluster member. The deployer distributes apps and other configurations to the search head cluster members in the form of a configuration bundle. The configuration bundle contains the contents of the SPLUNK_HOME/etc/shcluster/apps directory on the deployer. When a search head cluster member receives the configuration bundle, it merges the contents of the bundle into its own SPLUNK_HOME/etc/apps directory. The configurations in the local directory take precedence over the configurations in the default directory. The SPLUNK_HOME/etc/system/local directory is used for system-level configurations, not app-level configurations. The SPLUNK_HOME/etc/apps/search/default directory is used for the default configurations of the search app, not the configurations from the deployer.
(A new Splunk Enterprise deployment is being architected, and the customer wants to ensure that the data to be indexed is encrypted. Where should TLS be turned on in the Splunk deployment?)
Options:
Deployment server to deployment clients.
Splunk forwarders to indexers.
Indexer cluster peer nodes.
Browser to Splunk Web.
Answer:
BExplanation:
The Splunk Enterprise Security and Encryption documentation specifies that the primary mechanism for securing data in motion within a Splunk environment is to enable TLS/SSL encryption between forwarders and indexers. This ensures that log data transmitted from Universal Forwarders or Heavy Forwarders to Indexers is fully encrypted and protected from interception or tampering.
The correct configuration involves setting up signed SSL certificates on both forwarders and indexers:
On the forwarder, TLS settings are defined in outputs.conf, specifying parameters like sslCertPath, sslPassword, and sslRootCAPath.
On the indexer, TLS is enabled in inputs.conf and server.conf using the same shared CA for validation.
Splunk’s documentation explicitly states that this configuration protects data-in-transit between the collection (forwarder) and indexing (storage) tiers — which is the critical link where sensitive log data is most vulnerable.
Other communication channels (e.g., deployment server to clients or browser to Splunk Web) can also use encryption but do not secure the ingestion pipeline that handles the indexed data stream. Therefore, TLS should be implemented between Splunk forwarders and indexers.
References (Splunk Enterprise Documentation):
• Securing Data in Transit with SSL/TLS
• Configure Forwarder-to-Indexer Encryption Using SSL Certificates
• Server and Forwarder Authentication Setup Guide
• Splunk Enterprise Admin Manual – Security and Encryption Best Practices
Data for which of the following indexes will count against an ingest-based license?
Options:
summary
main
_metrics
_introspection
Answer:
BExplanation:
Splunk Enterprise licensing is based on the amount of data that is ingested and indexed by the Splunk platform per day1. The data that counts against the license is the data that is stored in the indexes that are visible to the users and searchable by the Splunk software2. The indexes that are visible and searchable by default are the main index and any custom indexes that are created by the users or the apps3. The main index is the default index where Splunk Enterprise stores all data, unless otherwise specified4.
Option B is the correct answer because the data for the main index will count against the ingest-based license, as it is a visible and searchable index by default. Option A is incorrect because the summary index is a special type of index that stores the results of scheduled reports or accelerated data models, which do not count against the license. Option C is incorrect because the _metrics index is an internal index that stores metrics data about the Splunk platform performance, which does not count against the license. Option D is incorrect because the _introspection index is another internal index that stores data about the impact of the Splunk software on the host system, such as CPU, memory, disk, and network usage, which does not count against the license.
Which server.conf attribute should be added to the master node's server.conf file when decommissioning a site in an indexer cluster?
Options:
site_mappings
available_sites
site_search_factor
site_replication_factor
Answer:
AExplanation:
The site_mappings attribute should be added to the master node’s server.conf file when decommissioning a site in an indexer cluster. The site_mappings attribute is used to specify how the master node should reassign the buckets from the decommissioned site to the remaining sites. The site_mappings attribute is a comma-separated list of site pairs, where the first site is the decommissioned site and the second site is the destination site. For example, site_mappings = site1:site2,site3:site4 means that the buckets from site1 will be moved to site2, and the buckets from site3 will be moved to site4. The available_sites attribute is used to specify which sites are currently available in the cluster, and it is automatically updated by the master node. The site_search_factor and site_replication_factor attributes are used to specify the number of searchable and replicated copies of each bucket for each site, and they are not affected by the decommissioning process
Which of the following are possible causes of a crash in Splunk? (select all that apply)
Options:
Incorrect ulimit settings.
Insufficient disk IOPS.
Insufficient memory.
Running out of disk space.
Answer:
A, B, C, DExplanation:
All of the options are possible causes of a crash in Splunk. According to the Splunk documentation1, incorrect ulimit settings can lead to file descriptor exhaustion, which can cause Splunk to crash or hang. Insufficient disk IOPS can also cause Splunk to crash or become unresponsive, as Splunk relies heavily on disk performance2. Insufficient memory can cause Splunk to run out of memory and crash, especially when running complex searches or handling large volumes of data3. Running out of disk space can cause Splunk to stop indexing data and crash, as Splunk needs enough disk space to store its data and logs4.
1: Configure ulimit settings for Splunk Enterprise 2: Troubleshoot Splunk performance issues 3: Troubleshoot memory usage 4: Troubleshoot disk space issues
What is the recommended order of activities in the Splunk deployment process?
Options:
Infrastructure Planning and Buildout
Splunk Deployment and Data Enrichment
User Planning and Rollout
User Planning and Rollout
Infrastructure Planning and Buildout
Splunk Deployment and Data Enrichment
Splunk Deployment and Data Enrichment
User Planning and Rollout
Infrastructure Planning and Buildout
Infrastructure Planning and Buildout
User Planning and Rollout
Splunk Deployment and Data Enrichment
Answer:
AExplanation:
Comprehensive and Detailed Explanation (From Splunk Enterprise Documentation)Splunk’s official planning guidance explains that the deployment cycle begins with defining the system architecture, capacity planning, platform design, and topologies. Splunk states that before any component is installed, administrators must complete “infrastructure planning and buildout,” which includes determining indexer capacity, search head roles, clustering strategy, storage layout, and performance requirements. This foundational step ensures that all Splunk components have the proper hardware, network design, and scaling expectations.
After the environment is built, Splunk documentation states that the next stage is “deployment and data onboarding,” which includes configuring indexers, forwarders, parsing rules, event processing pipelines, data source validation, and enrichment steps such as field extractions, tagging, event types, and CIM alignment. Splunk describes this as the phase where you bring in data and confirm correctness, completeness, and normalization.
Only after the system is stable and populated with data does Splunk recommend “user planning and rollout”, which includes developing dashboards, roles, knowledge objects, search best practices, and enabling user access. Splunk emphasizes that user onboarding should occur last, once infrastructure and data pipelines are fully validated.
A customer has a Search Head Cluster (SHC) with site1 and site2. Site1 has five search heads and Site2 has four. Site1 search heads are preferred captains. What action should be taken on Site2 in a network failure between the sites?
Options:
Disable elections and set a static captain, then restart the cluster.
No action is required.
Set a dynamic captain manually and restart.
Disable elections and set a static captain, notifying all members.
Answer:
BExplanation:
Comprehensive and Detailed Explanation (From Splunk Enterprise Documentation)Splunk’s Search Head Clustering documentation explains that the cluster uses a majority-based election system. A captain is elected only when a node sees more than half of the cluster. In a two-site design where site1 has the majority of members, Splunk states that the majority site continues normal operation during a network partition. The minority site (site2) is not allowed to elect a captain and should not promote itself.
Splunk specifically warns administrators not to enable static captain on a minority site during a network split. Doing so creates two independent clusters, leading to configuration divergence and severe data-consistency issues. The documentation emphasizes that static captain should only be used for a complete loss of majority, not for a site partition.
Because Site1 maintains majority, it remains the active cluster and site2 does not perform any actions. Splunk states that minority-site members should simply wait until network communication is restored.
Thus the correct answer is B: No action is required.
(Which Splunk component allows viewing of the LISPY to assist in debugging Splunk searches?)
Options:
dbinspect
Monitoring Console
walklex
Search Job Inspector
Answer:
CExplanation:
The walklex command in Splunk is a specialized administrative search command used to translate and display LISPY (Splunk’s internal representation of search terms). LISPY is the logical search syntax Splunk uses to parse and execute search queries, and examining it helps administrators and developers debug search optimization, field extraction behavior, and index-time search efficiency.
When you run the command | walklex search="your_search_string", Splunk outputs how it tokenizes and interprets that query internally. This is particularly useful for understanding how Splunk’s search language maps to index-time fields and for diagnosing performance issues caused by inefficient search term parsing.
For example:
| walklex search="error OR failure host=server01"
Displays the corresponding LISPY translation used by Splunk’s search subsystem.
Other options are unrelated:
dbinspect provides index bucket metadata.
Monitoring Console shows performance metrics and health status.
Search Job Inspector analyzes search execution phases but doesn’t expose LISPY.
Thus, the correct and Splunk-documented tool for LISPY inspection is the walklex command.
References (Splunk Enterprise Documentation):
• walklex Command Reference – LISPY and Search Debugging
• Understanding Search Language Parsing in Splunk
• Search Internals: How Splunk Interprets Queries
• Splunk Search Performance Troubleshooting Tools
How can internal logging levels in a Splunk environment be changed to troubleshoot an issue? (select all that apply)
Options:
Use the Monitoring Console (MC).
Use Splunk command line.
Use Splunk Web.
Edit log-local. cfg.
Answer:
A, B, C, DExplanation:
Splunk provides various methods to change the internal logging levels in a Splunk environment to troubleshoot an issue. All of the options are valid ways to do so. Option A is correct because the Monitoring Console (MC) allows the administrator to view and modify the logging levels of various Splunk components through a graphical interface. Option B is correct because the Splunk command line provides the splunk set log-level command to change the logging levels of specific components or categories. Option C is correct because the Splunk Web provides the Settings > Server settings > Server logging page to change the logging levels of various components through a web interface. Option D is correct because the log-local.cfg file allows the administrator to manually edit the logging levels of various components by overriding the default settings in the log.cfg file123
1:
What is the expected minimum amount of storage required for data across an indexer cluster with the following input and parameters?
• Raw data = 15 GB per day
• Index files = 35 GB per day
• Replication Factor (RF) = 2
• Search Factor (SF) = 2
Options:
85 GB per day
50 GB per day
100 GB per day
65 GB per day
Answer:
CExplanation:
The correct answer is C. 100 GB per day. This is the expected minimum amount of storage required for data across an indexer cluster with the given input and parameters. The storage requirement can be calculated by adding the raw data size and the index files size, and then multiplying by the Replication Factor and the Search Factor1. In this case, the calculation is:
(15 GB + 35 GB) x 2 x 2 = 100 GB
The Replication Factor is the number of copies of each bucket that the cluster maintains across the set of peer nodes2. The Search Factor is the number of searchable copies of each bucket that the cluster maintains across the set of peer nodes3. Both factors affect the storage requirement, as they determine how many copies of the data are stored and searchable on the indexers. The other options are not correct, as they do not match the result of the calculation. Therefore, option C is the correct answer, and options A, B, and D are incorrect.
1: Estimate storage requirements 2: About indexer clusters and index replication 3: Configure the search factor
When using the props.conf LINE_BREAKER attribute to delimit multi-line events, the SHOULD_LINEMERGE attribute should be set to what?
Options:
Auto
None
True
False
Answer:
DExplanation:
When using the props.conf LINE_BREAKER attribute to delimit multi-line events, the SHOULD_LINEMERGE attribute should be set to false. This tells Splunk not to merge events that have been broken by the LINE_BREAKER. Setting the SHOULD_LINEMERGE attribute to true, auto, or none will cause Splunk to ignore the LINE_BREAKER and merge events based on other criteria. For more information, see Configure event line breaking in the Splunk documentation.
A monitored log file is changing on the forwarder. However, Splunk searches are not finding any new data that has been added. What are possible causes? (select all that apply)
Options:
An admin ran splunk clean eventdata -index
An admin has removed the Splunk fishbucket on the forwarder.
The last 256 bytes of the monitored file are not changing.
The first 256 bytes of the monitored file are not changing.
Answer:
B, CExplanation:
A monitored log file is changing on the forwarder, but Splunk searches are not finding any new data that has been added. This could be caused by two possible reasons: B. An admin has removed the Splunk fishbucket on the forwarder. C. The last 256 bytes of the monitored file are not changing. Option B is correct because the Splunk fishbucket is a directory that stores information about the files that have been monitored by Splunk, such as the file name, size, modification time, and CRC checksum. If an admin removes the fishbucket, Splunk will lose track of the files that have been previously indexed and will not index any new data from those files. Option C is correct because Splunk uses the CRC checksum of the last 256 bytes of a monitored file to determine if the file has changed since the last time it was read. If the last 256 bytes of the file are not changing, Splunk will assume that the file is unchanged and will not index any new data from it. Option A is incorrect because running the splunk clean eventdata -index
1:
(When determining where a Splunk forwarder is trying to send data, which of the following searches can provide assistance?)
Options:
index=_internal sourcetype=internal metrics destHost | dedup destHost
index=_internal sourcetype=splunkd metrics inputHost | dedup inputHost
index=_metrics sourcetype=splunkd metrics destHost | dedup destHost
index=_internal sourcetype=splunkd metrics destHost | dedup destHost
Answer:
DExplanation:
To determine where a Splunk forwarder is attempting to send its data, administrators can search within the _internal index using the metrics logs generated by the forwarder’s Splunkd process. The correct and documented search is:
index=_internal sourcetype=splunkd metrics destHost | dedup destHost
The _internal index contains detailed operational logs from the Splunkd process, including metrics on network connections, indexing pipelines, and output groups. The field destHost records the destination indexer(s) to which the forwarder is attempting to send data. Using dedup destHost ensures that only unique destination hosts are shown.
This search is particularly useful for troubleshooting forwarding issues, such as connection failures, misconfigurations in outputs.conf, or load-balancing behavior in multi-indexer setups.
Other listed options are invalid or incorrect because:
sourcetype=internal does not exist.
index=_metrics is not where Splunk stores forwarding telemetry.
The field inputHost identifies the source host, not the destination.
Thus, Option D aligns with Splunk’s official troubleshooting practices for forwarder-to-indexer communication validation.
References (Splunk Enterprise Documentation):
• Monitoring Forwarder Connections and Destinations
• Troubleshooting Forwarding Using Internal Logs
• _internal Index Reference – Metrics and destHost Fields
• outputs.conf – Verifying Forwarder Data Routing and Connectivity
The KV store forms its own cluster within a SHC. What is the maximum number of SHC members KV store will form?
Options:
25
50
100
Unlimited
Answer:
BExplanation:
The KV store forms its own cluster within a SHC. The maximum number of SHC members KV store will form is 50. The KV store cluster is a subset of the SHC members that are responsible for replicating and storing the KV store data. The KV store cluster can have up to 50 members, but only 20 of them can be active at any given time. The other members are standby members that can take over if an active member fails. The KV store cluster cannot have more than 50 members, nor can it have an unlimited number of members. The KV store cluster cannot have 25 or 100 members, because these numbers are not multiples of 5, which is the minimum replication factor for the KV store cluster
(What is a recommended way to improve search performance?)
Options:
Use the shortest query possible.
Filter as much as possible in the initial search.
Use non-streaming commands as early as possible.
Leverage the not expression to limit returned results.
Answer:
BExplanation:
Splunk Enterprise Search Optimization documentation consistently emphasizes that filtering data as early as possible in the search pipeline is the most effective way to improve search performance. The base search (the part before the first pipe |) determines the volume of raw events Splunk retrieves from the indexers. Therefore, by applying restrictive conditions early—such as time ranges, indexed fields, and metadata filters—you can drastically reduce the number of events that need to be fetched and processed downstream.
The best practice is to use indexed field filters (e.g., index=security sourcetype=syslog host=server01) combined with search or where clauses at the start of the query. This minimizes unnecessary data movement between indexers and the search head, improving both search speed and system efficiency.
Using non-streaming commands early (Option C) can degrade performance because they require full result sets before producing output. Likewise, focusing solely on shortening queries (Option A) or excessive use of the not operator (Option D) does not guarantee efficiency, as both may still process large datasets.
Filtering early leverages Splunk’s distributed search architecture to limit data at the indexer level, reducing processing load and network transfer.
References (Splunk Enterprise Documentation):
• Search Performance Tuning and Optimization Guide
• Best Practices for Writing Efficient SPL Queries
• Understanding Streaming and Non-Streaming Commands
• Search Job Inspector: Analyzing Execution Costs
A Splunk instance has the following settings in SPLUNK_HOME/etc/system/local/server.conf:
[clustering]
mode = master
replication_factor = 2
pass4SymmKey = password123
Which of the following statements describe this Splunk instance? (Select all that apply.)
Options:
This is a multi-site cluster.
This cluster's search factor is 2.
This Splunk instance needs to be restarted.
This instance is missing the master_uri attribute.
Answer:
C, DExplanation:
The Splunk instance with the given settings in SPLUNK_HOME/etc/system/local/server.conf is missing the master_uri attribute and needs to be restarted. The master_uri attribute is required for the master node to communicate with the peer nodes and the search head cluster. The master_uri attribute specifies the host name and port number of the master node. Without this attribute, the master node cannot function properly. The Splunk instance also needs to be restarted for the changes in the server.conf file to take effect. The replication_factor setting determines how many copies of each bucket are maintained across the peer nodes. The search factor is a separate setting that determines how many searchable copies of each bucket are maintained across the peer nodes. The search factor is not specified in the given settings, so it defaults to the same value as the replication factor, which is 2. This is not a multi-site cluster, because the site attribute is not specified in the clustering stanza. A multi-site cluster is a cluster that spans multiple geographic locations, or sites, and has different replication and search factors for each site.
(What command will decommission a search peer from an indexer cluster?)
Options:
splunk disablepeer --enforce-counts
splunk decommission —enforce-counts
splunk offline —enforce-counts
splunk remove cluster-peers —enforce-counts
Answer:
CExplanation:
The splunk offline --enforce-counts command is the official and documented method used to gracefully decommission a search peer (indexer) from an indexer cluster in Splunk Enterprise. This command ensures that all replication and search factors are maintained before the peer is removed.
When executed, Splunk initiates a controlled shutdown process for the peer node. The Cluster Manager verifies that sufficient replicated copies of all bucket data exist across the remaining peers according to the configured replication_factor (RF) and search_factor (SF). The --enforce-counts flag specifically enforces that replication and search counts remain intact before the peer fully detaches from the cluster, ensuring no data loss or availability gap.
The sequence typically includes:
Validating cluster state and replication health.
Rolling off the peer’s data responsibilities to other peers.
Removing the peer from the active cluster membership list once replication is complete.
Other options like disablepeer, decommission, or remove cluster-peers are not valid Splunk commands. Therefore, the correct documented method is to use:
splunk offline --enforce-counts
References (Splunk Enterprise Documentation):
• Indexer Clustering: Decommissioning a Peer Node
• Managing Peer Nodes and Maintaining Data Availability
• Splunk CLI Command Reference – splunk offline
• Cluster Manager and Peer Maintenance Procedures
When Splunk is installed, where are the internal indexes stored by default?
Options:
SPLUNK_HOME/bin
SPLUNK_HOME/var/lib
SPLUNK_HOME/var/run
SPLUNK_HOME/etc/system/default
Answer:
BExplanation:
Splunk internal indexes are the indexes that store Splunk’s own data, such as internal logs, metrics, audit events, and configuration snapshots. By default, Splunk internal indexes are stored in the SPLUNK_HOME/var/lib/splunk directory, along with other user-defined indexes. The SPLUNK_HOME/bin directory contains the Splunk executable files and scripts. The SPLUNK_HOME/var/run directory contains the Splunk process ID files and lock files. The SPLUNK_HOME/etc/system/default directory contains the default Splunk configuration files.
The master node distributes configuration bundles to peer nodes. Which directory peer nodes receive the bundles?
Options:
apps
deployment-apps
slave-apps
master-apps
Answer:
CExplanation:
The master node distributes configuration bundles to peer nodes in the slave-apps directory under $SPLUNK_HOME/etc. The configuration bundle method is the only supported method for managing common configurations and app deployment across the set of peers. It ensures that all peers use the same versions of these files1. Bundles typically contain a subset of files (configuration files and assets) from $SPLUNK_HOME/etc/system, $SPLUNK_HOME/etc/apps, and $SPLUNK_HOME/etc/users2. The process of distributing knowledge bundles means that peers by default receive nearly the entire contents of the search head’s apps3.
Which of the following would be the least helpful in troubleshooting contents of Splunk configuration files?
Options:
crash logs
search.log
btool output
diagnostic logs
Answer:
AExplanation:
Splunk configuration files are files that contain settings that control various aspects of Splunk behavior, such as data inputs, outputs, indexing, searching, clustering, and so on1. Troubleshooting Splunk configuration files involves identifying and resolving issues that affect the functionality or performance of Splunk due to incorrect or conflicting configuration settings. Some of the tools and methods that can help with troubleshooting Splunk configuration files are:
search.log: This is a file that contains detailed information about the execution of a search, such as the search pipeline, the search commands, the search results, the search errors, and the search performance2. This file can help troubleshoot issues related to search configuration, such as props.conf, transforms.conf, macros.conf, and so on3.
btool output: This is a command-line tool that displays the effective configuration settings for a given Splunk component, such as inputs, outputs, indexes, props, and so on4. This tool can help troubleshoot issues related to configuration precedence, inheritance, and merging, as well as identify the source of a configuration setting5.
diagnostic logs: These are files that contain information about the Splunk system, such as the Splunk version, the operating system, the hardware, the license, the indexes, the apps, the users, the roles, the permissions, the configuration files, the log files, and the metrics6. These files can help troubleshoot issues related to Splunk installation, deployment, performance, and health7.
Option A is the correct answer because crash logs are the least helpful in troubleshooting Splunk configuration files. Crash logs are files that contain information about the Splunk process when it crashes, such as the stack trace, the memory dump, and the environment variables8. These files can help troubleshoot issues related to Splunk stability, reliability, and security, but not necessarily related to Splunk configuration9.
Which index-time props.conf attributes impact indexing performance? (Select all that apply.)
Options:
REPORT
LINE_BREAKER
ANNOTATE_PUNCT
SHOULD_LINEMERGE
Answer:
B, DExplanation:
The index-time props.conf attributes that impact indexing performance are LINE_BREAKER and SHOULD_LINEMERGE. These attributes determine how Splunk breaks the incoming data into events and whether it merges multiple events into one. These operations can affect the indexing speed and the disk space consumption. The REPORT attribute does not impact indexing performance, as it is used to apply transforms at search time. The ANNOTATE_PUNCT attribute does not impact indexing performance, as it is used to add punctuation metadata to events at search time. For more information, see [About props.conf and transforms.conf] in the Splunk documentation.
Which of the following should be done when installing Enterprise Security on a Search Head Cluster? (Select all that apply.)
Options:
Install Enterprise Security on the deployer.
Install Enterprise Security on a staging instance.
Copy the Enterprise Security configurations to the deployer.
Use the deployer to deploy Enterprise Security to the cluster members.
Answer:
A, DExplanation:
When installing Enterprise Security on a Search Head Cluster (SHC), the following steps should be done: Install Enterprise Security on the deployer, and use the deployer to deploy Enterprise Security to the cluster members. Enterprise Security is a premium app that provides security analytics and monitoring capabilities for Splunk. Enterprise Security can be installed on a SHC by using the deployer, which is a standalone instance that distributes apps and other configurations to the SHC members. Enterprise Security should be installed on the deployer first, and then deployed to the cluster members using the splunk apply shcluster-bundle command. Enterprise Security should not be installed on a staging instance, because a staging instance is not part of the SHC deployment process. Enterprise Security configurations should not be copied to the deployer, because they are already included in the Enterprise Security app package.
To improve Splunk performance, parallelIngestionPipelines setting can be adjusted on which of the following components in the Splunk architecture? (Select all that apply.)
Options:
Indexers
Forwarders
Search head
Cluster master
Answer:
A, BExplanation:
The parallelIngestionPipelines setting can be adjusted on the indexers and forwarders to improve Splunk performance. The parallelIngestionPipelines setting determines how many concurrent data pipelines are used to process the incoming data. Increasing the parallelIngestionPipelines setting can improve the data ingestion and indexing throughput, especially for high-volume data sources. The parallelIngestionPipelines setting can be adjusted on the indexers and forwarders by editing the limits.conf file. The parallelIngestionPipelines setting cannot be adjusted on the search head or the cluster master, because they are not involved in the data ingestion and indexing process.
Which of the following server. conf stanzas indicates the Indexer Discovery feature has not been fully configured (restart pending) on the Master Node?
A)

B)

C)

D)
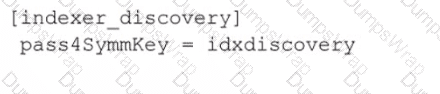
Options:
Option A
Option B
Option C
Option D
Answer:
AExplanation:
The Indexer Discovery feature enables forwarders to dynamically connect to the available peer nodes in an indexer cluster. To use this feature, the manager node must be configured with the [indexer_discovery] stanza and a pass4SymmKey value. The forwarders must also be configured with the same pass4SymmKey value and the master_uri of the manager node. The pass4SymmKey value must be encrypted using the splunk _encrypt command. Therefore, option A indicates that the Indexer Discovery feature has not been fully configured on the manager node, because the pass4SymmKey value is not encrypted. The other options are not related to the Indexer Discovery feature. Option B shows the configuration of a forwarder that is part of an indexer cluster. Option C shows the configuration of a manager node that is part of an indexer cluster. Option D shows an invalid configuration of the [indexer_discovery] stanza, because the pass4SymmKey value is not encrypted and does not match the forwarders’ pass4SymmKey value12
1:
Which Splunk component is mandatory when implementing a search head cluster?
Options:
Captain Server
Deployer
Cluster Manager
RAFT Server
Answer:
BExplanation:
This is a mandatory Splunk component when implementing a search head cluster, as it is responsible for distributing the configuration updates and app bundles to the cluster members1. The deployer is a separate instance that communicates with the cluster manager and pushes the changes to the search heads1. The other options are not mandatory components for a search head cluster. Option A, Captain Server, is not a component, but a role that is dynamically assigned to one of the search heads in the cluster2. The captain coordinates the replication and search activities among the cluster members2. Option C, Cluster Manager, is a component for an indexer cluster, not a search head cluster3. The cluster manager manages the replication and search factors, and provides a web interface for monitoring and managing the indexer cluster3. Option D, RAFT Server, is not a component, but a protocol that is used by the search head cluster to elect the captain and maintain the cluster state4. Therefore, option B is the correct answer, and options A, C, and D are incorrect.
1: Use the deployer to distribute apps and configuration updates 2: About the captain 3: About the cluster manager 4: How a search head cluster works
